Multimodal AI ChatBot for YouTube Video
تفاصيل العمل






From-Tube-to-Thought – AI-Powered YouTube Assistant
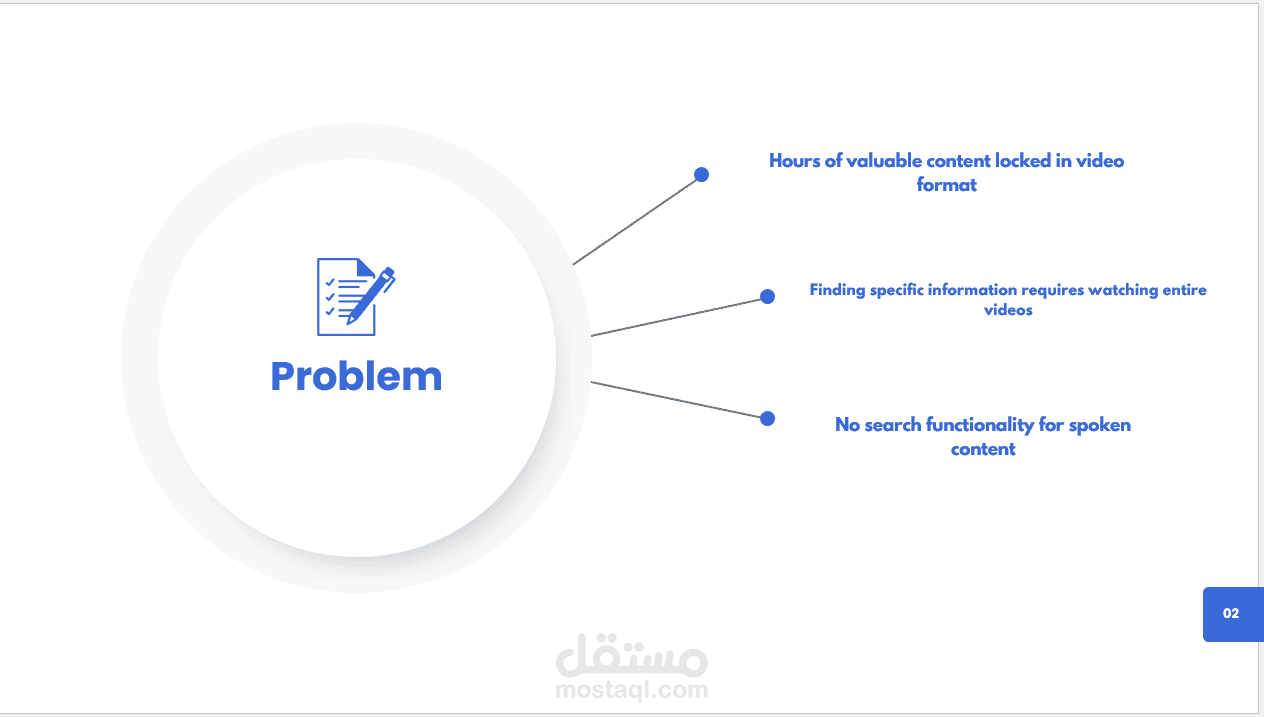
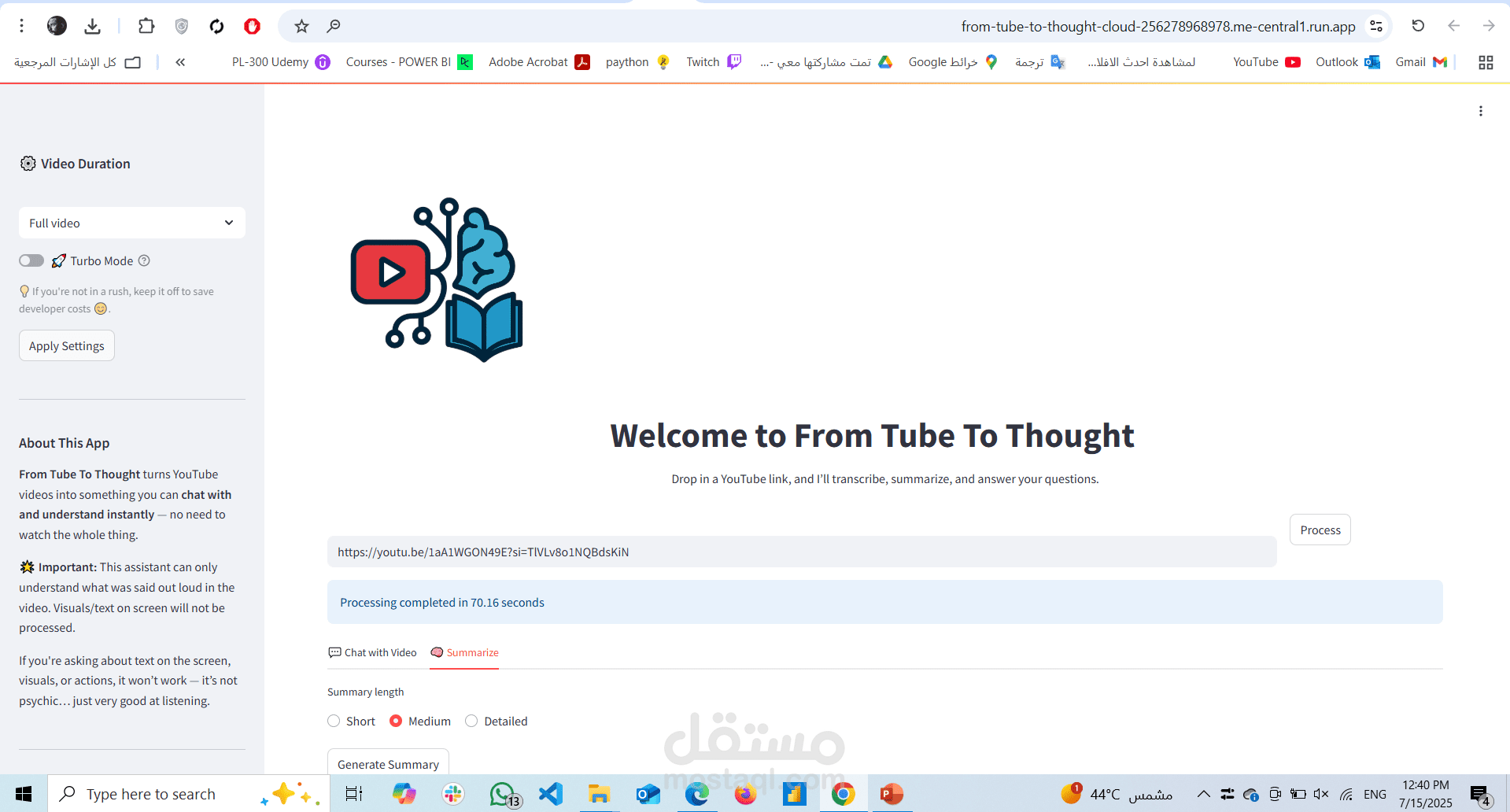
From-Tube-to-Thought is a multimodal AI-powered YouTube assistant that uses advanced Natural Language Processing (NLP) and speech-to-text technology to help users interact with video content conversationally. The system enables users to ask questions, extract key insights, and generate summaries directly from YouTube videos—transforming passive viewing into an intelligent, searchable experience.
Built as part of the AI Engineering Bootcamp (Saudi Digital Academy), this project showcases the integration of language models, speech recognition, and large-scale video content processing into a seamless user assistant.
Objectives:
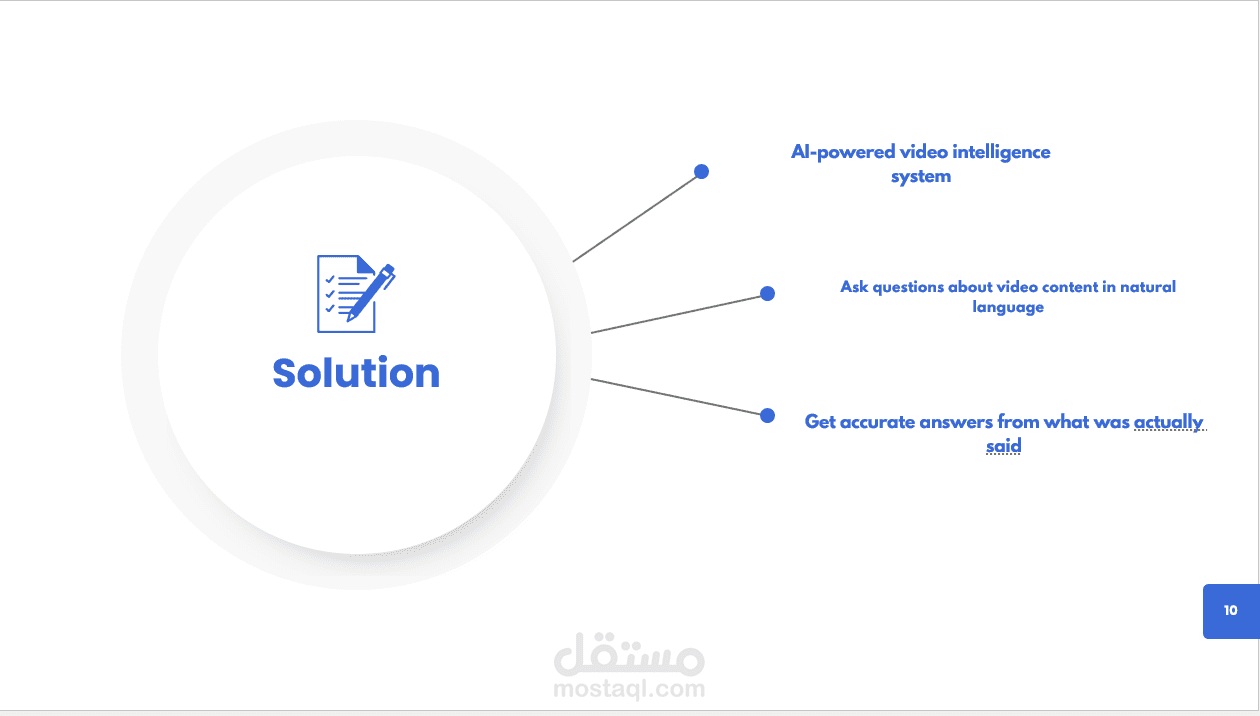
Convert unstructured YouTube video content into interactive, queryable data.
Enable users to ask questions and extract highlights via chat interface.
Summarize video content using generative AI.
Improve accessibility, productivity, and content comprehension for viewers.
Key Features:
Speech-to-Text with Whisper
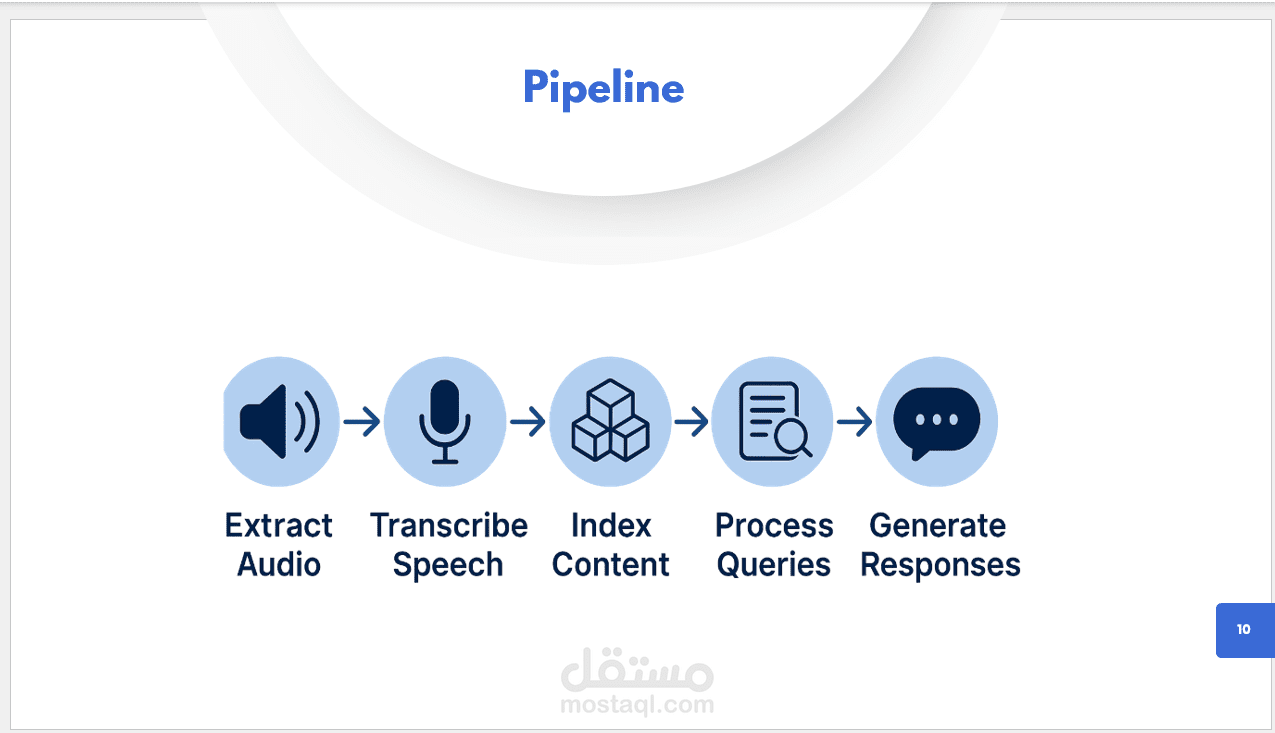
Extracts audio from YouTube videos and transcribes it using OpenAI’s Whisper model.
Supports multi-language transcription and noisy audio environments.
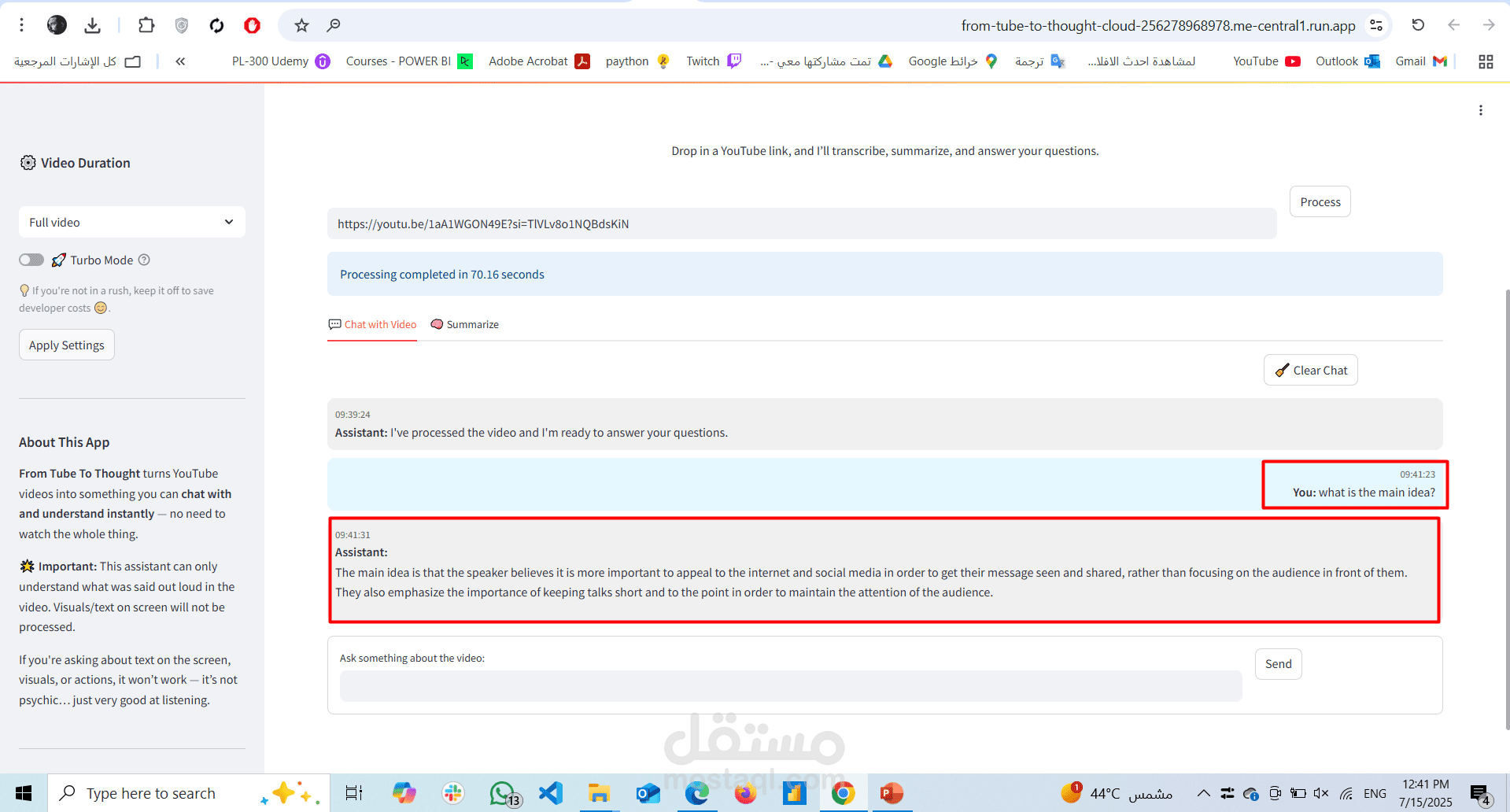
NLP-Powered Q&A
Converts transcriptions into semantic chunks using sentence embeddings.
Enables natural language querying using OpenAI GPT-3.5/4 or LangChain pipelines.
Retrieves relevant segments and generates context-aware answers.
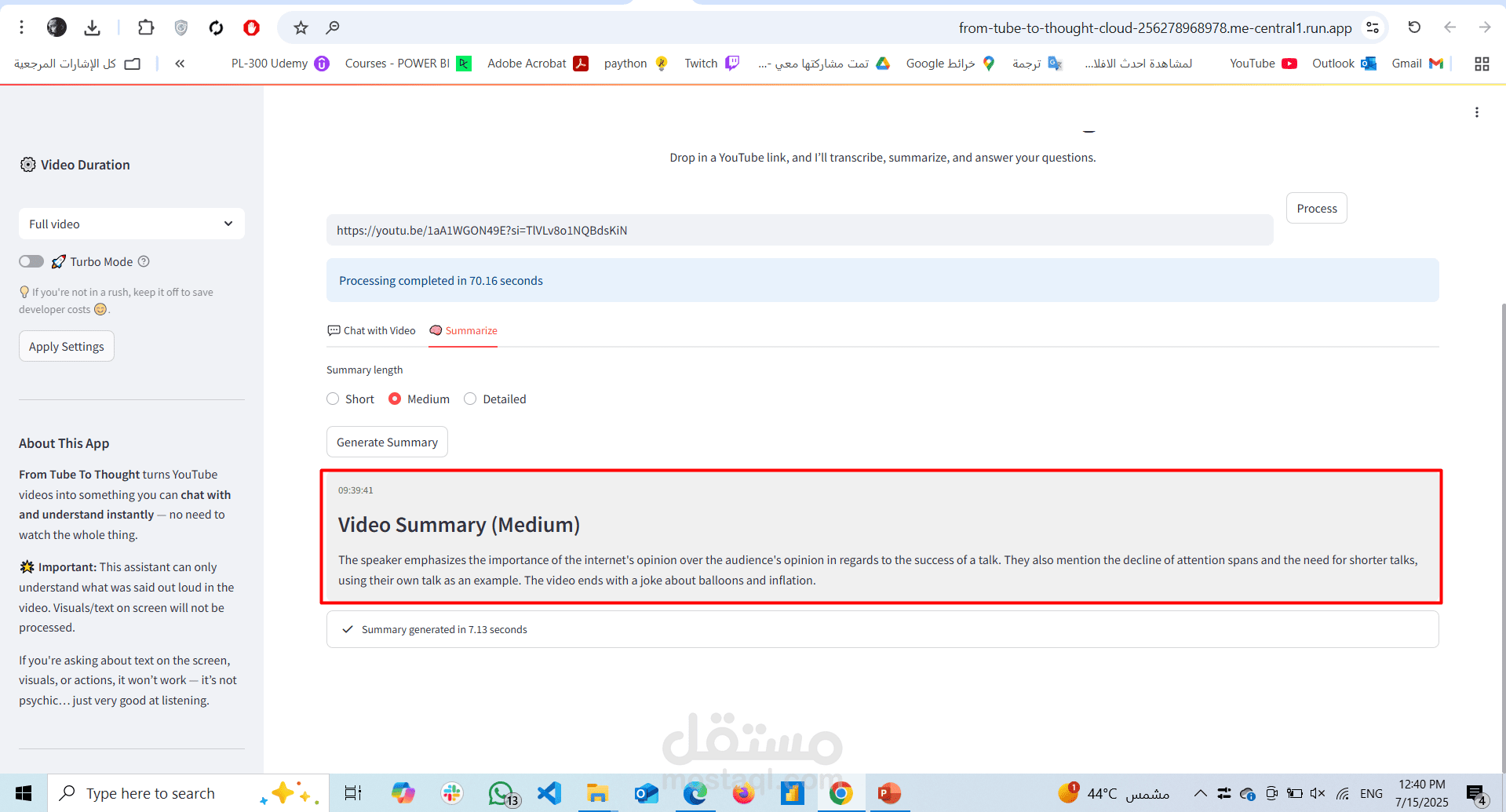
Video Summarization
Uses generative AI to produce summaries in paragraph or bullet-point format.
Offers topic overviews, key highlights, and timestamps.
Streamlit-Based Web App
Clean UI for uploading YouTube links, asking questions, and viewing responses.
Asynchronous backend using FastAPI for speed and responsiveness.
List of tools and technologies:
Programming Language: Python
Speech Recognition: Whisper (OpenAI)
NLP & LLMs: OpenAI GPT-3.5/4, LangChain, HuggingFace Transformers
Text Chunking & Retrieval: LangChain, SentenceTransformers, FAISS / ChromaDB
Frameworks: Streamlit (frontend), FastAPI (backend), asyncio (concurrency)
Data Handling: pandas, NumPy
Video Processing: pytube, moviepy, ffmpeg-python
Vector Databases: ChromaDB, FAISS (for semantic search)
APIs: OpenAI API, Hugging Face
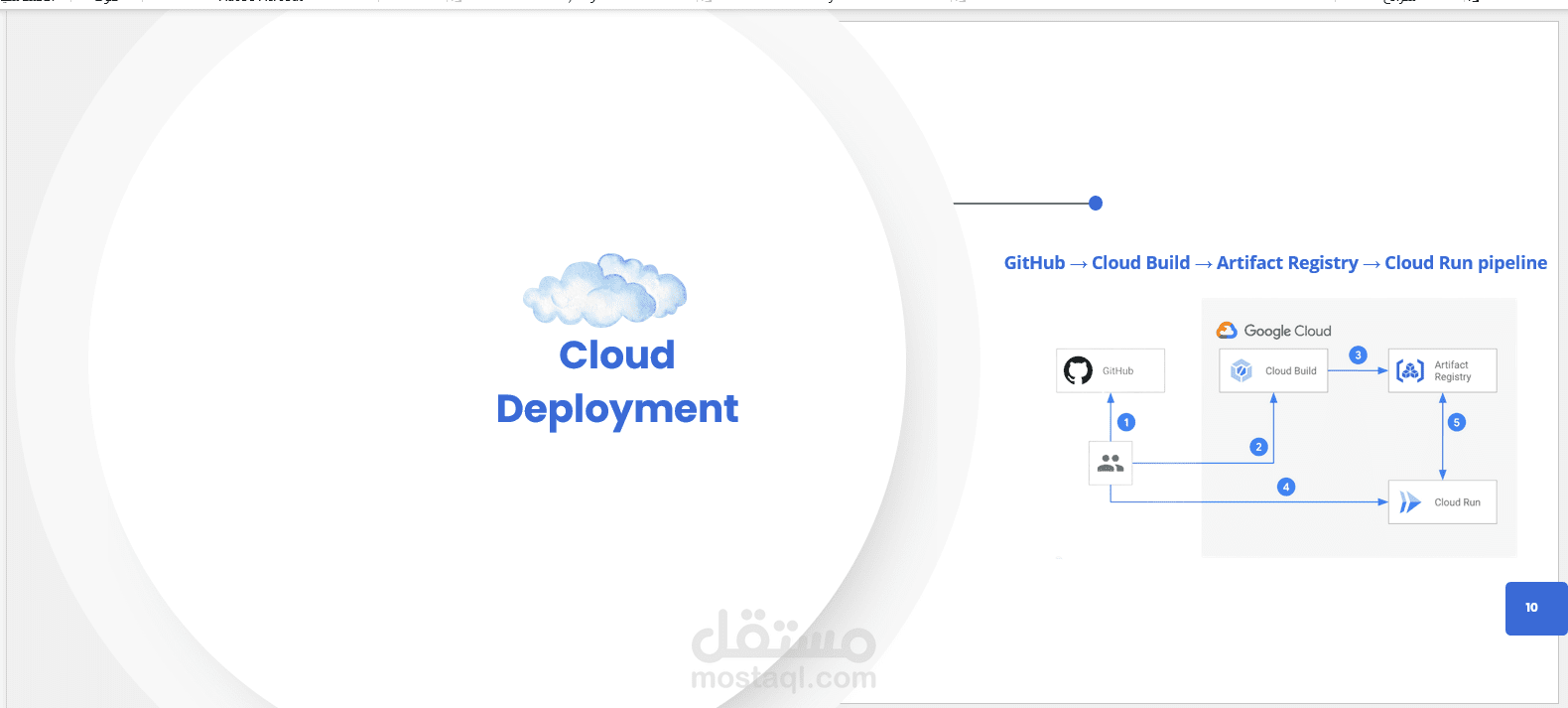
Model Deployment: Google Cloud Run
Version Control: Git, GitHub