group activity recognition
تفاصيل العمل
• This project is a reproduction and extension of a highly cited CVPR 2016 paper titled “A Hierarchical Deep Temporal
Model for Group Activity Recognition”. The paper presents a deep learning approach for understanding group activities
in videos by modeling both individual and collective behavior over time. My work revisits this architecture using modern
tools (e.g., PyTorch) and further enhances it with new insights, experiments, and implementation improvements This
project aims to build a deep learning pipeline that: Frist we Recognizes individual actions from video frames (e.g.,
spiking, standing) then move to to aggregates these actions to infer group-level activities (e.g., right team winning a
point) , in the end uses temporal modeling (via LSTM/GRU) to learn motion and behavior patterns over time. for this
project we used the Volleyball Dataset introduced in the CVPR paper that have 55 volleyball videos (from YouTube),
handpicked and annotated separated in 4830 frames were manually labeled :
1. 9 player actions: e.g., Waiting, Spiking, Digging, Blocking, Standing.
2. 8 team activities: e.g., Left Pass, Right Set, Left Spike, Right Winpoint.
3. Each frame is represented with bounding boxes for all visible players.
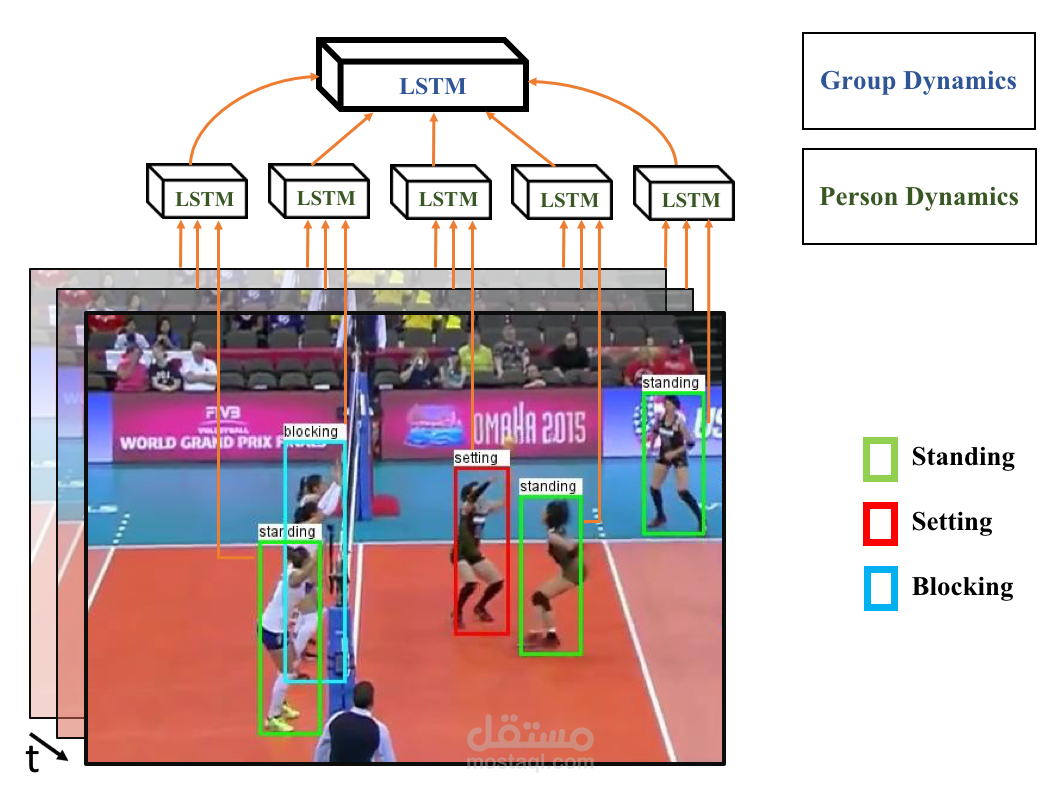
The model employs a hierarchical temporal structure that captures both individual and group dynamics over time. First,
spatial features are extracted from each player’s cropped bounding box using a pretrained ResNet-50. These features,
collected across consecutive frames, are input into an LSTM to model the temporal behavior of each player, followed by a
classifier that predicts the player’s action at every frame. Then, the LSTM outputs for all players in a given frame are
pooled (e.g., max-pooled) to form a scene-level representation. Players are organized into two teams (left and right), and
team-wise pooling is applied to maintain spatial and group-specific information. The concatenated team-level features
are processed by a second LSTM to capture the temporal evolution of group behaviors, culminating in a final classifier
that predicts the overall group activity at each frame. Baselines and Ablation Studies
To better understand the contributions of each model component, I implemented several baselines, inspired by the CVPR
and extended work: The baselines for group activity recognition include several approaches with varying levels of
complexity. Baseline B1 is a naive method that uses a single frame per clip, fine-tuning a ResNet-50 to classify the frame
into one of 8 group activity classes, without any temporal or individual modeling. Baseline B3 improves on this by
training a ResNet-50 for individual action classification; during inference, person-level features are extracted and
max-pooled across all players to classify the overall scene activity. Baseline B4 incorporates temporal context by using
sequences of 9 consecutive frames per clip, extracting image-level features via B1, and feeding these to an LSTM.
Baseline B5 advances temporal modeling by applying an LSTM to sequences of each player’s cropped bounding box
features, then representing the clip through max-pooled player features for classification. Baselines B7 and B8 propose a
full two-stage temporal model: B7 applies a player-level LSTM followed by frame-level pooling and an LSTM for final
scene classification, while B8 extends this by pooling player features separately for each team (left/right) and
concatenating these team features for scene-level modeling. Finally, baseline B9 offers a unified model that jointly trains
for individual and group-level outputs with shared parameters, replaces LSTMs with GRUs, and uses a smaller
ResNet-34 backbone to reduce model size and overfitting, allowing end-to-end backpropagation for better optimization.
Quantitative evaluations across these baselines revealed the benefits of temporal modeling, team-wise pooling, and
unified loss functions for improving group activity recognition performance.