حاله قرض
تفاصيل العمل
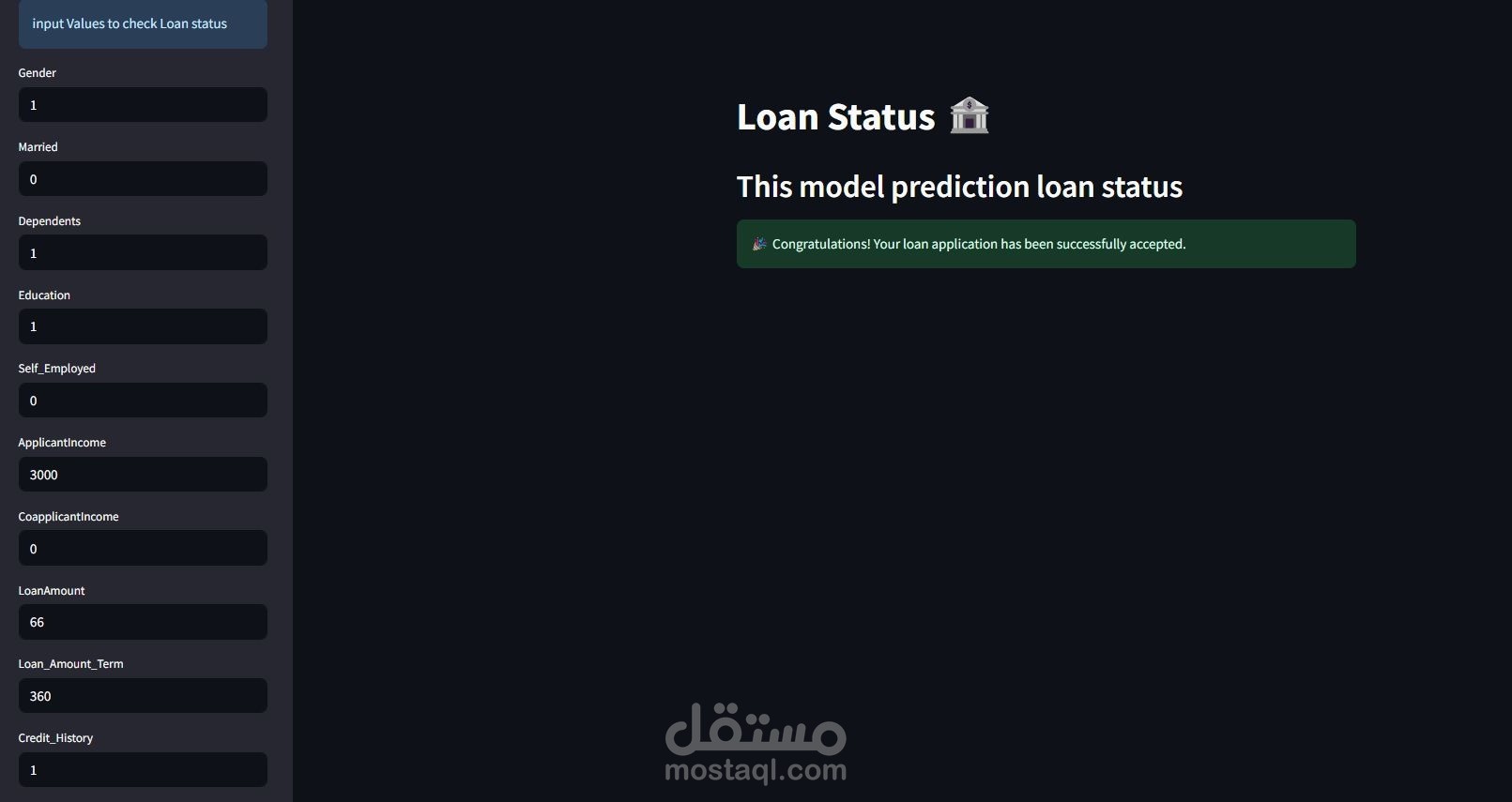
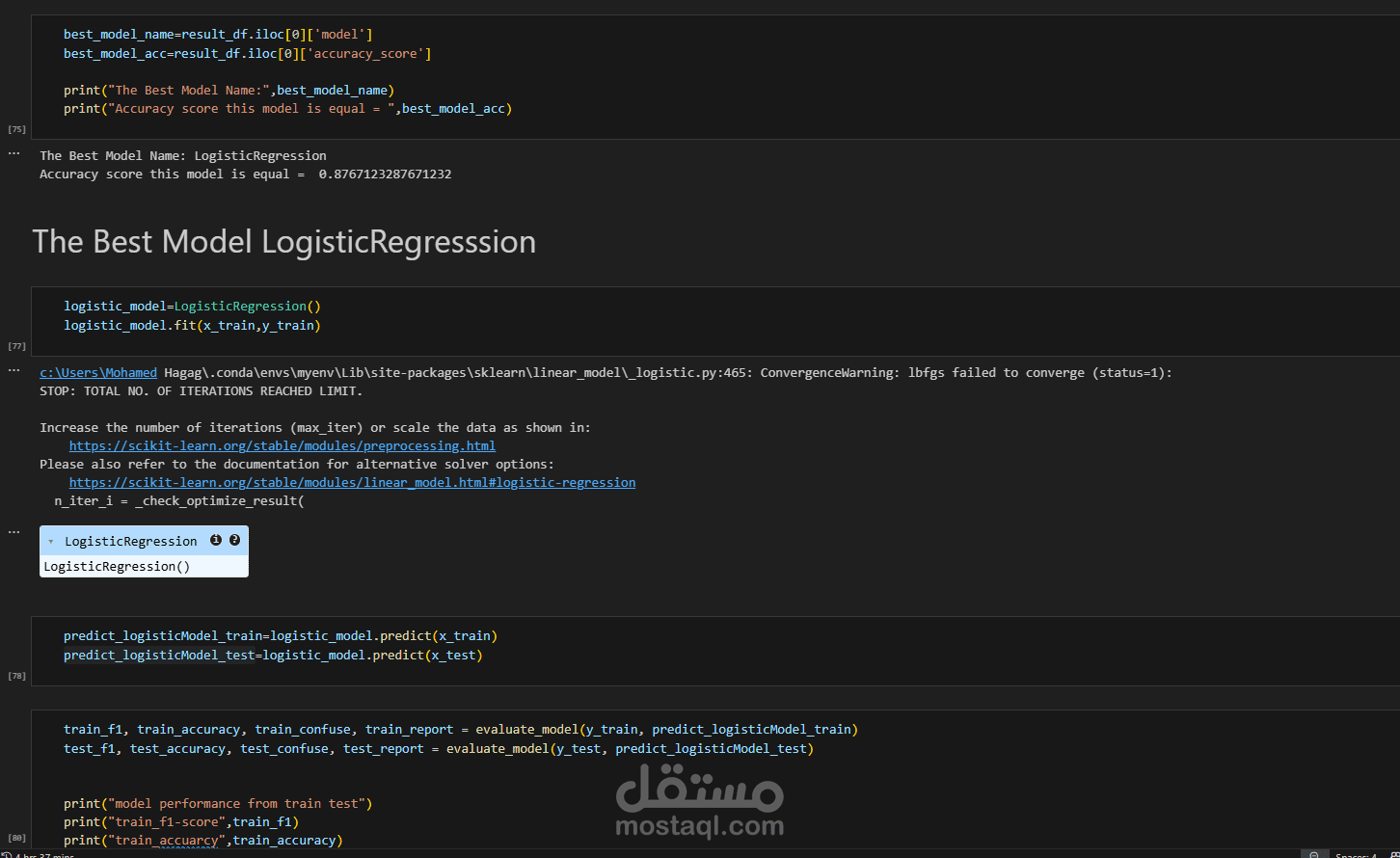
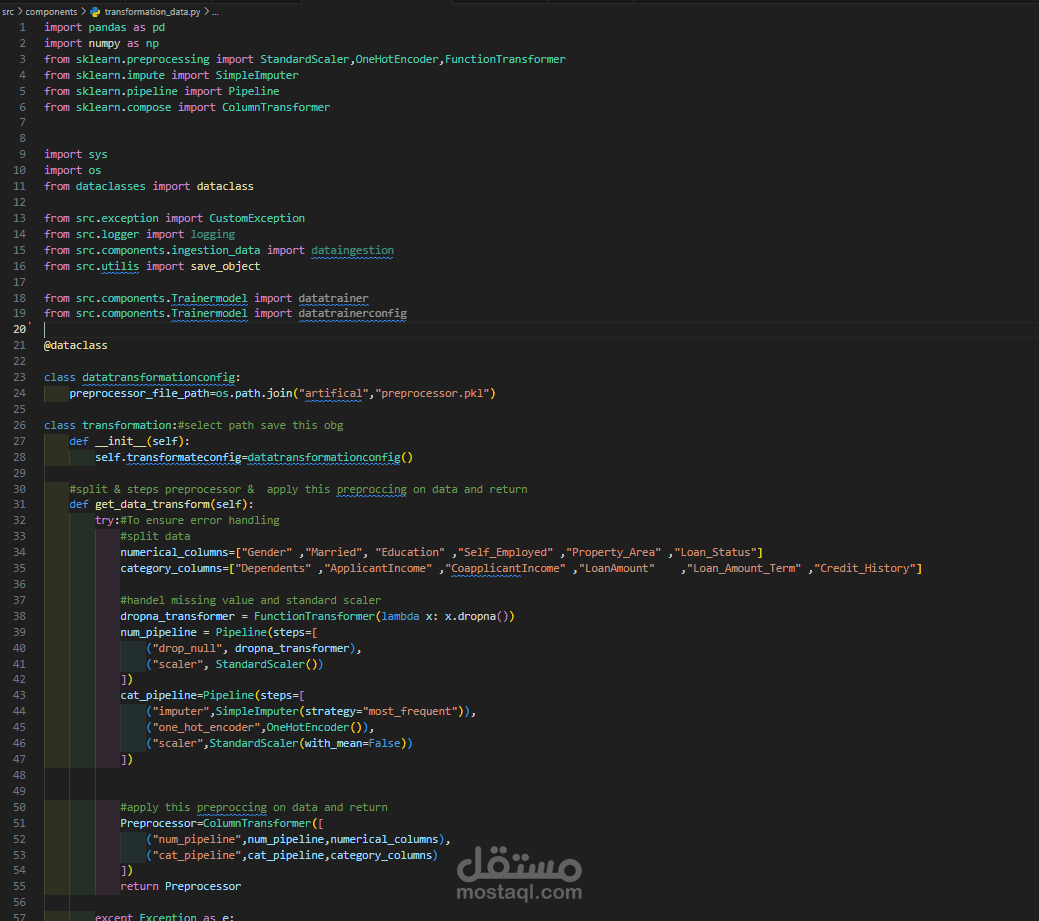
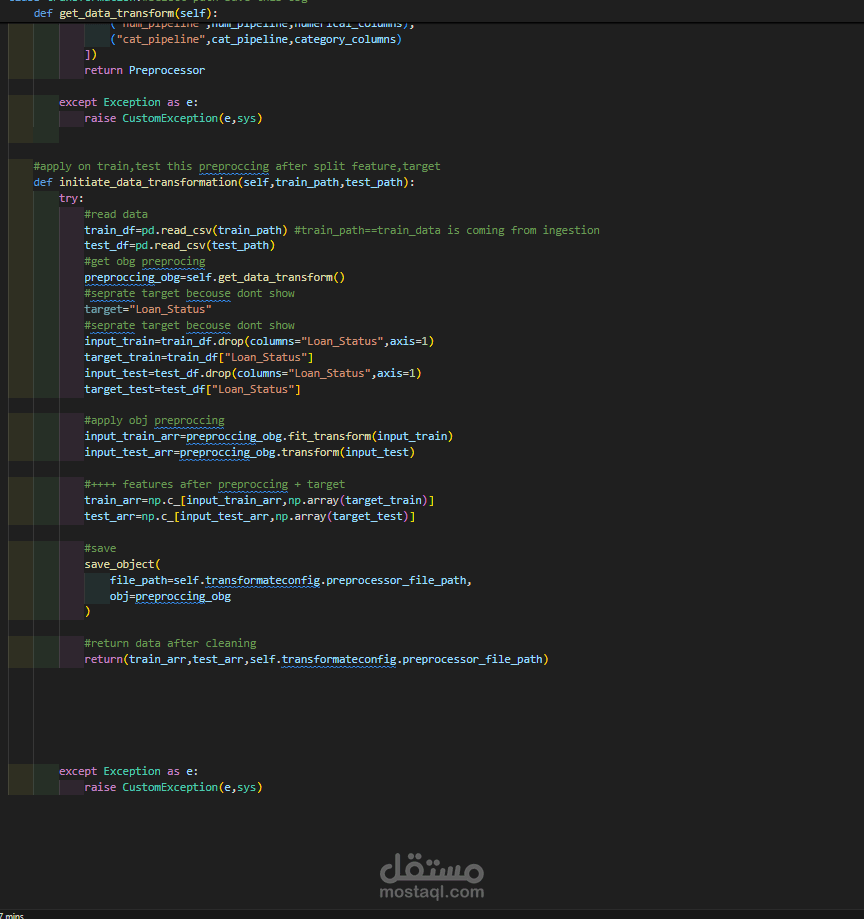
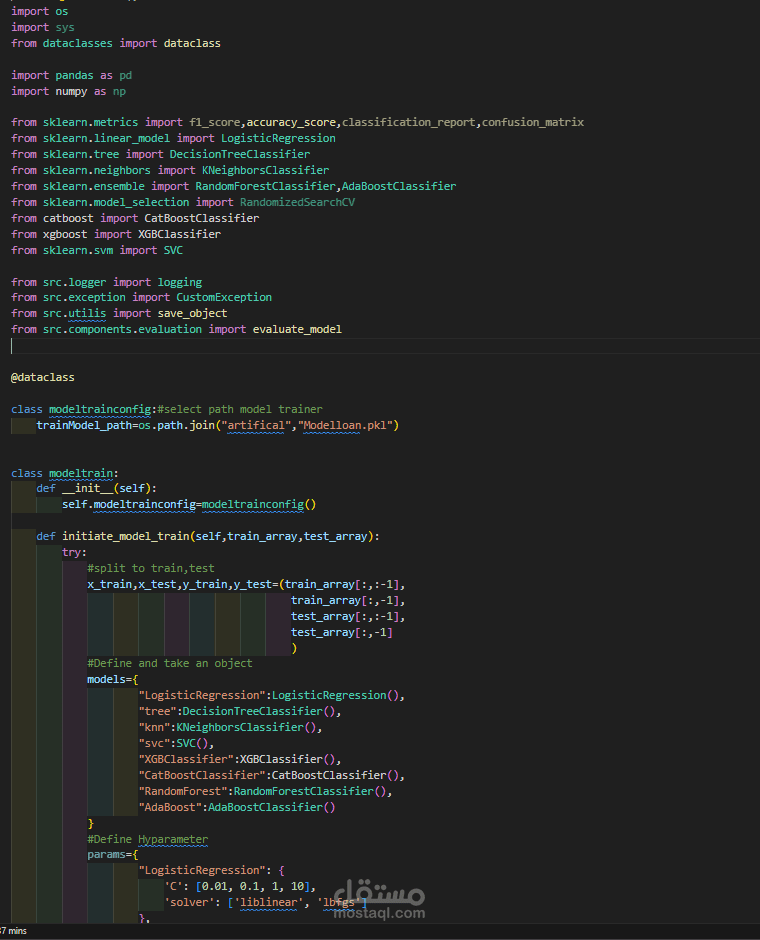
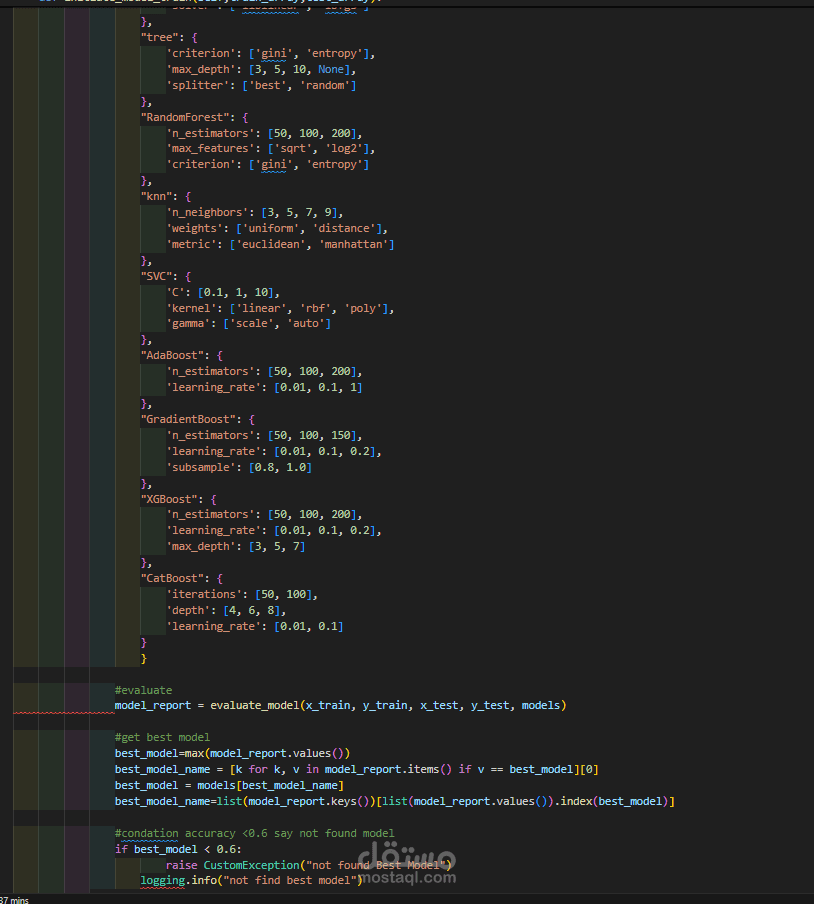
و انا صاحب بنك و حد مقدم علي قرض فبتالي هكون عاوز اعرف مين يستحق ومين لايستحق فمن خلال الموديل دا هيتوقع مين الذي يستحق .
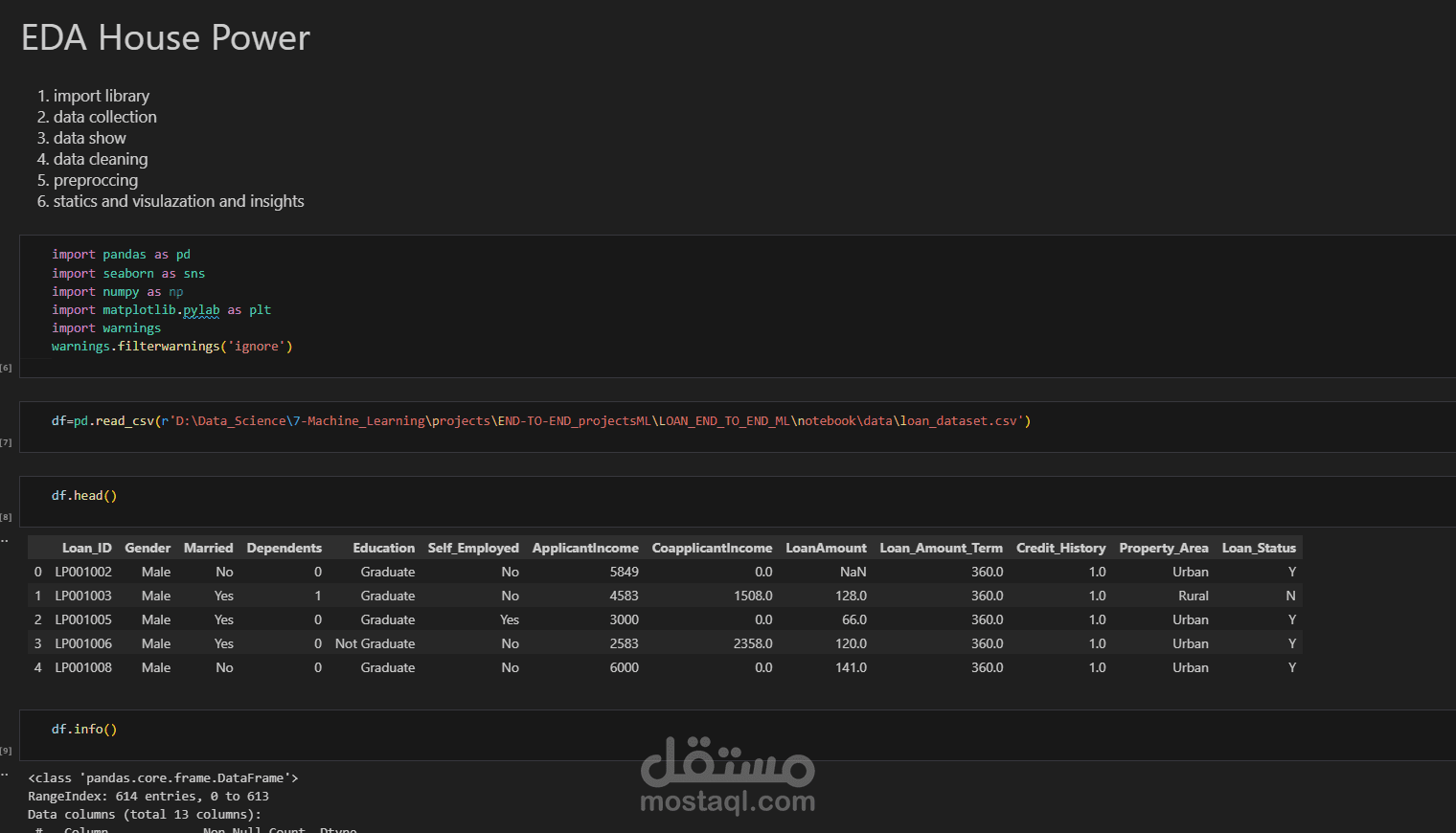
استيراد البيانات وفهمها (Data Understanding):
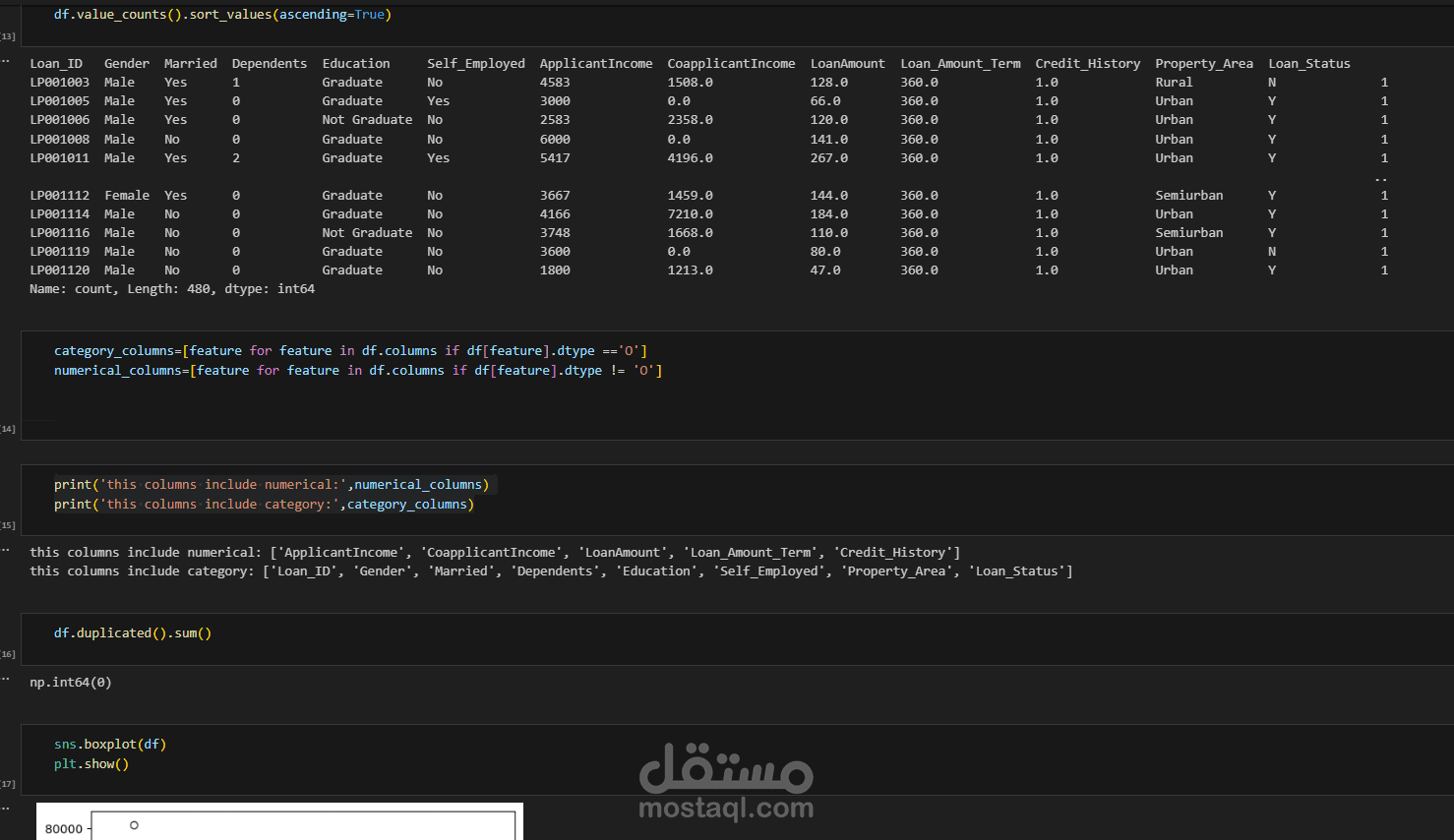
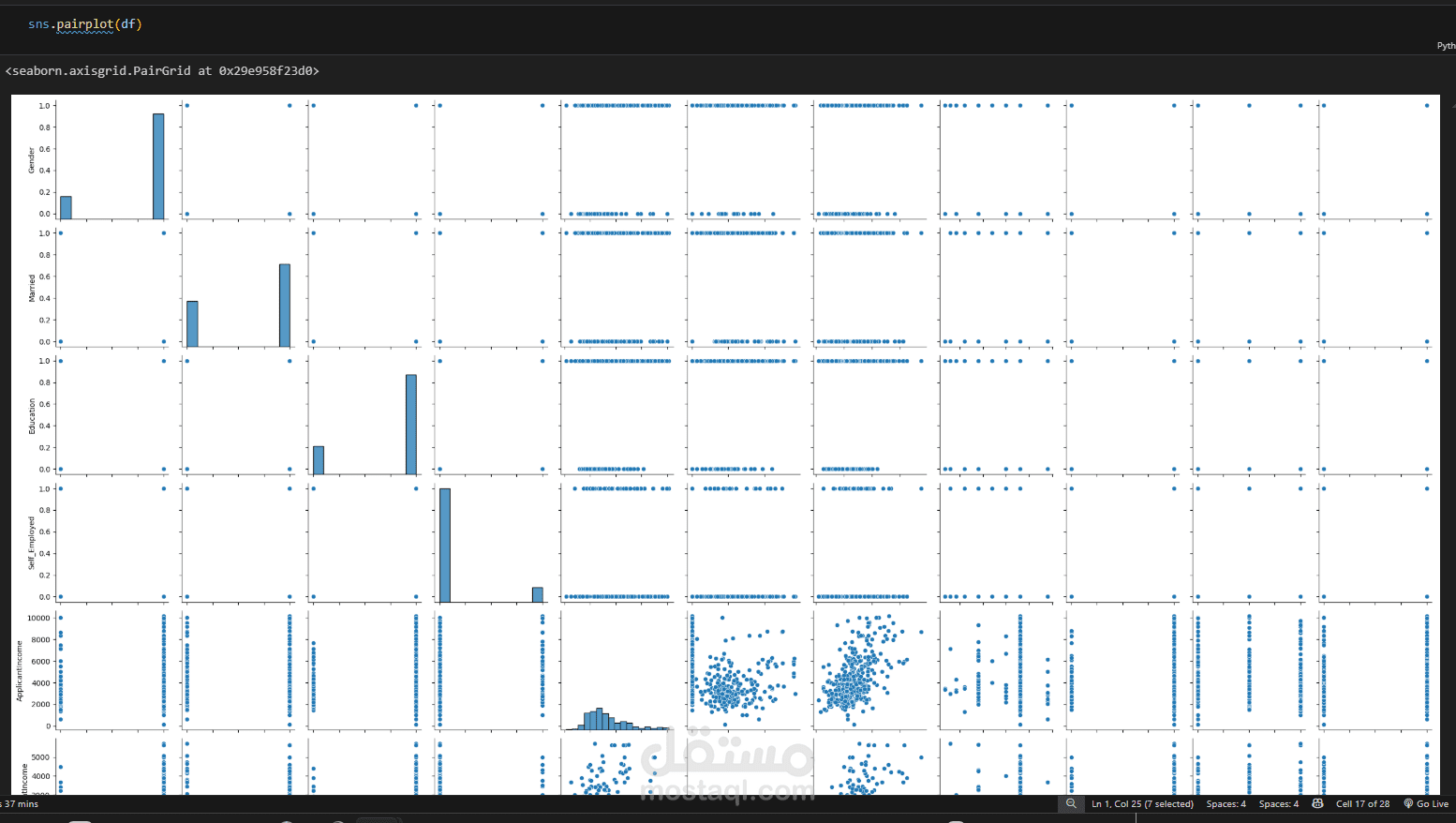
تحليل أولي للبيانات باستخدام Pandas وSeaborn.
دراسة المتغيرات المؤثرة مثل: الدخل، عدد المعالين، نوع العمل، الحالة الاجتماعية، إلخ.
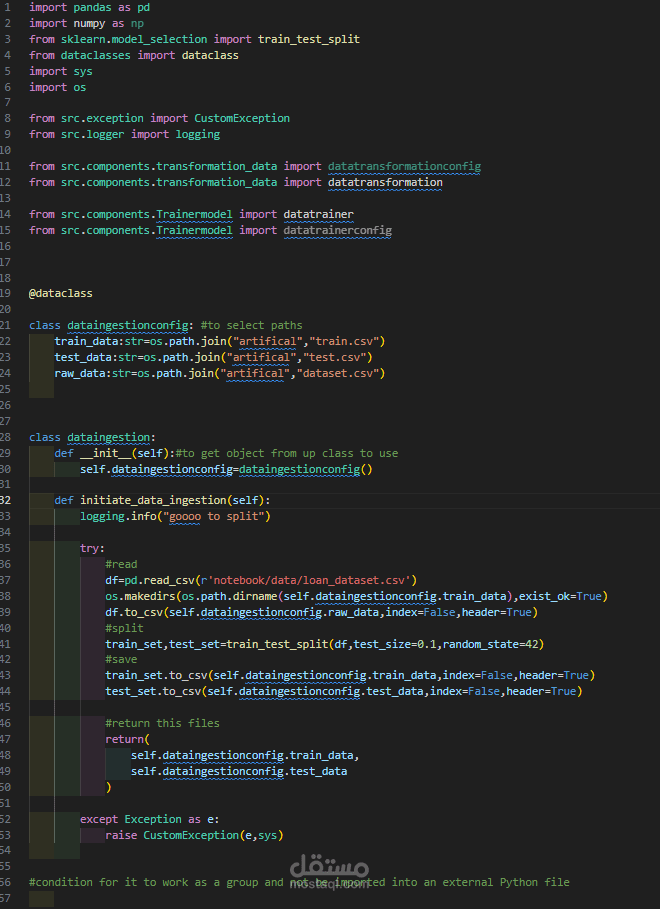
2. تنظيف البيانات (Data Cleaning):
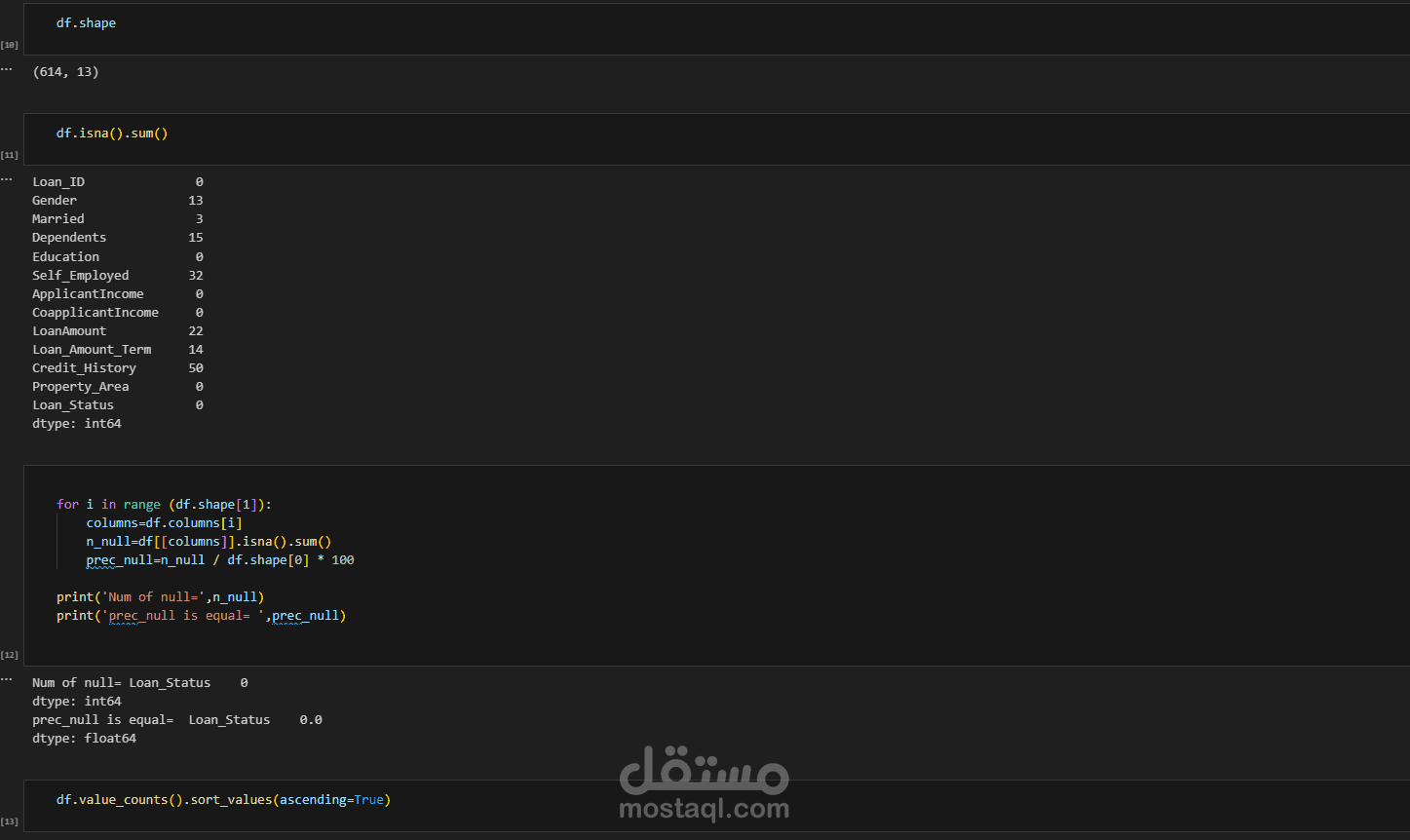
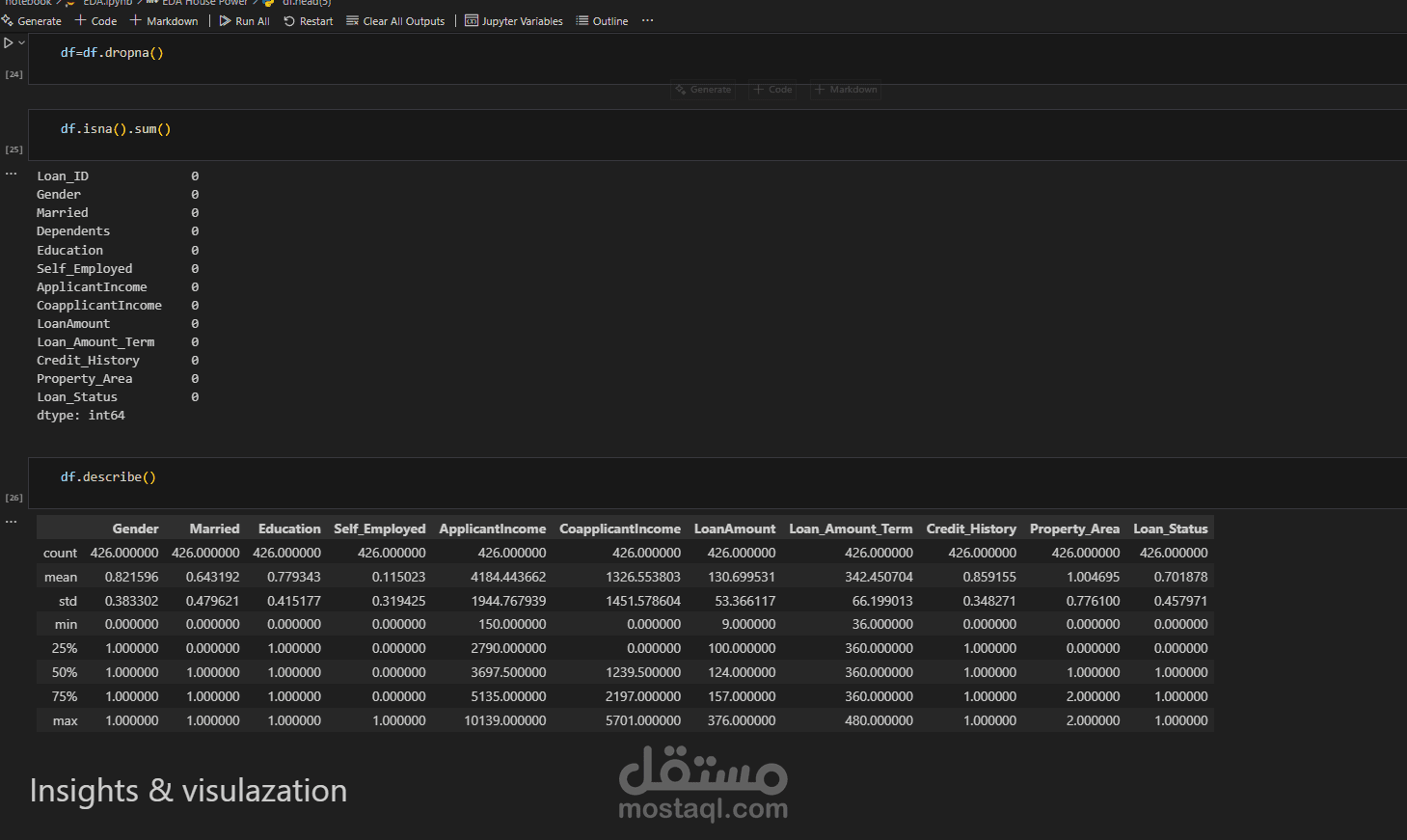
معالجة القيم المفقودة (Missing Values).
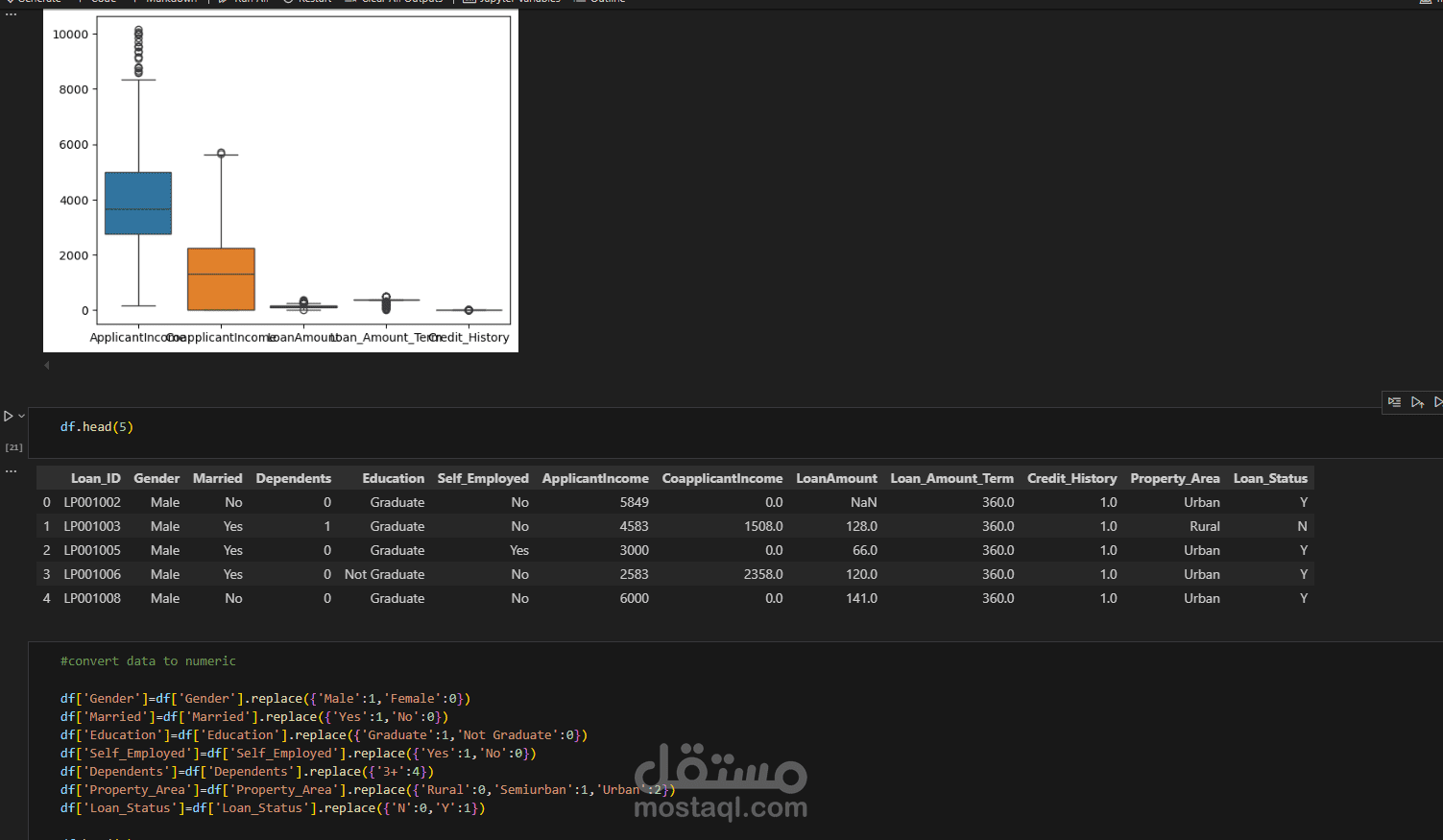
تحويل المتغيرات النصية إلى رقمية باستخدام Label Encoding وOne-Hot Encoding.
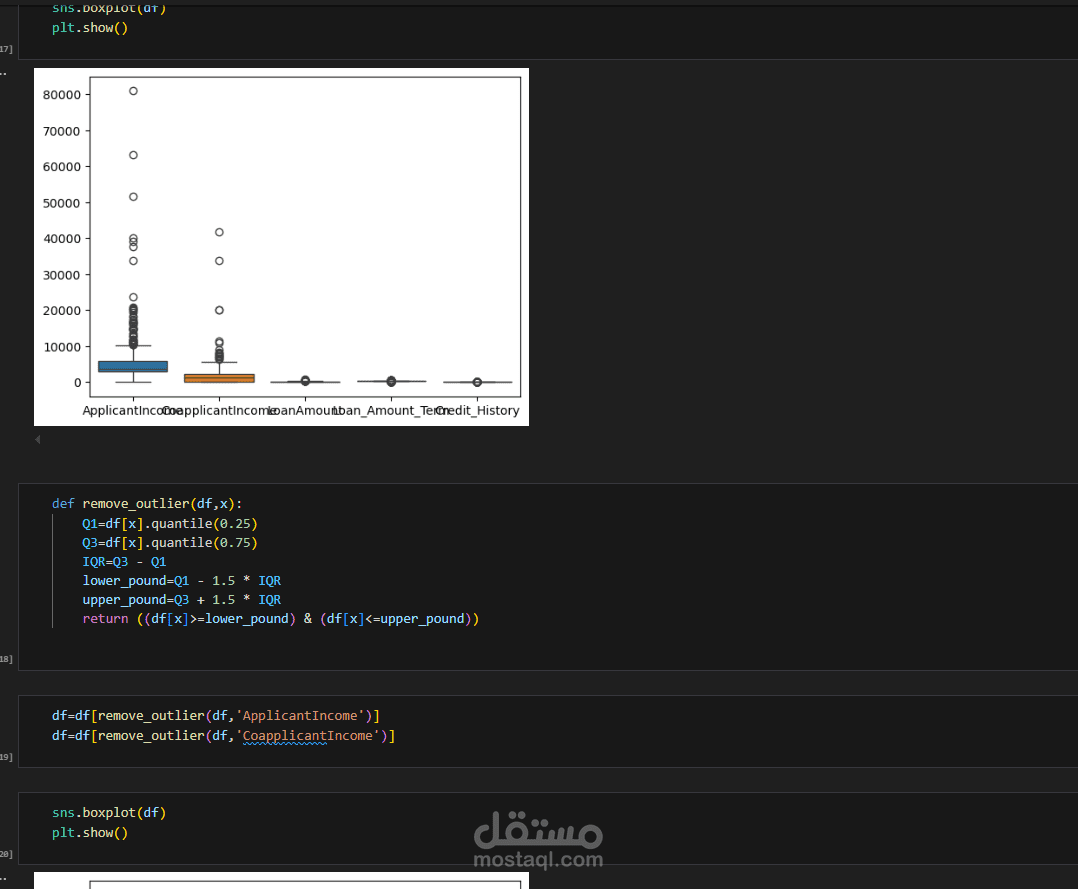
إزالة القيم الشاذة (Outliers).
3. استكشاف البيانات (Exploratory Data Analysis - EDA):
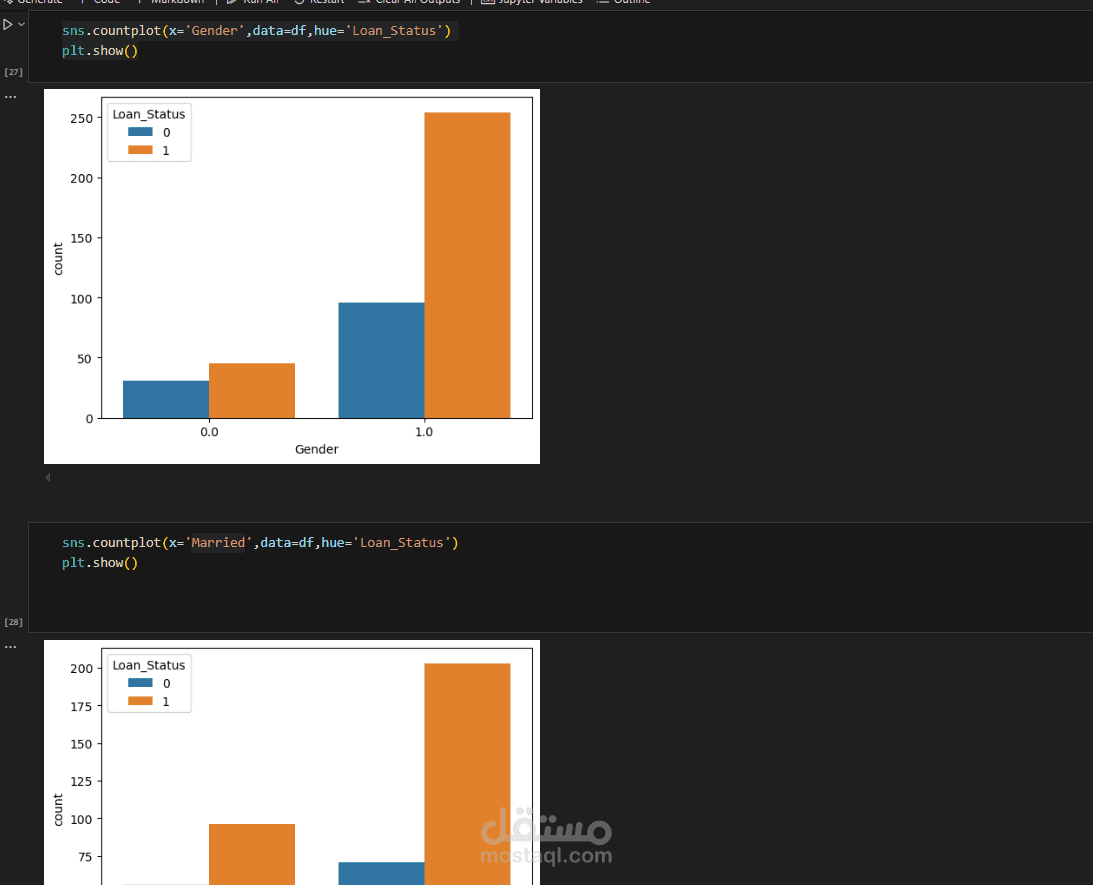
رسم بياني لتوزيع المتغيرات.
تحليل العلاقة بين المتغيرات والموافقة على القرض.
تحديد أهم الميزات المؤثرة على القرار.
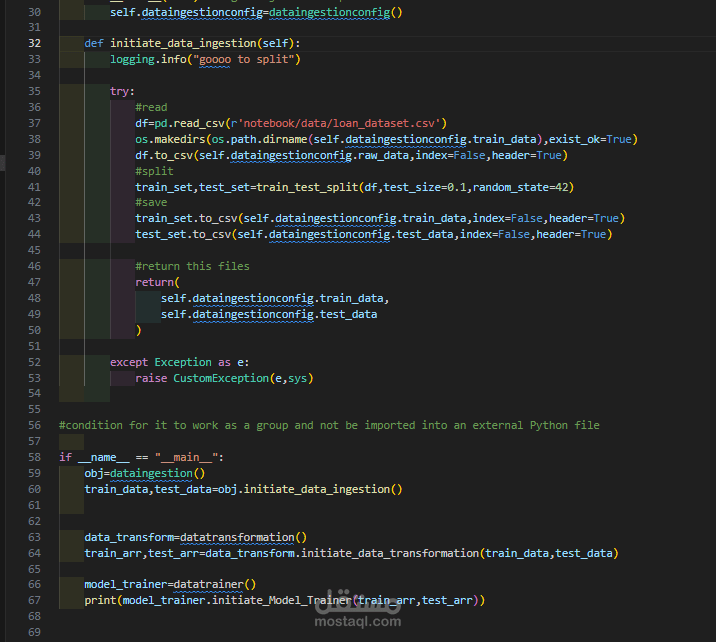
4. تحضير البيانات للنموذج (Data Preprocessing):
تقسيم البيانات إلى بيانات تدريب واختبار.
تطبيق StandardScaler لتوحيد البيانات الرقمية.
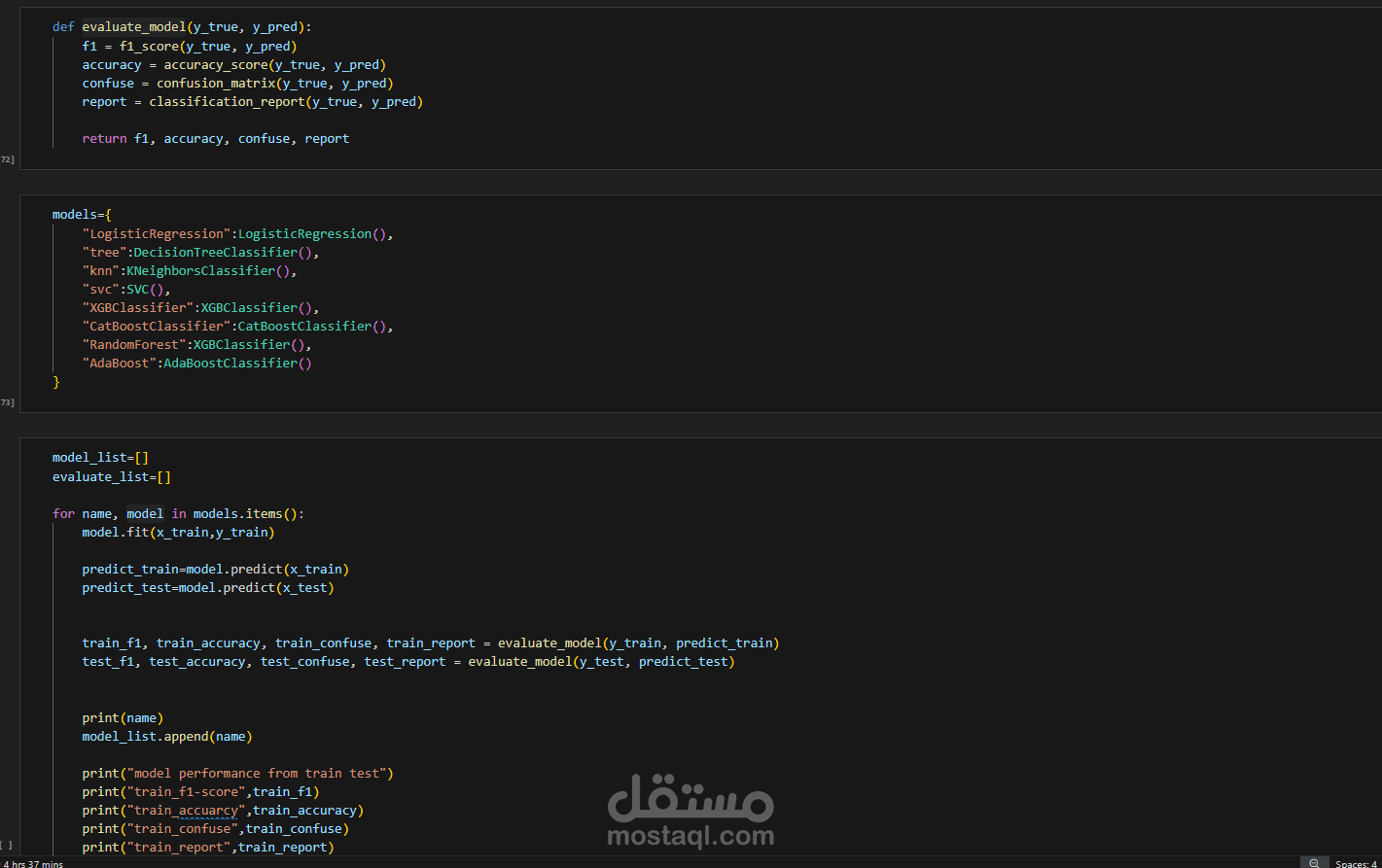
5. بناء النموذج (Model Building):
استخدام خوارزميات مثل:
Logistic Regression
Random Forest
Support Vector Machine (SVM)
اختيار أفضل نموذج من حيث الأداء والدقة.
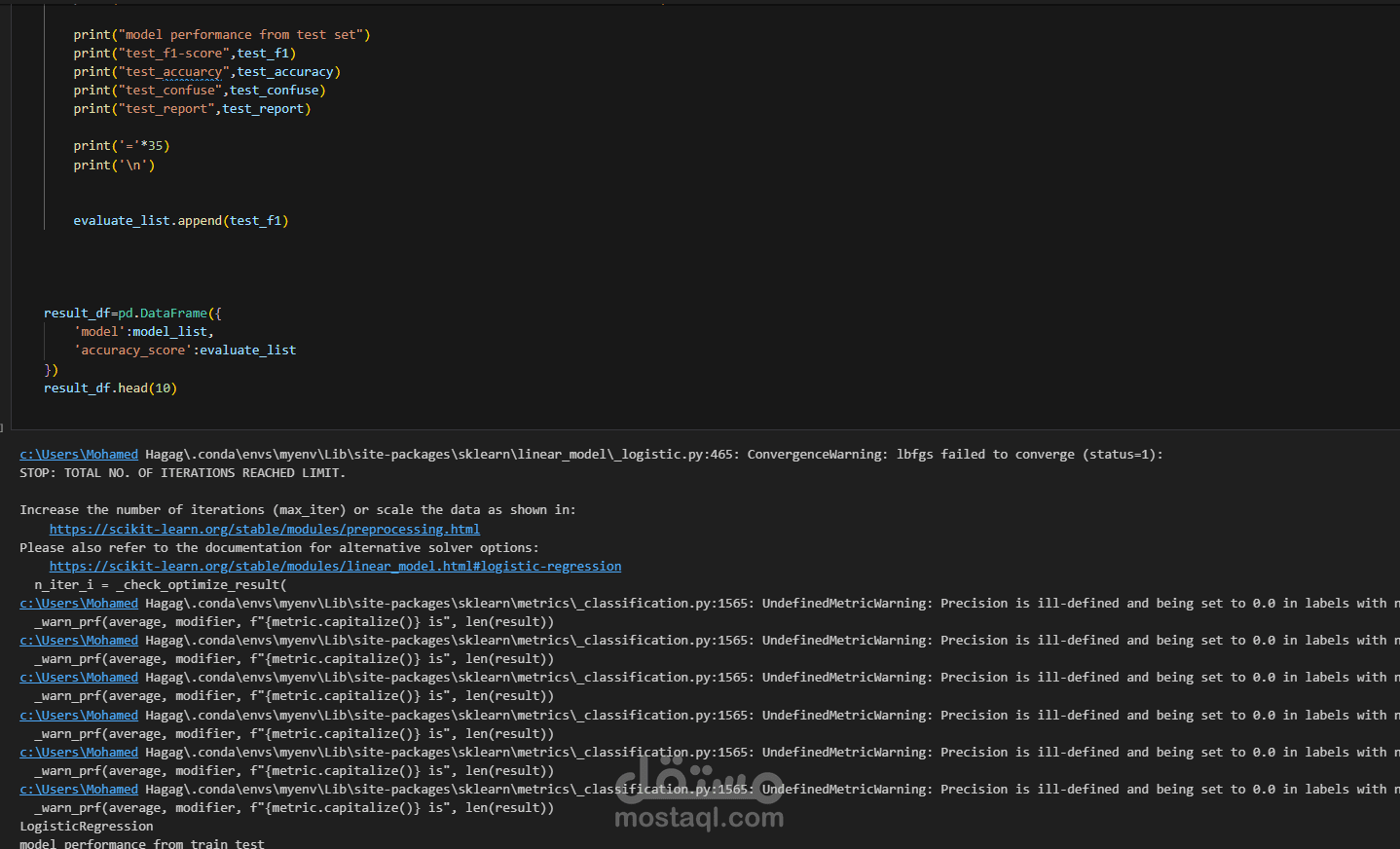
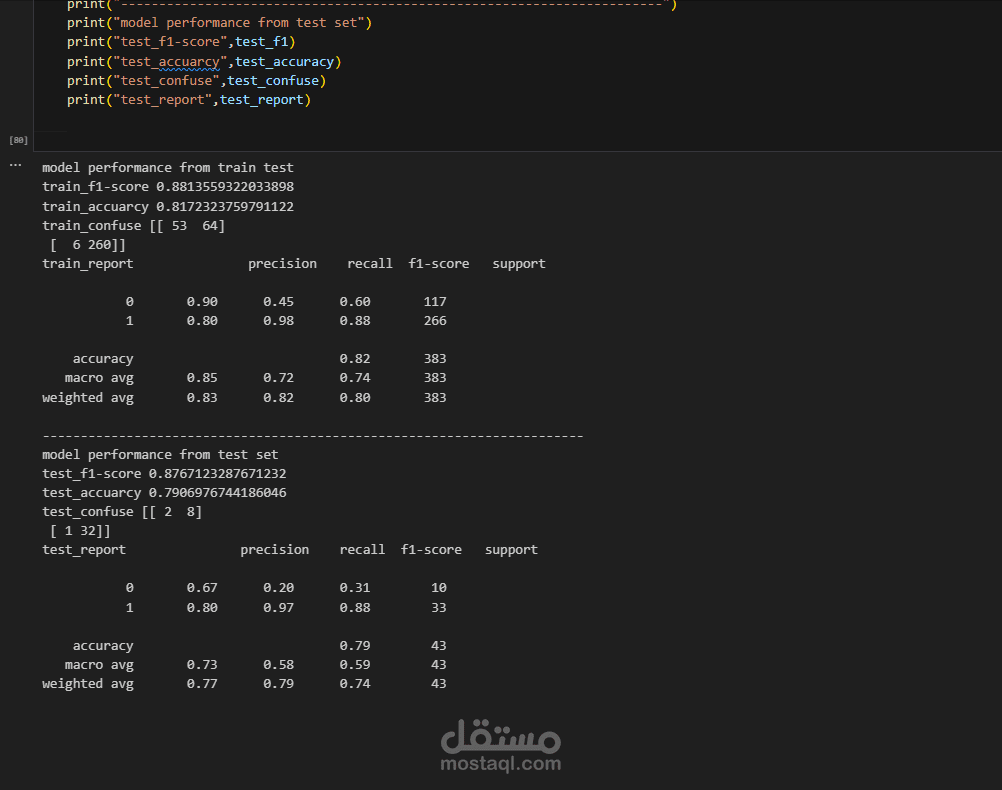
6. تقييم النموذج (Model Evaluation):
استخدام Accuracy, Precision, Recall, F1-Score.
رسم Confusion Matrix لقياس جودة التوقعات.
7. نشر النموذج (Deployment):
تطوير واجهة مستخدم بسيطة باستخدام Streamlit.
رفع النموذج المدرب وتفعيله على الواجهة.
تجربة النظام باستخدام بيانات حية وتوقعات لحظية.