أتمتة إستخراج البيانات (Web Scraping) من موقع YouTube وحفظها بأربع صيغ
تفاصيل العمل
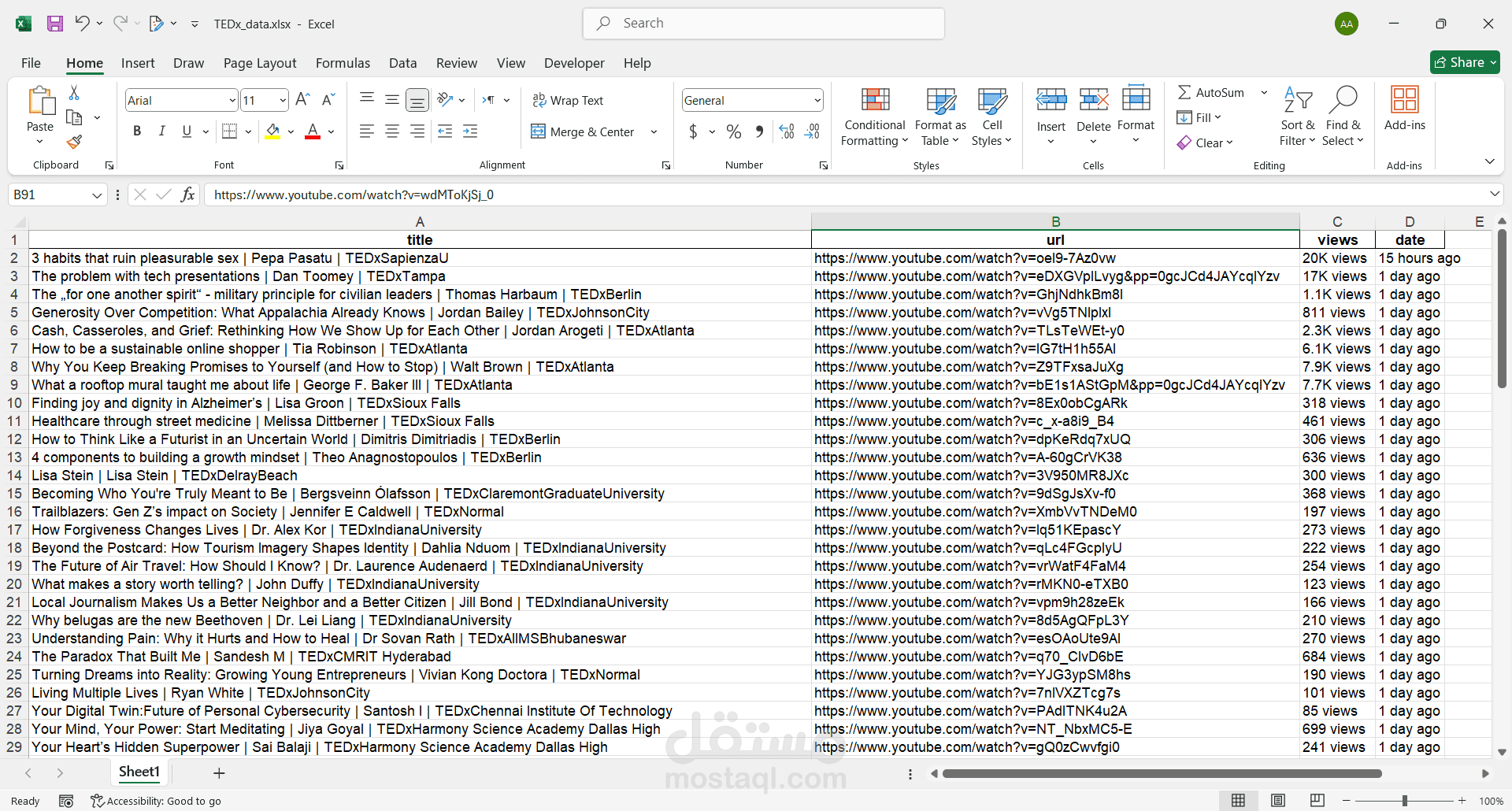
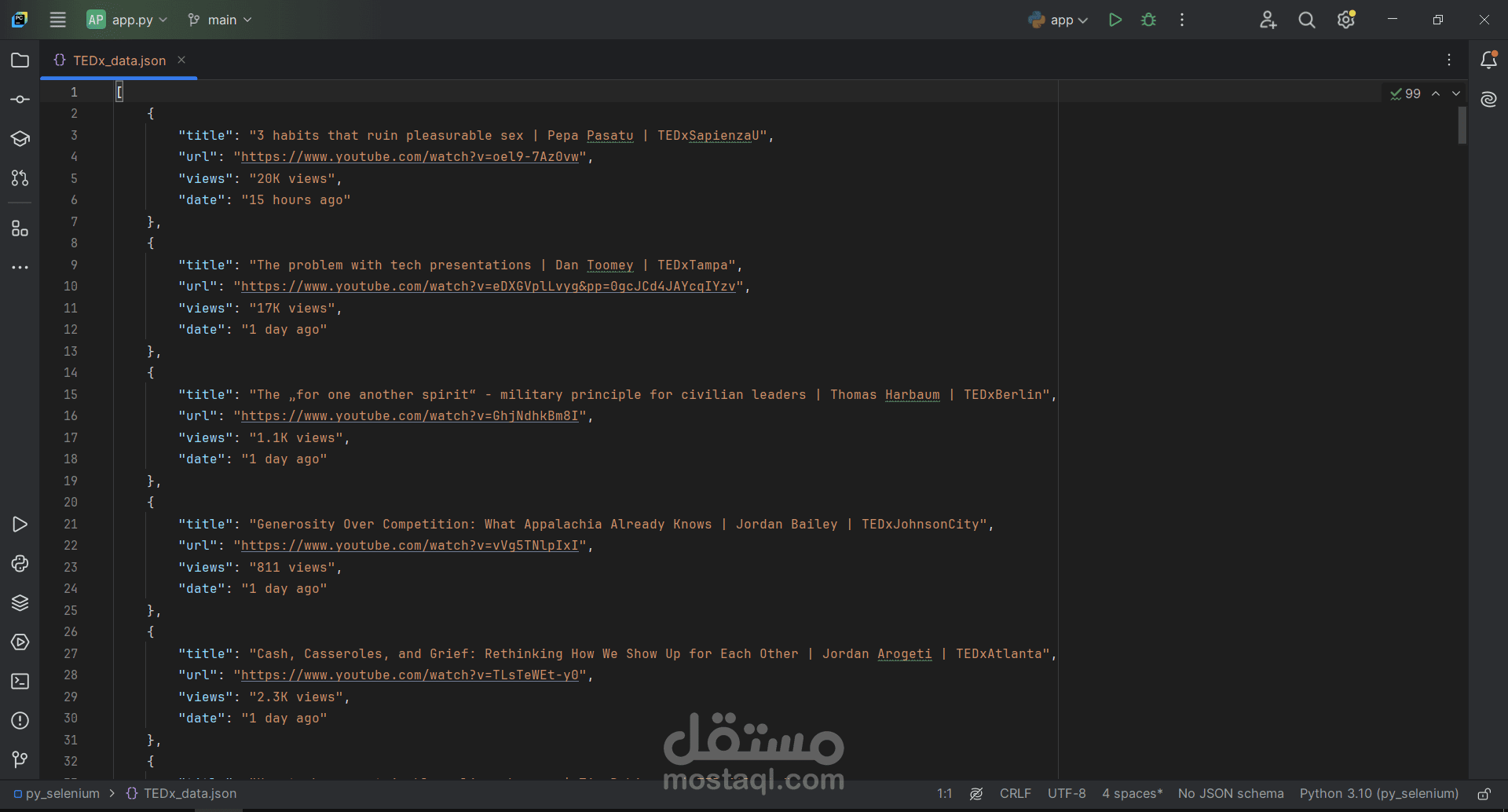
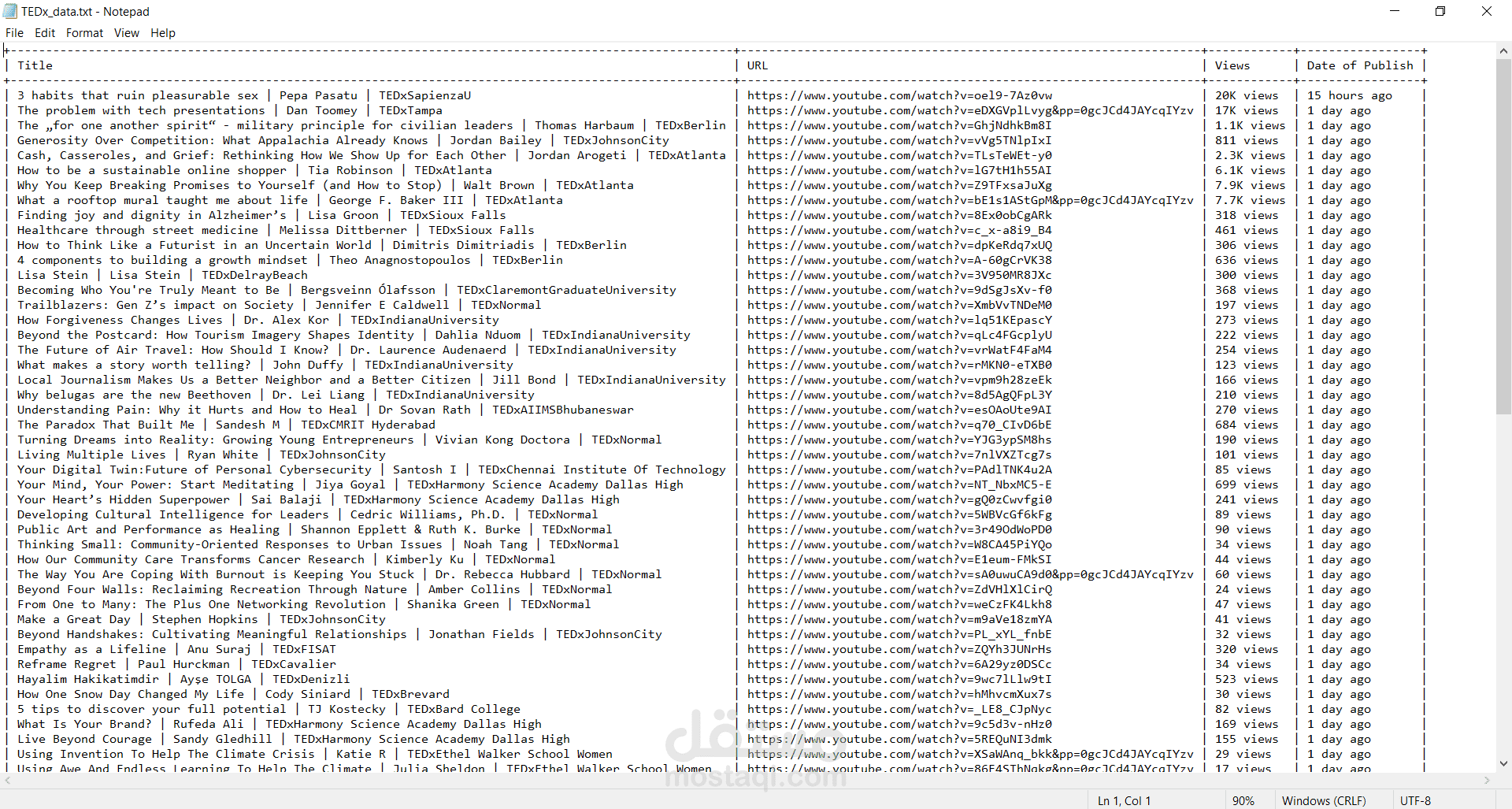
في هذا المشروع، كان الهدف بناء أداة تعتمد على Selenium لـ “التجوّل” في قناة يوتيوب، وجمع معلومات الفيديوهات (العنوان، الرابط، عدد المشاهدات، وتاريخ النشر)، ثمّ تصديرها مباشرةً إلى أربعة تنسيقات تناسب التحليل والأرشفة.
المنهجية والخطوات:
- تشغيل متصفح Edge في وضع Headless لتوفير الموارد.
- الانتقال إلى صفحة `/videos` للقناة و«التمرير» عدّة مرات (scroll) حتى تحميل العدد المطلوب من الفيديوهات.
- استخراج العناوين والروابط عبر عناصر DOM (`video-title-link`) وقراءة عدد المشاهدات والتواريخ من `metadata-line`.
- تجميع البيانات في قائمتين: الأولى لبناء جدول نصّي منسّق باستخدام مكتبة `tabulate`، والثانية لهياكل JSON.
- استدعاء `pandas` لتحويل نفس الهياكل إلى DataFrame، ثم حفظها بصيغتي CSV وExcel تلقائيًّا.
النتائج النهائية:
عند تشغيل السكربت واختيار اسم القناة وعدد دورات التمرير، يتم إنشاء أربعة ملفات في مجلّد العمل تحمل اسم القناة مسبوقًا بـ `_data`:
- ملف نصّي `.txt` بجدول منسّق
- ملف هيكل بيانات `.json`
- ملف جدول بيانات `.csv`
- ملف جداول Excel `.xlsx`