تحليل المشاعر في التغريدات العربية باستخدام Word2Vec والشبكات العصبية
تفاصيل العمل

الهدف:
يهدف هذا المشروع إلى بناء نموذج ذكاء اصطناعي قادر على تصنيف التغريدات العربية إلى إيجابية أو سلبية، باستخدام تمثيل الكلمات Word2Vec ونموذج شبكة عصبية اصطناعية (ANN).
الخطوات الرئيسية:
1. استيراد المكتبات وتثبيت الحزم اللازمة:
تم استخدام مكتبات مثل gensim, numpy, pandas, nltk, tensorflow, و keras لتحميل البيانات ومعالجتها وبناء النموذج.
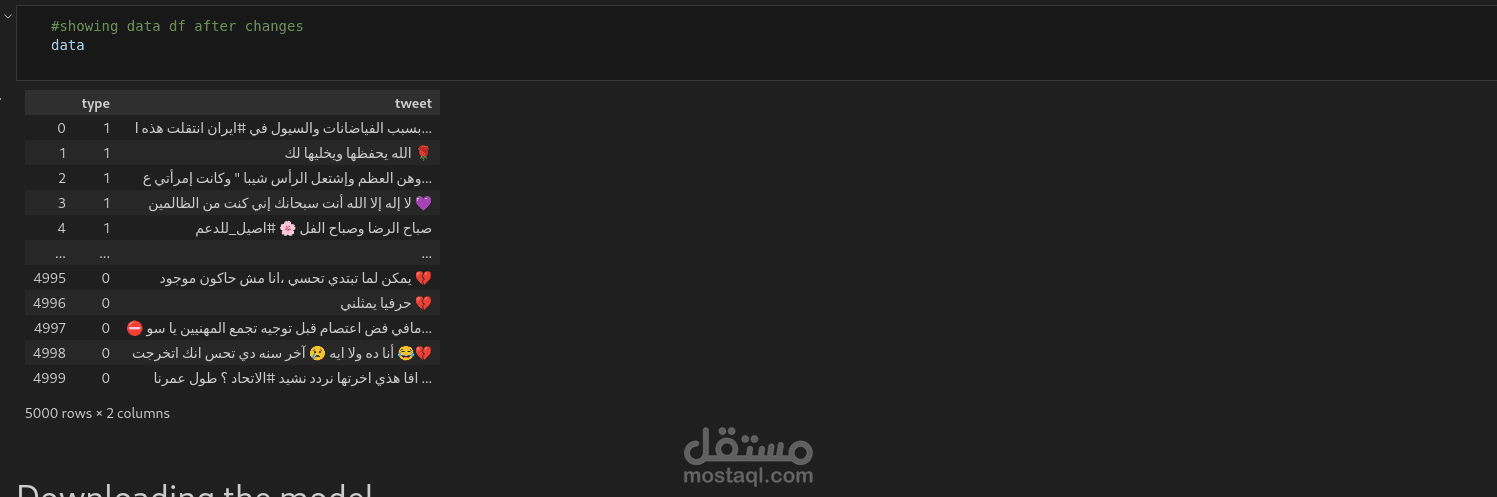
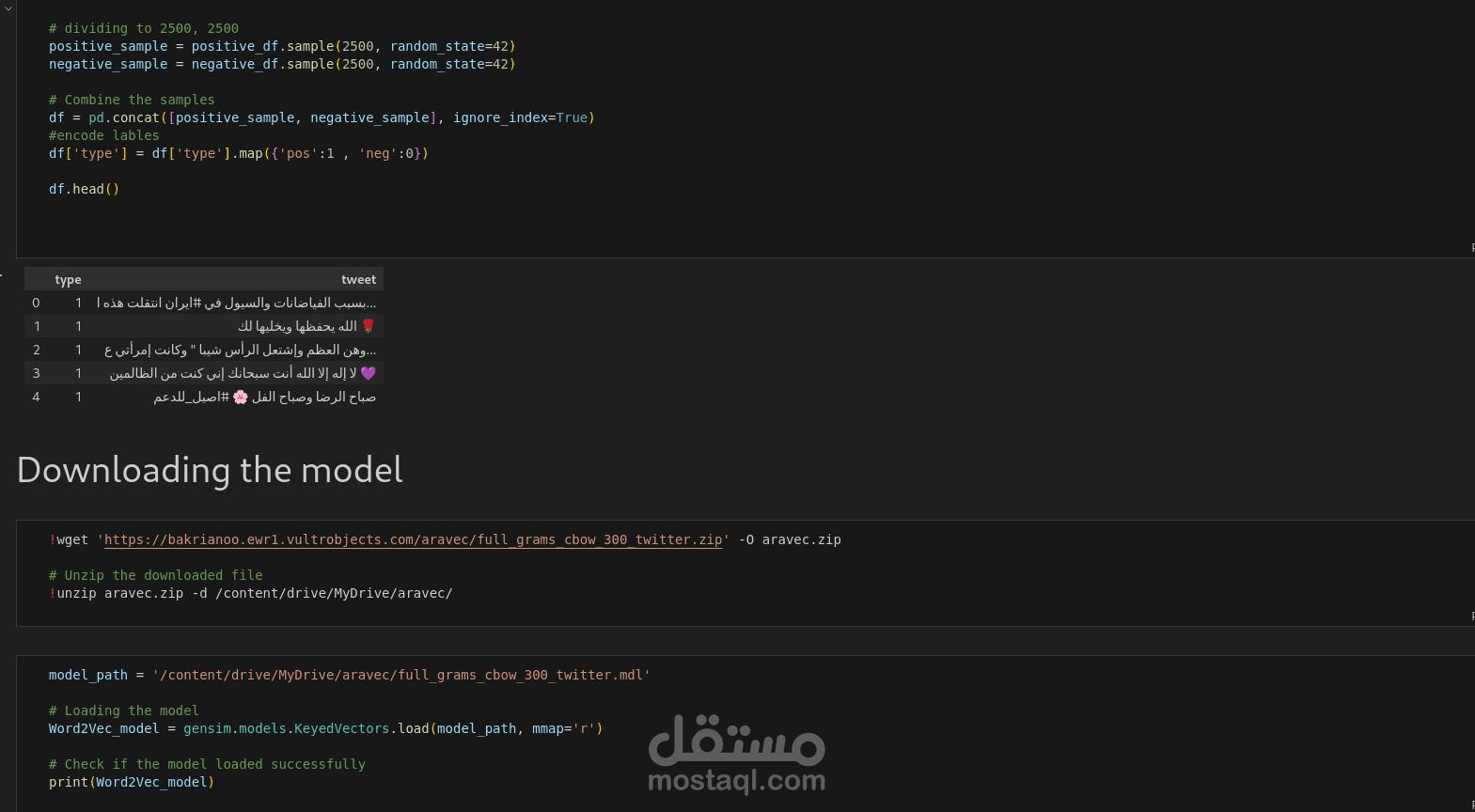
2. تحميل البيانات:
تم تحميل مجموعتي بيانات تحتويان على تغريدات عربية مصنفة كموجبة وسالبة، ثم تم أخذ عينة متوازنة من كل فئة (2500 تغريدة موجبة و2500 سالبة).
3. تنظيف البيانات وتحليلها:
إزالة الرموز والأرقام من التغريدات.
استخدام nltk لتقطيع التغريدات إلى كلمات.
تنظيف الرموز الزائدة وتصفية الكلمات.
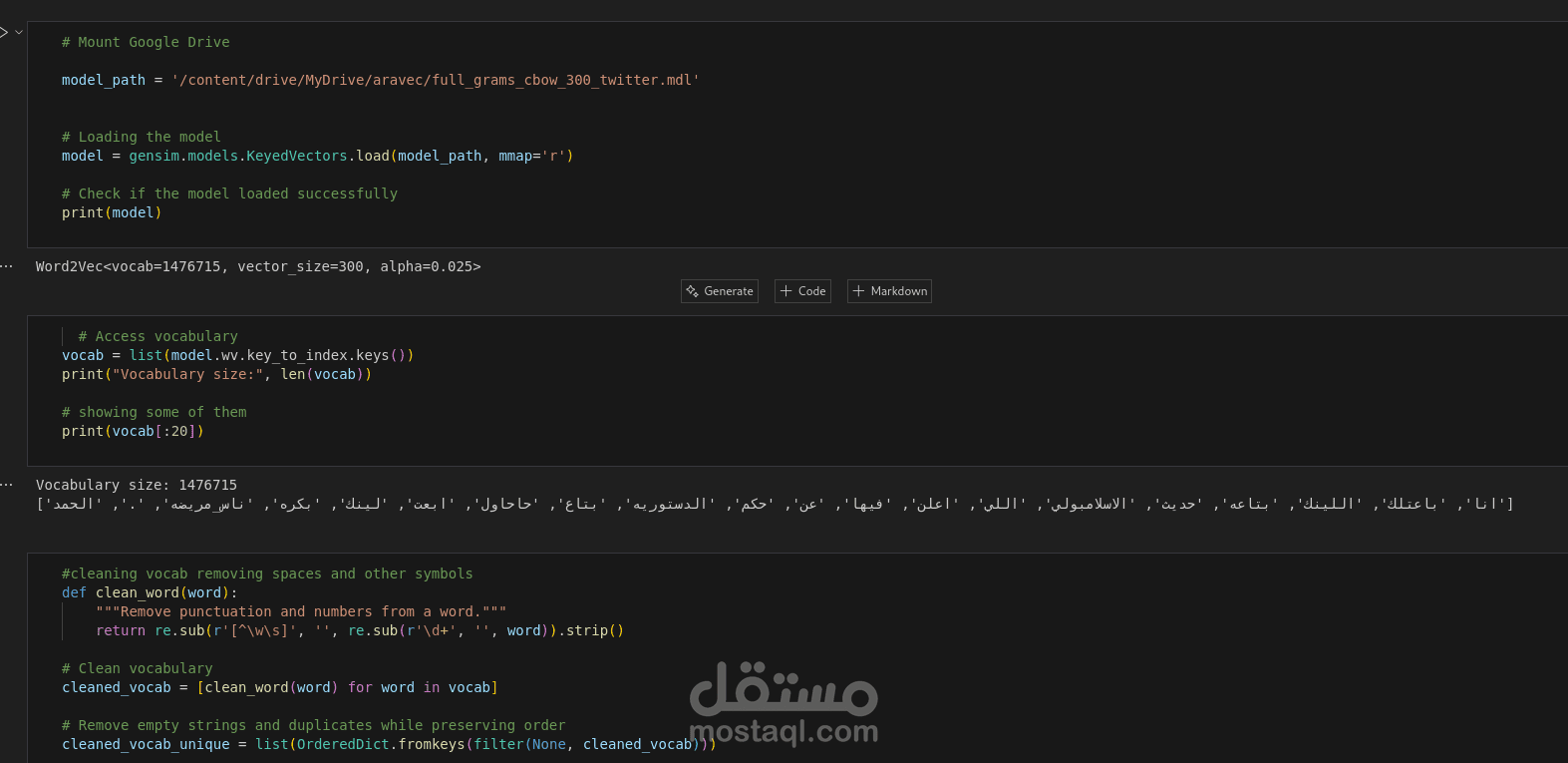
4. تحميل نموذج Word2Vec (AraVec):
تم تحميل نموذج "AraVec" المدرب مسبقًا على بيانات تويتر العربية. ثم تم استخراج المفردات وتمثيل كل تغريدة كمتوسط متجهات الكلمات المكوّنة لها.
5. إنشاء تمثيل BoW (اختياري):
تم تحويل التغريدات إلى تمثيل يعتمد على الحقيبة الكلمات (BoW) باستخدام CountVectorizer، بهدف المقارنة لاحقًا.
6. تمثيل التغريدات باستخدام Word2Vec:
تم استخدام دالة لحساب متوسط تمثيل Word2Vec لكل تغريدة بناءً على الكلمات المتوفرة في النموذج.
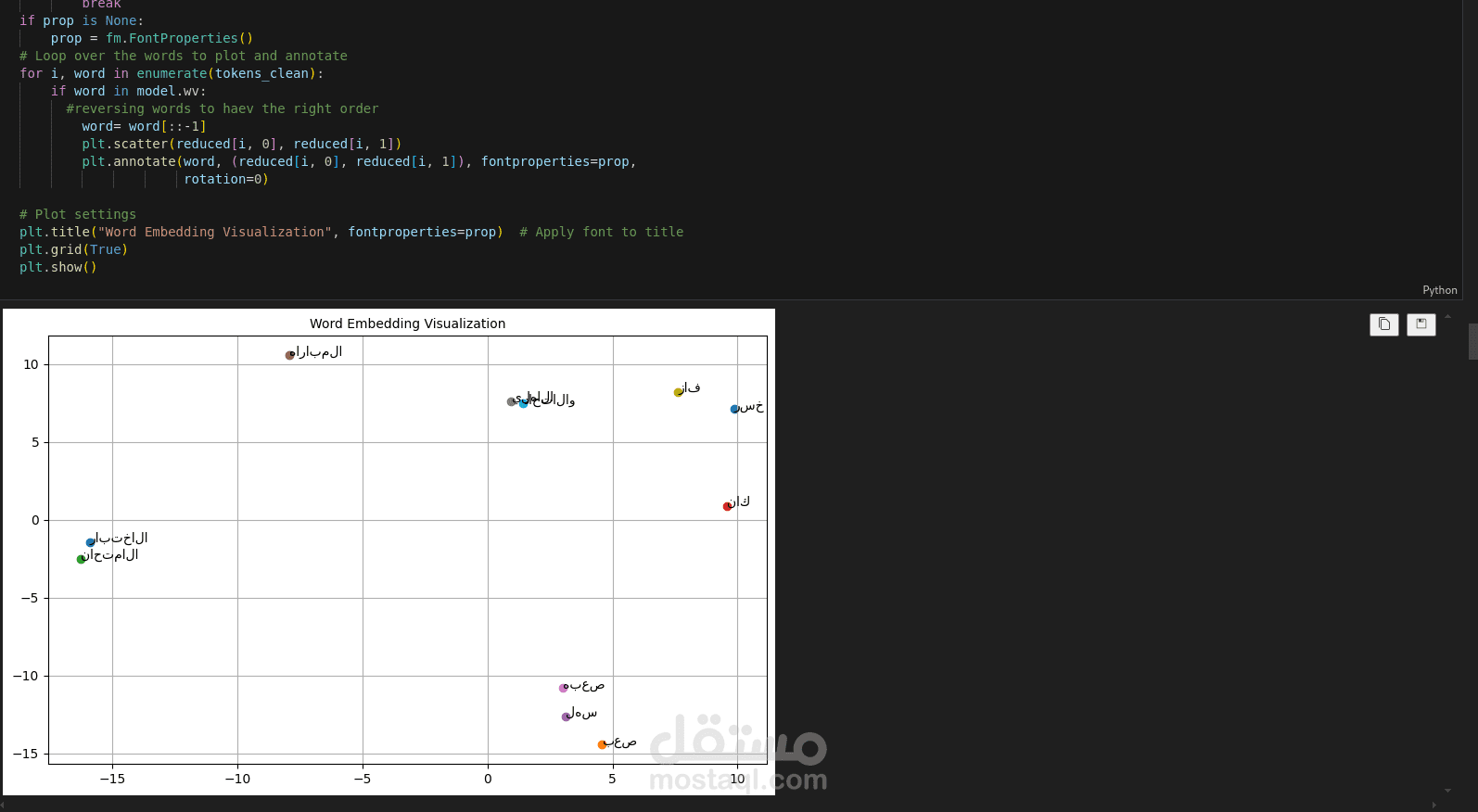
7. تصوير تمثيلات الكلمات:
تم تطبيق خوارزمية PCA لتقليل الأبعاد إلى 2D وتم رسم تمثيلات لبعض الكلمات باستخدام matplotlib.
8. بناء نموذج الشبكة العصبية (ANN):
طبقة إدخال تستقبل متجهات Word2Vec.
طبقة مخفية تحتوي على 4 خلايا عصبية (Neurons).
طبقة إخراج تحتوي على خليتين للتصنيف الثنائي (موجب/سالب).
9. تدريب النموذج:
تم تدريب النموذج باستخدام خوارزمية Nadam، مع استخدام EarlyStopping و ReduceLROnPlateau لتحسين عملية التعلم.
10. تقييم الأداء:
تم اختبار النموذج على بيانات الاختبار واحتساب دقة النموذج، الدقة الإيجابية، الاستدعاء، والـ F1-score.
النتائج المتوقعة:
بعد التدريب، يقوم النموذج بتوقع المشاعر (إيجابية أو سلبية) للتغريدات الجديدة بدقة عالية. النموذج يمكن تحسينه مستقبلاً بإضافة:
معالجة لغوية متقدمة (مثل التجذير).
استخدام نماذج أعمق أو تحويلية مثل BERT العربي.