Speech Command Recognition Using CNN
تفاصيل العمل
Speech Command Recognition Using CNN
This project implements a Convolutional Neural Network (CNN) to recognize spoken digits (1 through 10) using the TensorFlow Speech Commands dataset. The workflow includes preprocessing raw audio into MFCC features, training a CNN classifier, and evaluating its performance on real-world audio inputs.
Key Features:
Audio Feature Extraction: Transformed raw .wav files into Mel-Frequency Cepstral Coefficients (MFCCs) to highlight meaningful frequency patterns in speech.
Targeted Digit Recognition: Filtered and mapped dataset labels to digits “1” through “10” to focus on numeric speech commands.
CNN Architecture: Built a robust CNN with convolutional, batch normalization, max pooling, and dropout layers to learn audio feature patterns effectively.
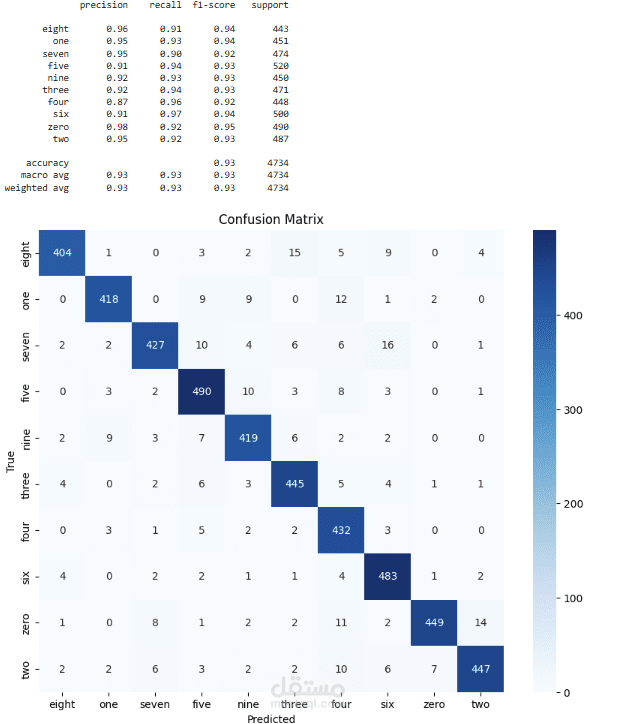
High Accuracy Achieved: The model achieved 98.96% accuracy on the test set, demonstrating excellent generalization to unseen audio samples.
Inference Capability: Implemented prediction on single audio clips, showcasing the model's readiness for real-time or embedded applications.
Confusion Matrix & Evaluation: Visualized model performance using a confusion matrix to confirm class-level accuracy and stability.