Customer Churn Prediction & Retention Strategy
تفاصيل العمل
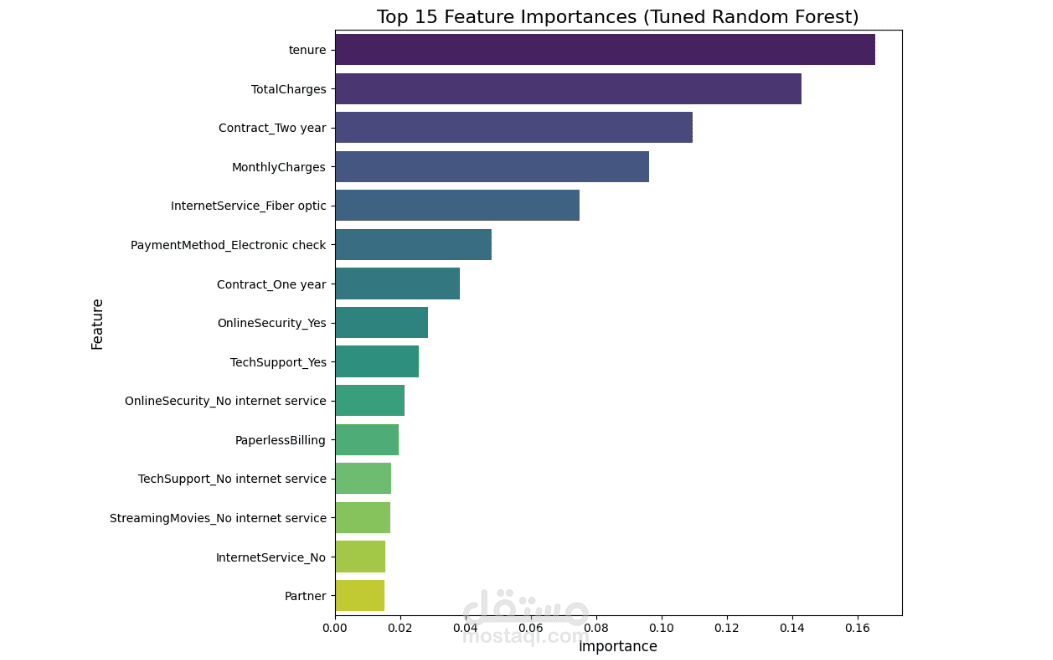
Customer Churn Prediction & Retention Strategy
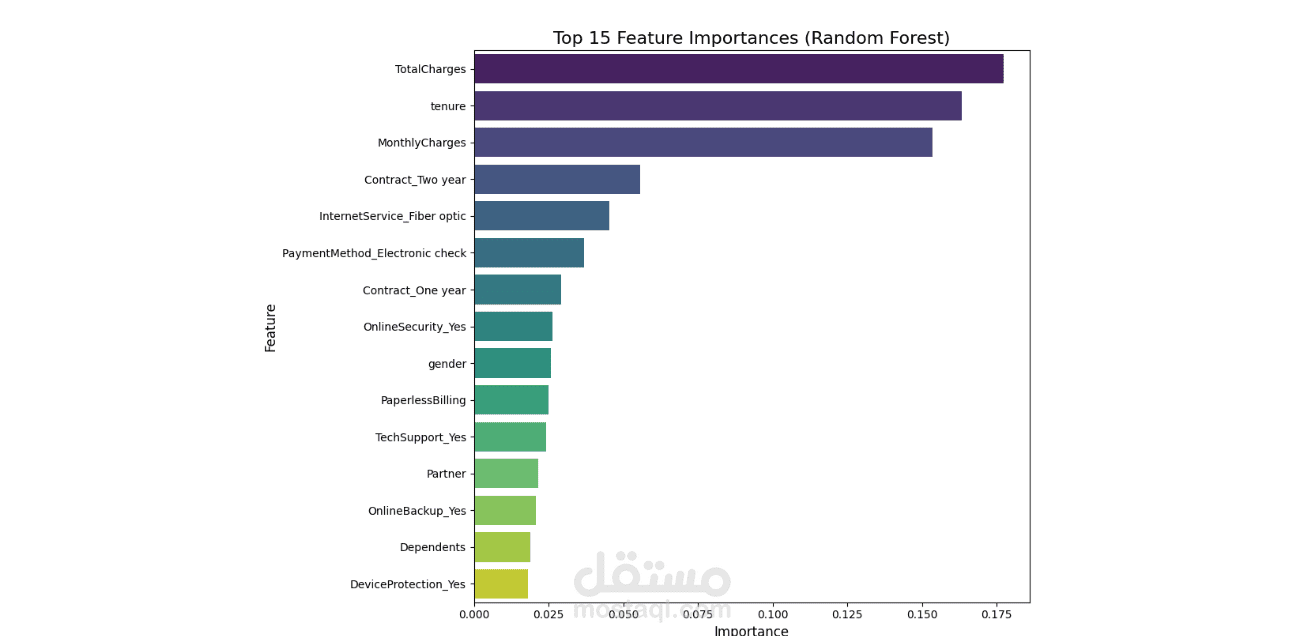
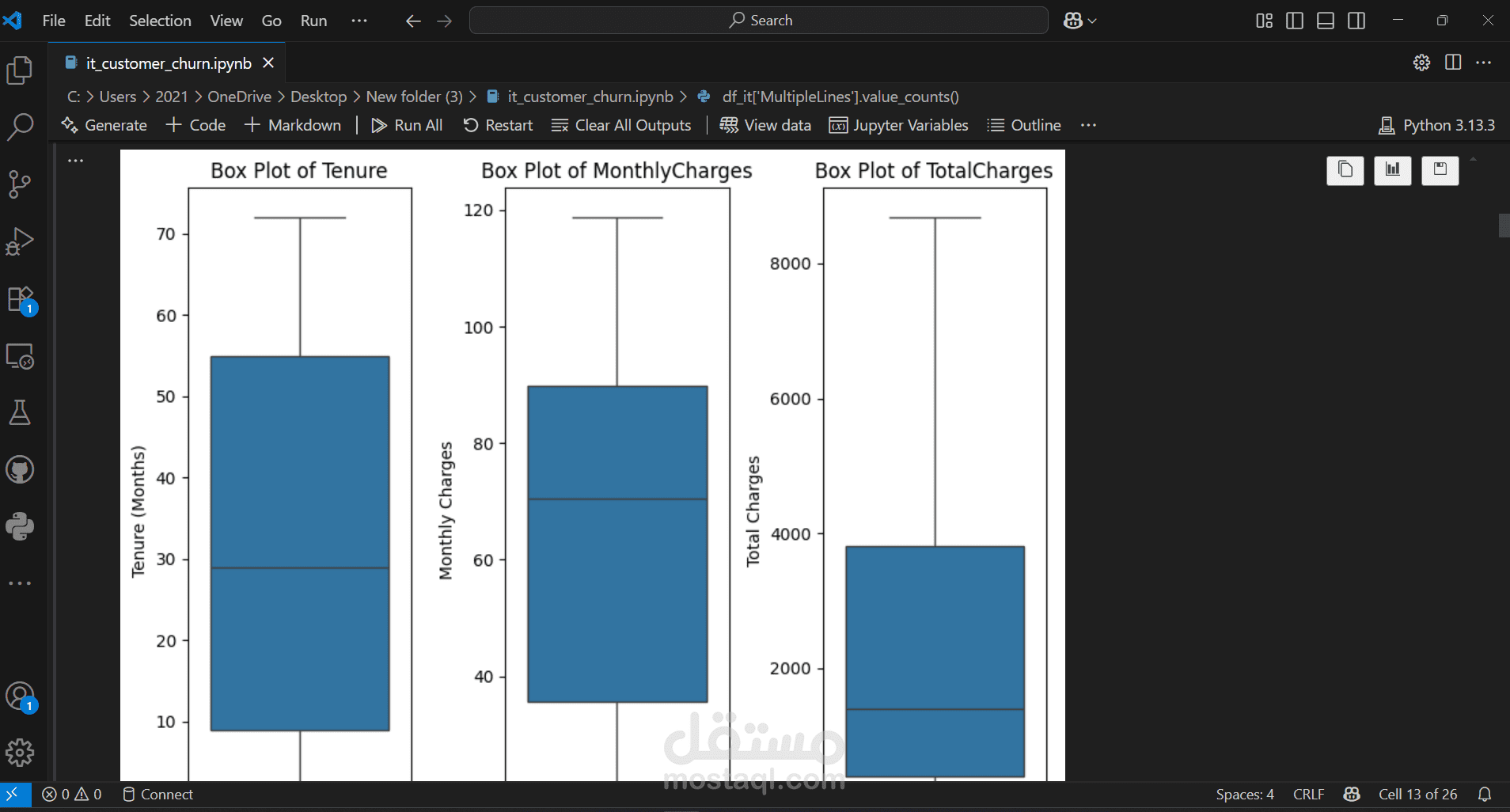
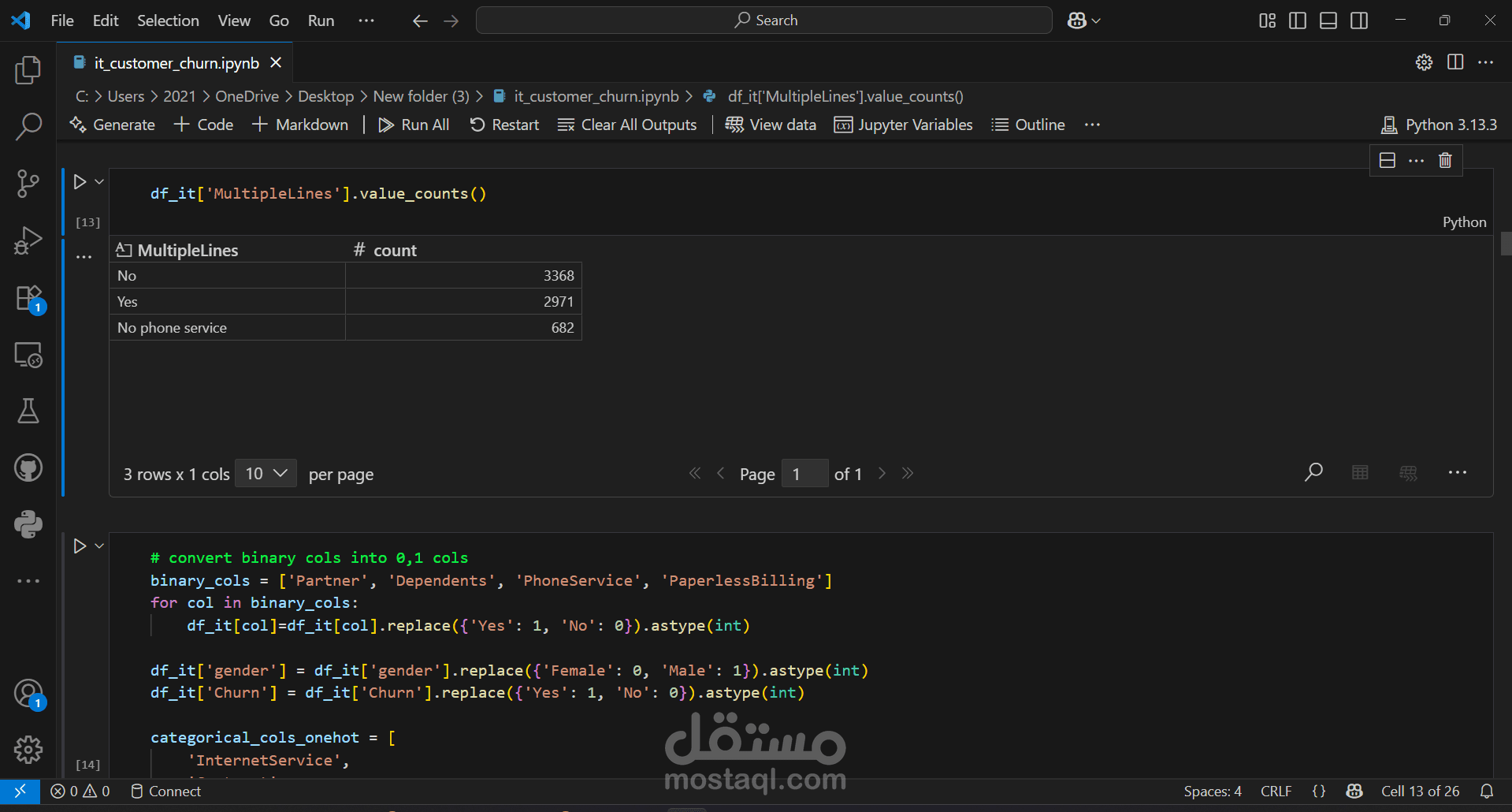
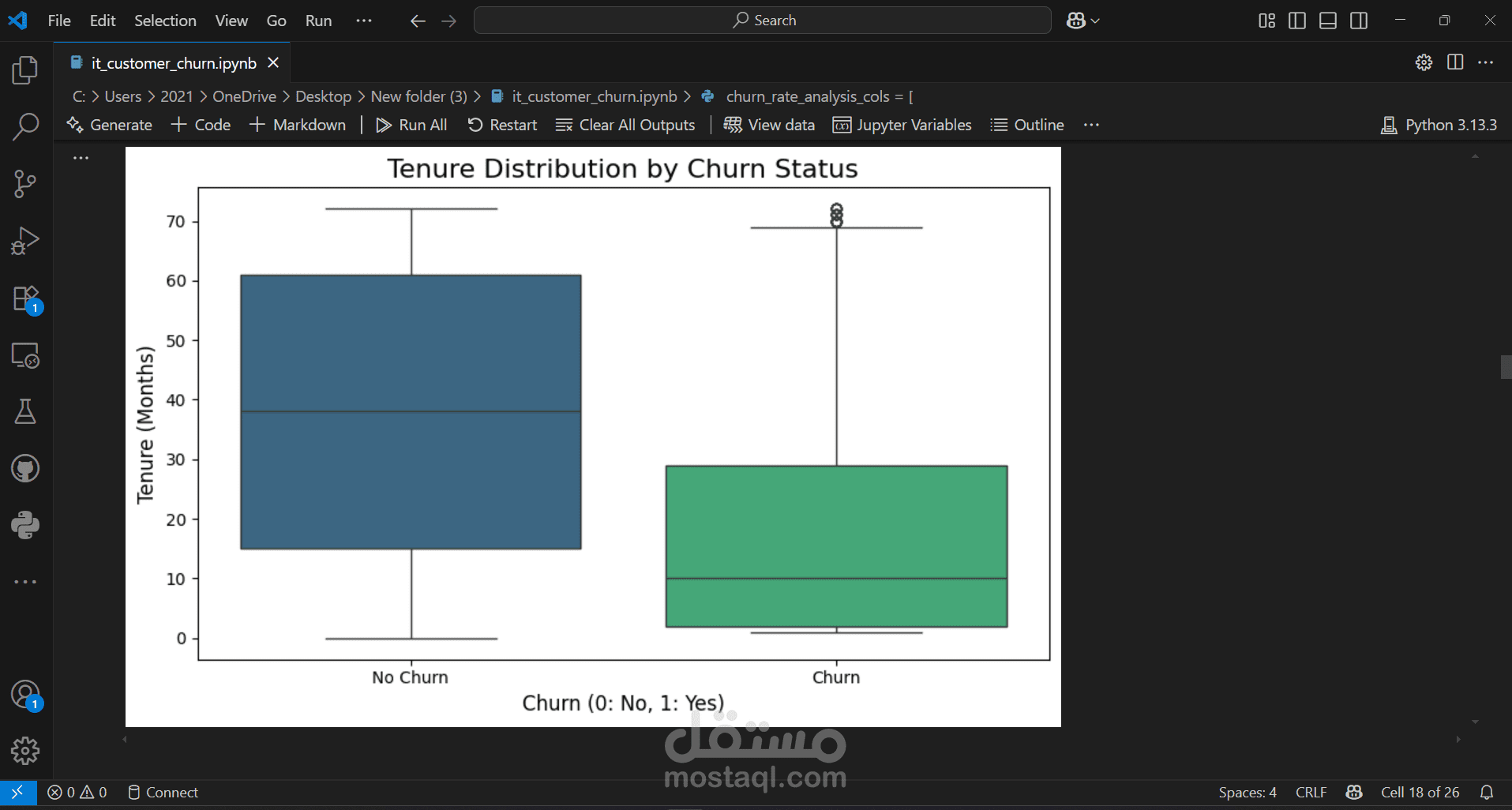
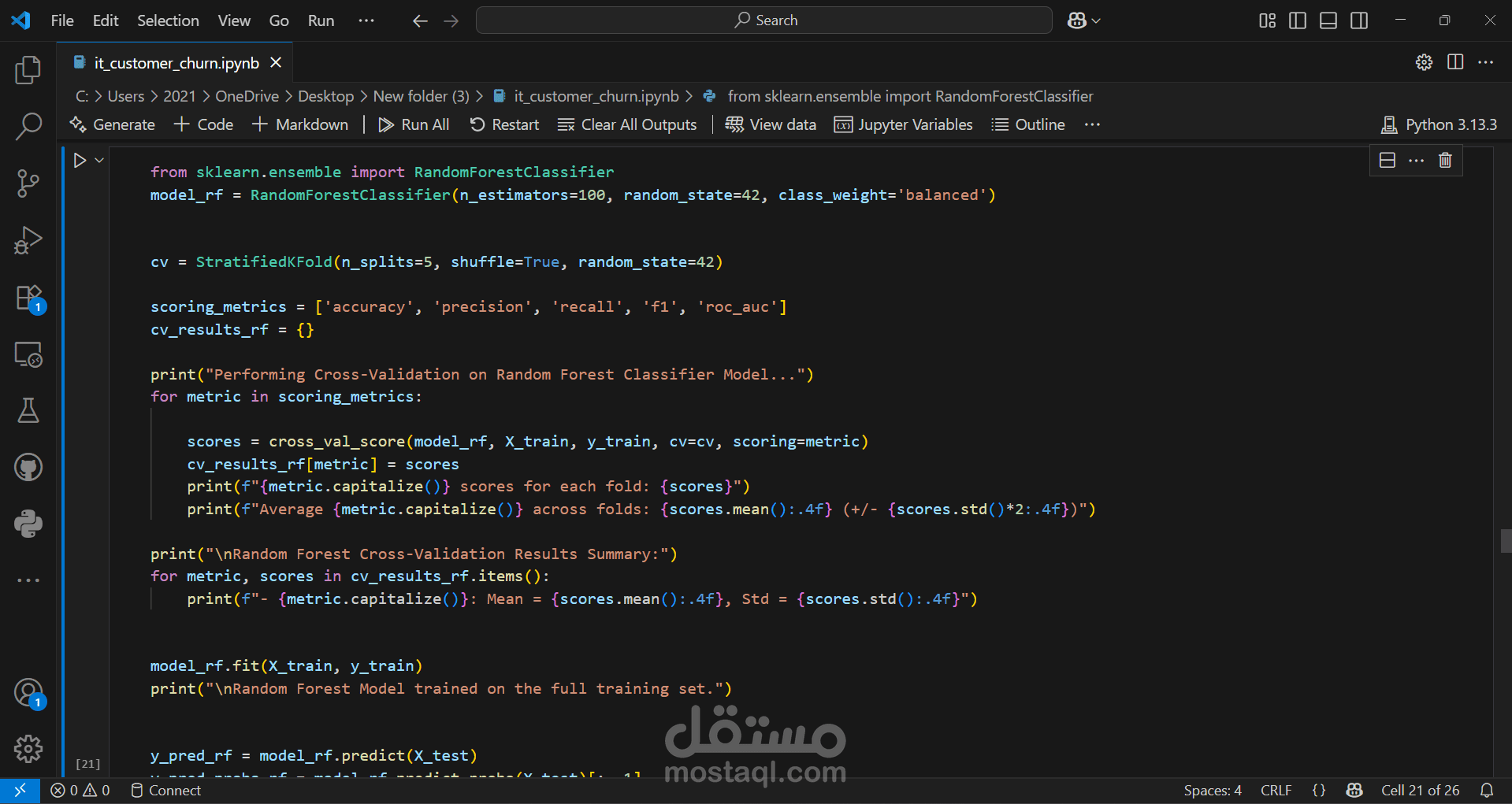
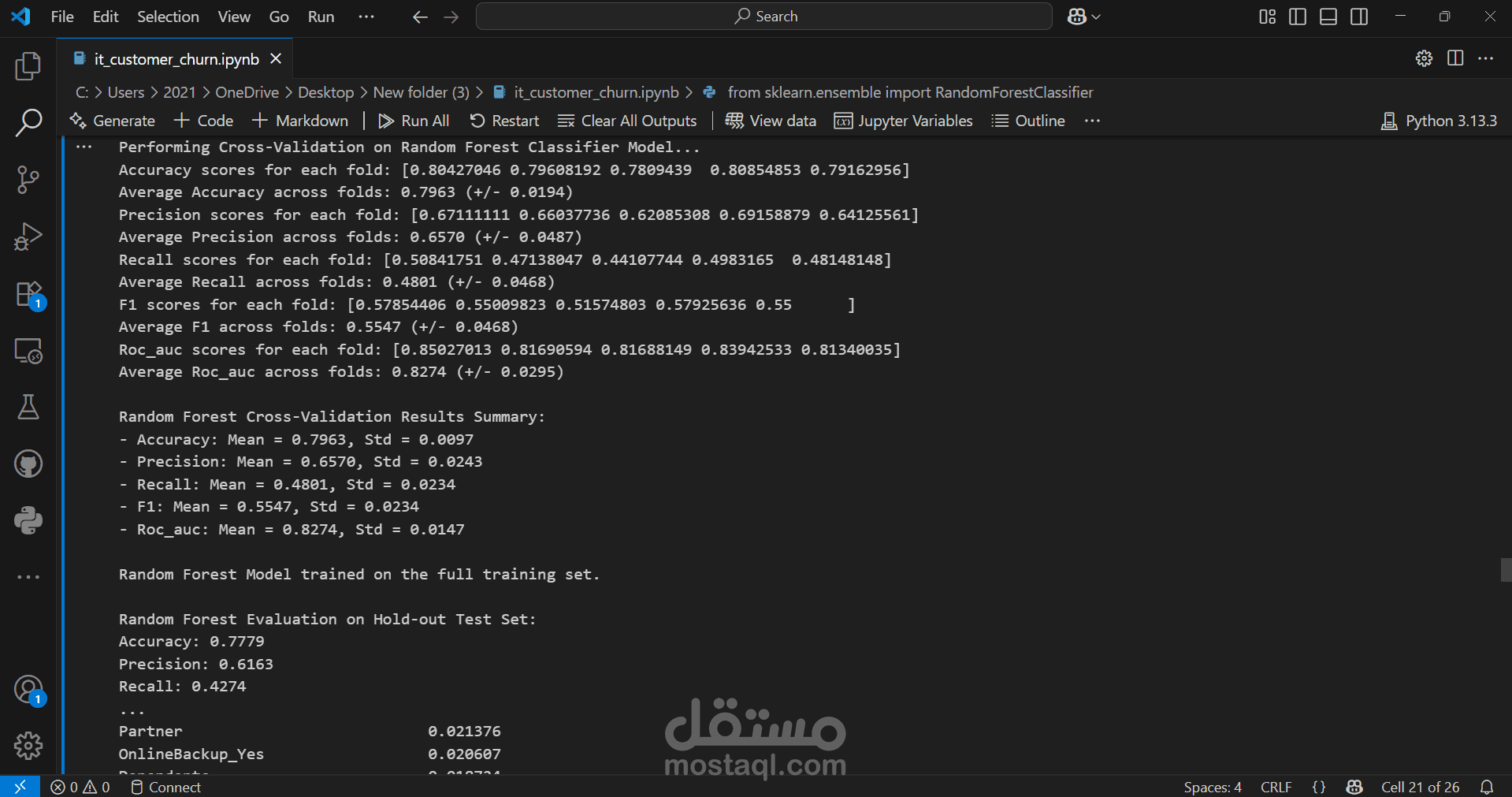
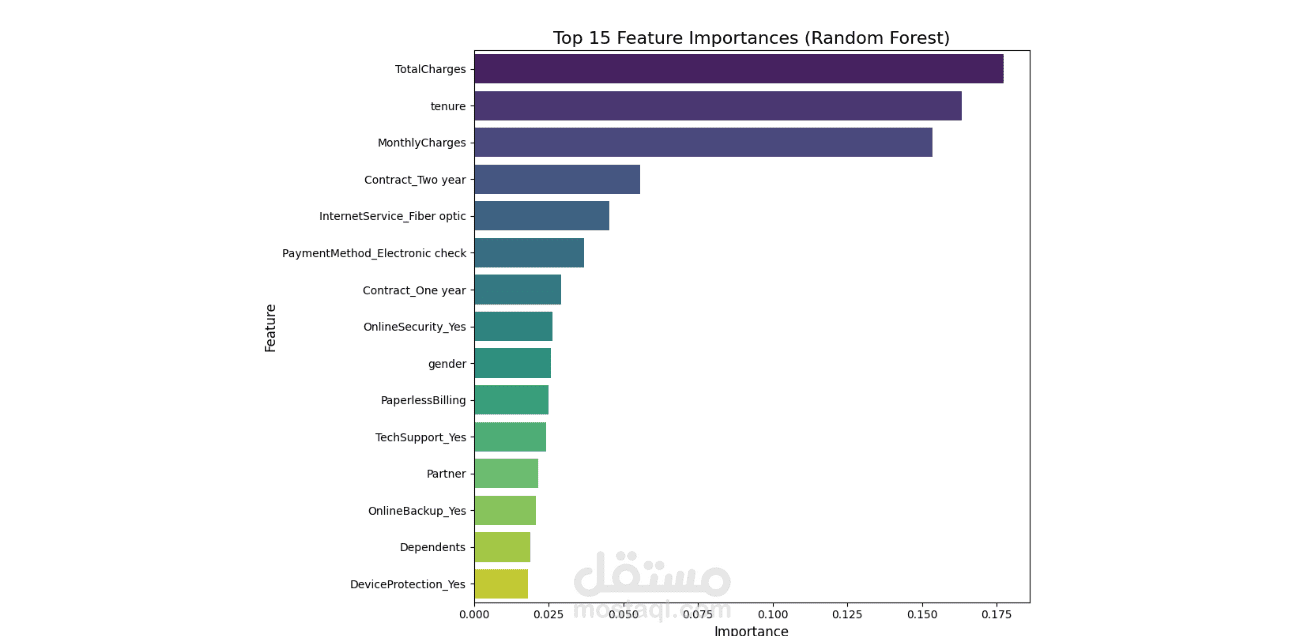
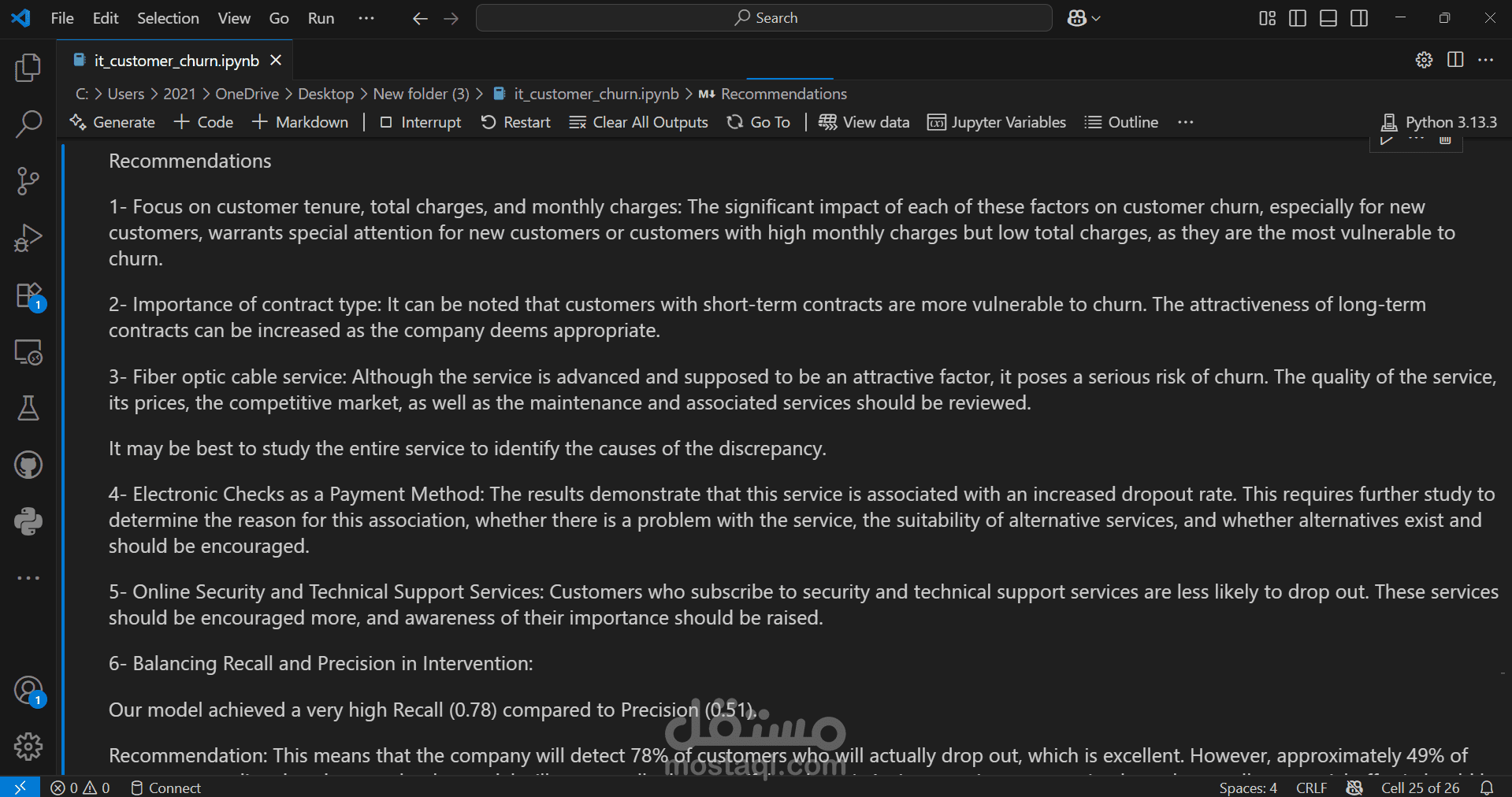
We started by importing the data, then verified the data types for the columns, performed data cleaning, handled null values, and considered outliers as a starting point for the analysis process. This was followed by a simple descriptive analysis to study the features and their effects, as well as to gain a better understanding and familiarity with the data, as shown in the code. We then created two prediction models, each in two forms: a normal image and an image, using RandomizedSearchCV. Based on the results of several metrics, we selected the logistic regression model with RandomizedSearchCV as the most appropriate model among the tested models. Based on the above, we reached the following recommendations: