End-to-End RAG(Retrieval-Augmented Generation ) System with DeepSeek
تفاصيل العمل
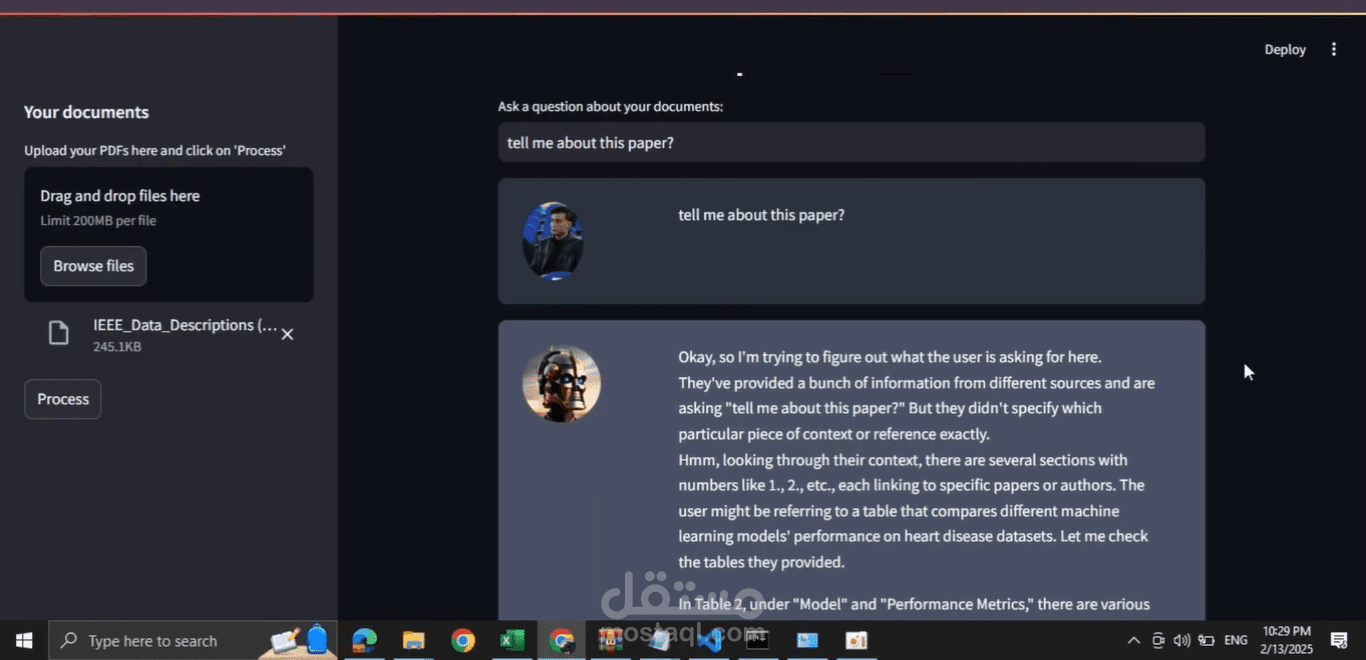
I’ve developed an End-to-End Retrieval-Augmented Generation (RAG) system that allows you to interact with your PDFs like never before. Powered by DeepSeek, an open-source framework, this system enables intelligent, context-aware responses to your questions based on the content of the documents you provide. It’s a seamless and efficient solution for working with large amounts of text data!
How It Works
1️⃣ Text Extraction
The journey starts with extracting text from PDF files using PyPDF2. This step transforms static documents into executable content that can be processed by the AI system.
2️⃣ Efficient Text Chunking
To avoid overwhelming the AI with excessive information, the extracted text is split into manageable chunks using LangChain’s CharacterTextSplitter. This ensures that each chunk retains its context while making it easier for the model to retrieve relevant information quickly.
3️⃣ Text to Embeddings using DeepSeek
DeepSeek, an open-source framework, is used to convert the text chunks into embeddings via OllamaEmbeddings. This allows the system to perform semantic search, quickly retrieving accurate information from the documents.
4️⃣ Information Retrieval and Instant Response Generation with LLM
DeepSeek-R1, an open-source Large Language Model (LLM), is used to generate intelligent responses based on the retrieved content. By using DeepSeek for embeddings and LLM for response generation, we get context-aware, accurate answers instantly.
5️⃣ Memory for Ongoing Conversations
With LangChain’s ConversationBufferMemory, the system stores chat history, preserving context and enabling smoother, more natural interactions across multiple queries