News-clustring
تفاصيل العمل

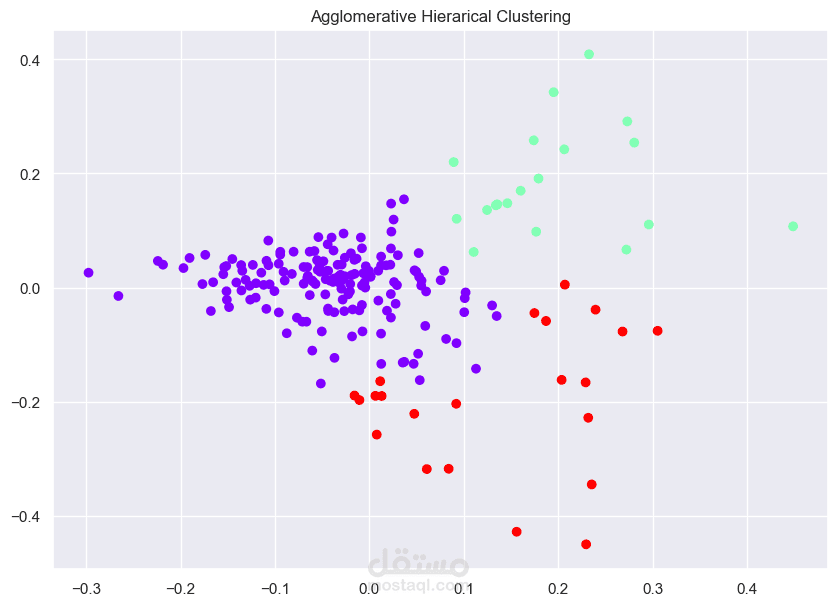
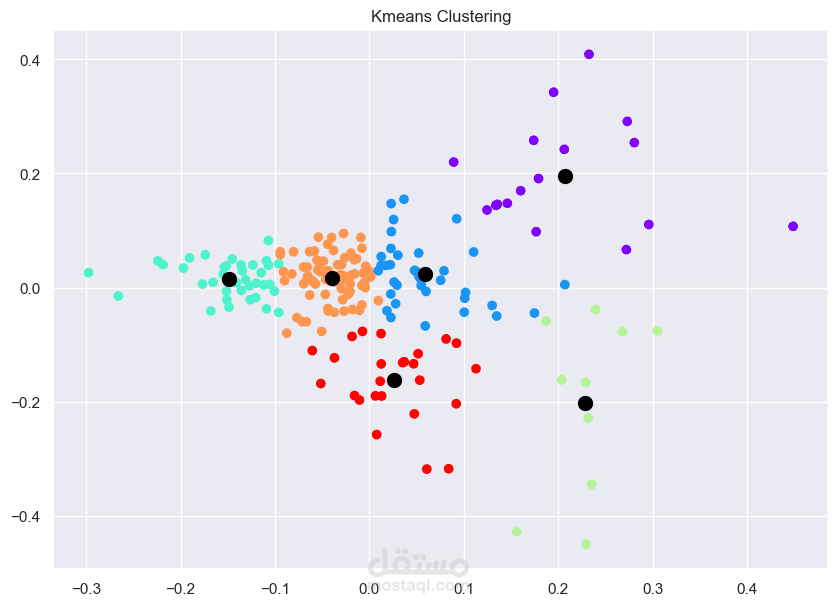
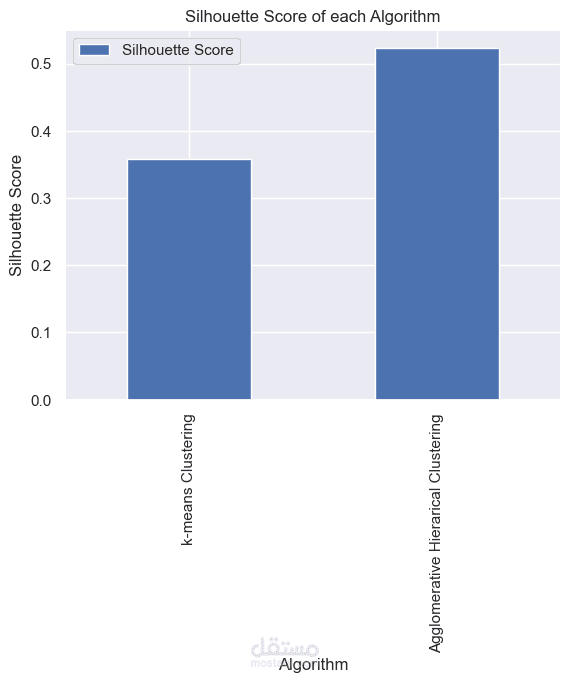
This project focuses on clustering news articles using NLP techniques. The process begins with data cleaning, where unnecessary columns are dropped and feature engineering is applied. Text preprocessing follows, including tokenization, stopword removal, and stemming. The cleaned text is then converted to numerical data using TF-IDF vectorization. For clustering, both KMeans++ and Agglomerative Hierarchical Clustering algorithms are used to group similar news articles, with the aim of uncovering hidden patterns in the data and improving clustering performance.