recommendation system
تفاصيل العمل

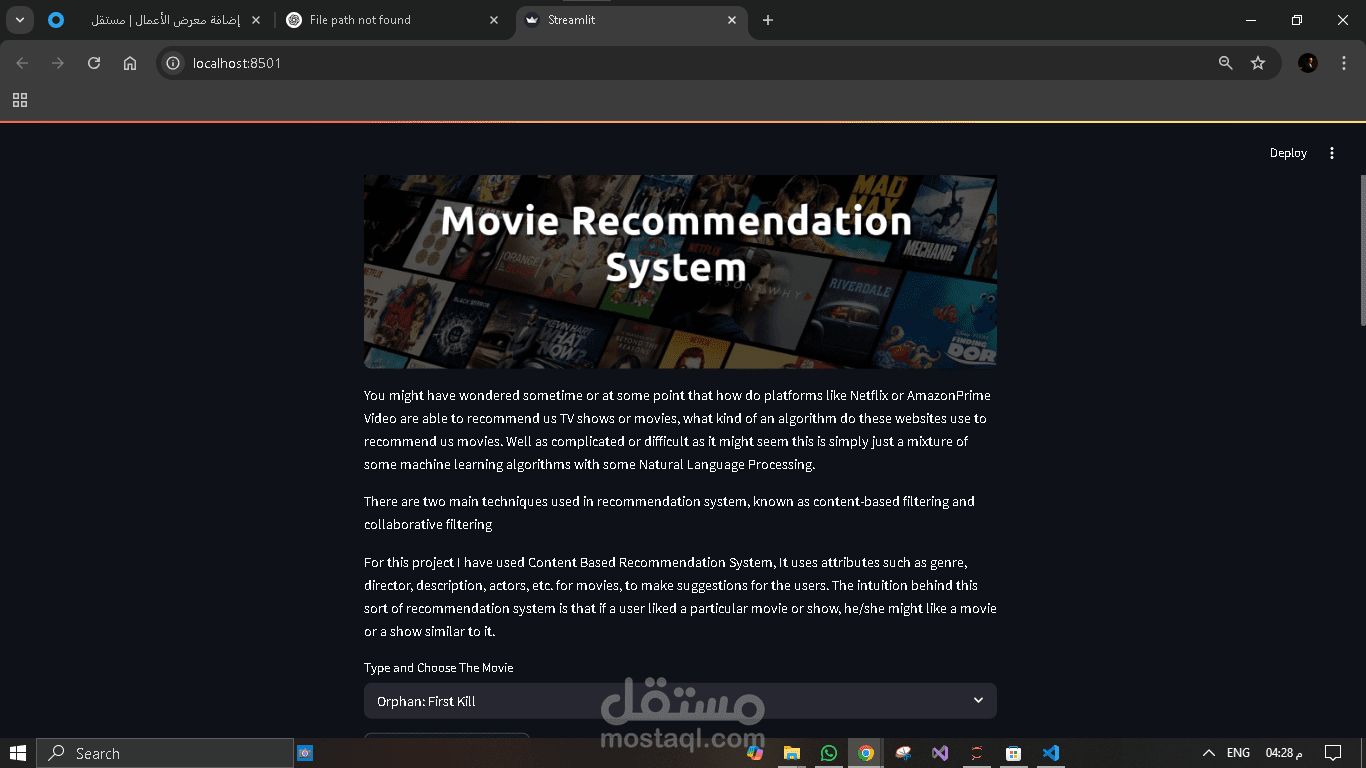
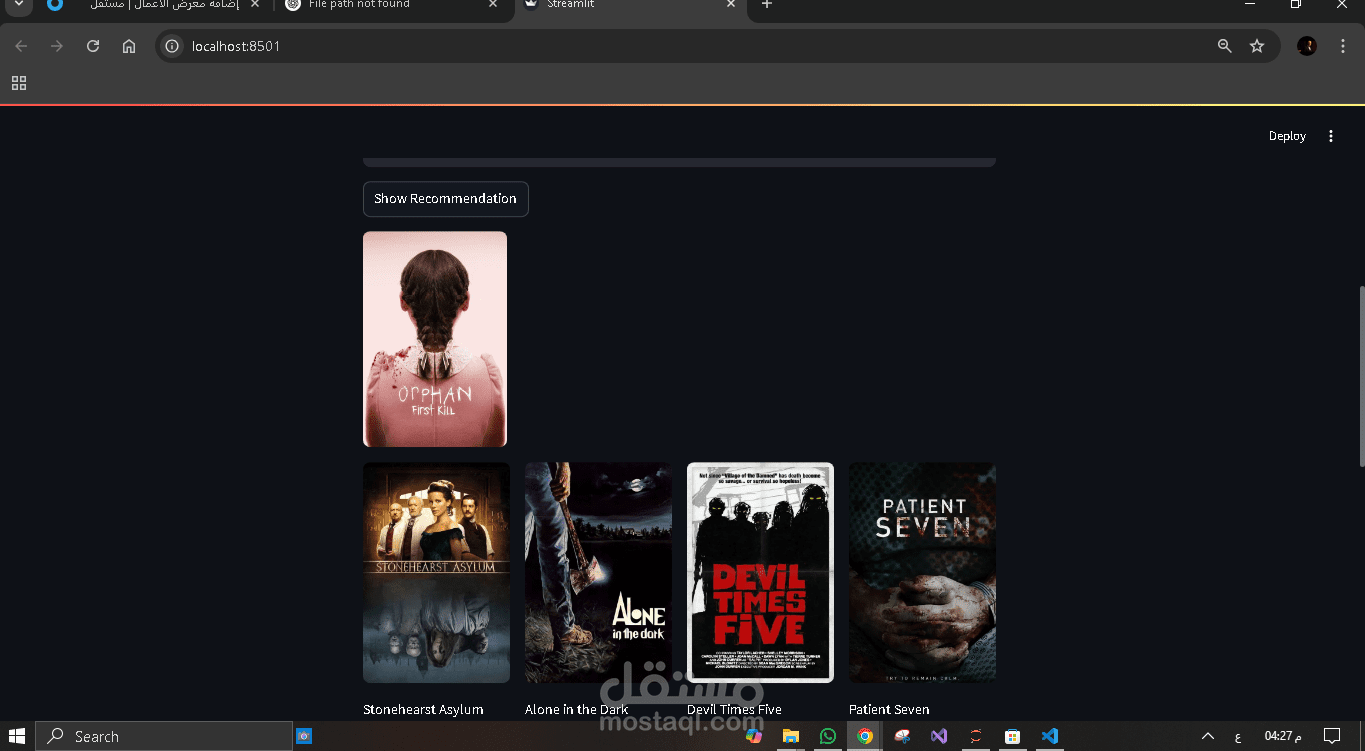
ده مشروع عامل زي اللي بيشغّلوه على مواقع زي "نتفليكس" أو "شاهد"، وهو نظام بيقترح أفلام على المستخدم حسب اللي اتفرّج عليه أو الأفلام اللي عجِبته قبل كده.
إنتَ جايب ملف فيه بيانات أفلام كتير (زي العنوان، النوع، الكلمات المفتاحية، التقييمات، عدد الأصوات...)، وبدأت تنظف وتفلتر البيانات علشان تتخلص من الحاجات المكررة أو اللي فيها نواقص.
بعد كده، جمعت كل المعلومات المهمّة عن كل فيلم (زي القصة، النوع، اللغة، والكلمات المفتاحية...) في عمود واحد اسمه tags، وبعدها عملت "معالجة نصوص" علشان تبقى سهلة للتحليل.
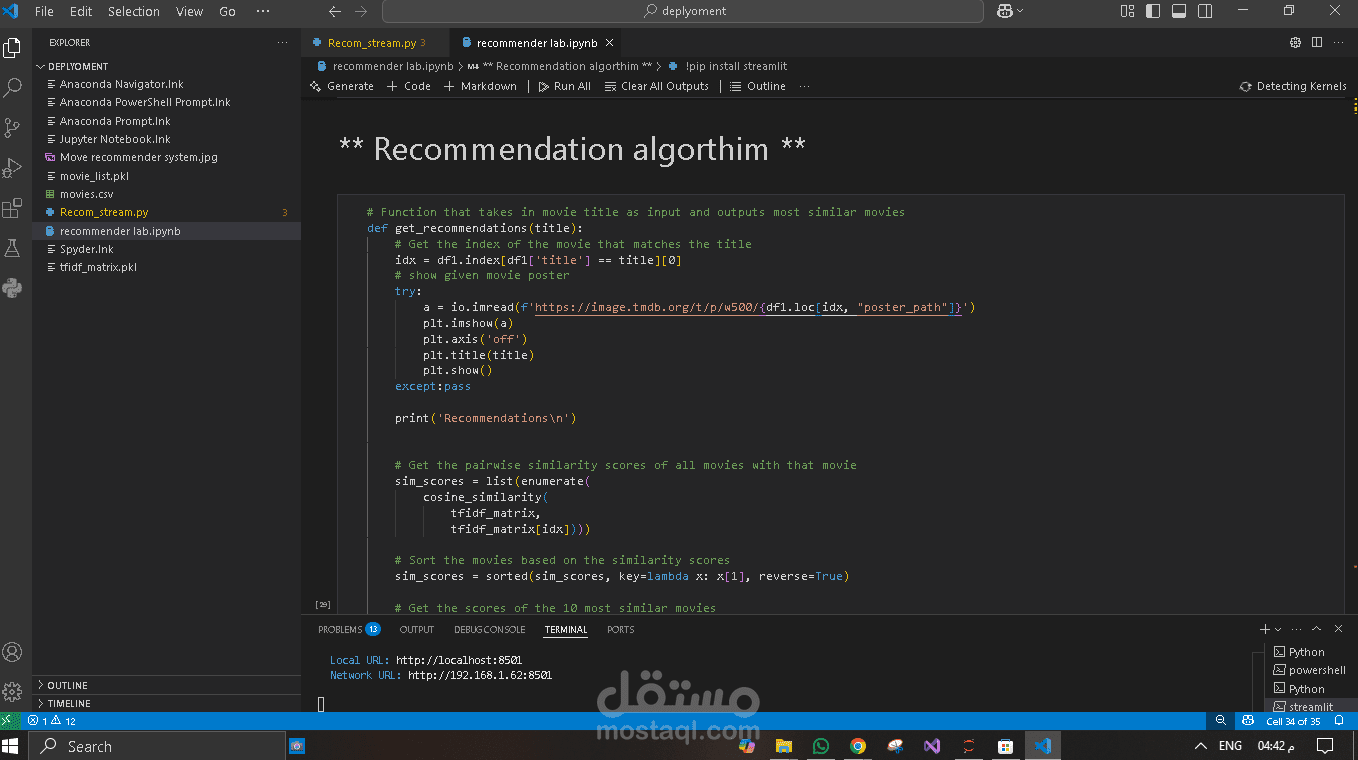
واستخدمت خوارزمية اسمها TF-IDF علشان تفهم كل فيلم بيتكلم عن إيه، وبعدين خوارزمية cosine similarity علشان تعرف إيه الأفلام اللي شبه بعض.
وفي الآخر، كتبت دالة تاخد اسم فيلم كمُدخل، وتطلعلك الأفلام اللي شبهه وتقترحها للمستخدم.
الادوات الي استخدمتها :
Python + Jupyter Notebook
مكتبات: pandas, numpy, nltk, scikit-learn, matplotlib, seaborn
تحليل بيانات وتنضيفها
معالجة نصوص (Text Processing)
بناء نموذج توصية بالأفلام (Content-Based Recommendation System)