Data Preprocessing
تفاصيل العمل
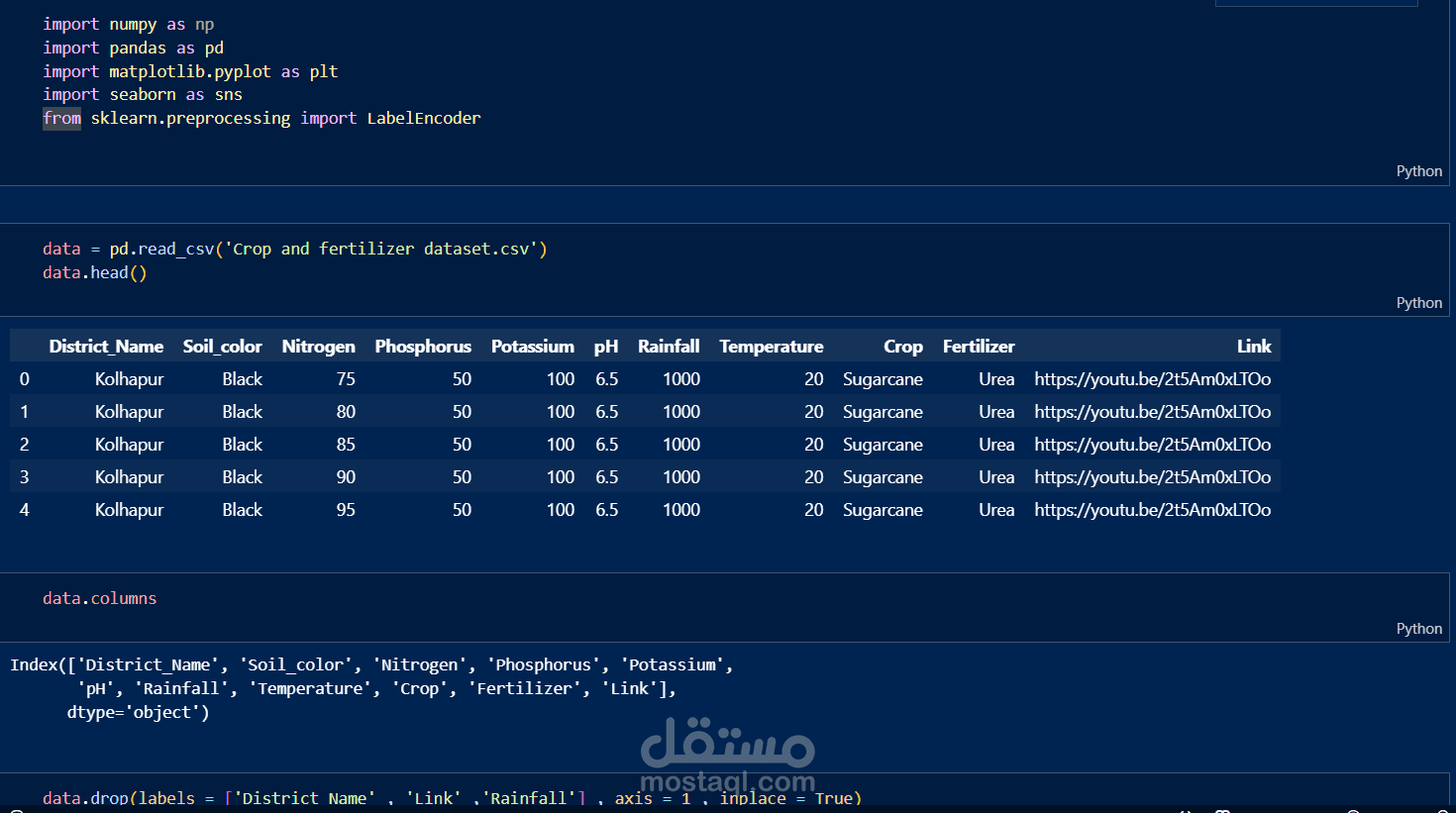
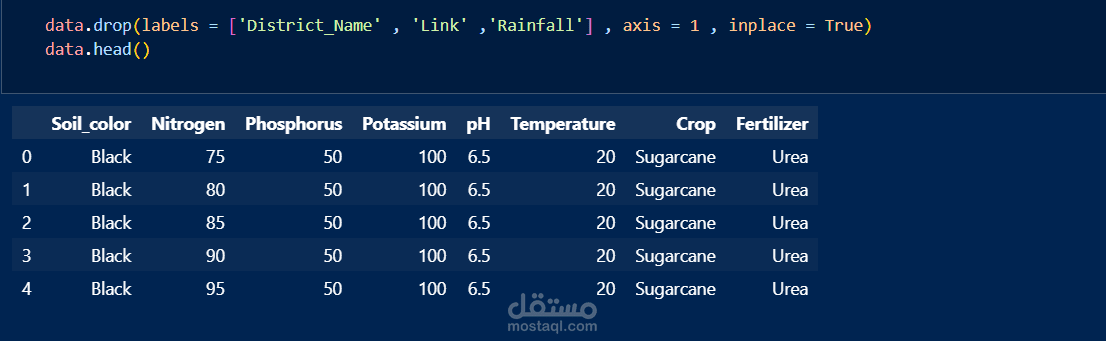
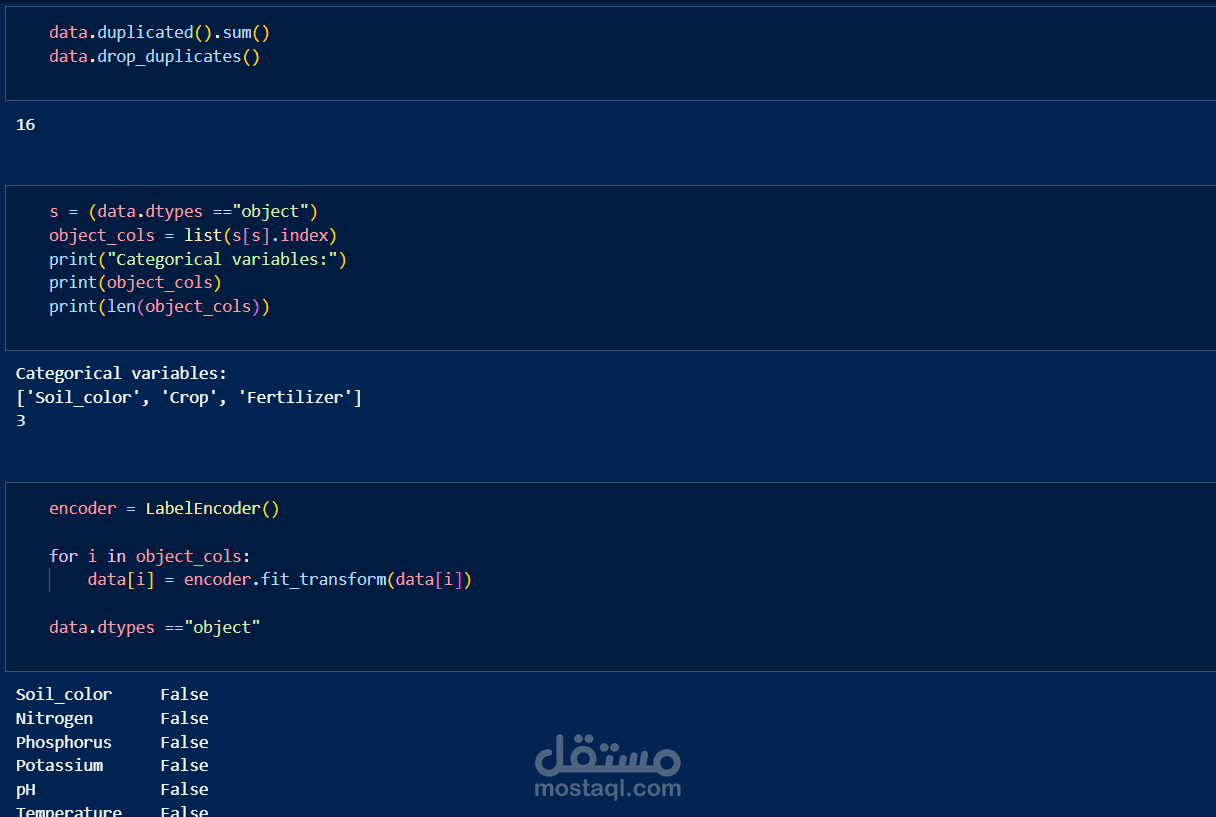
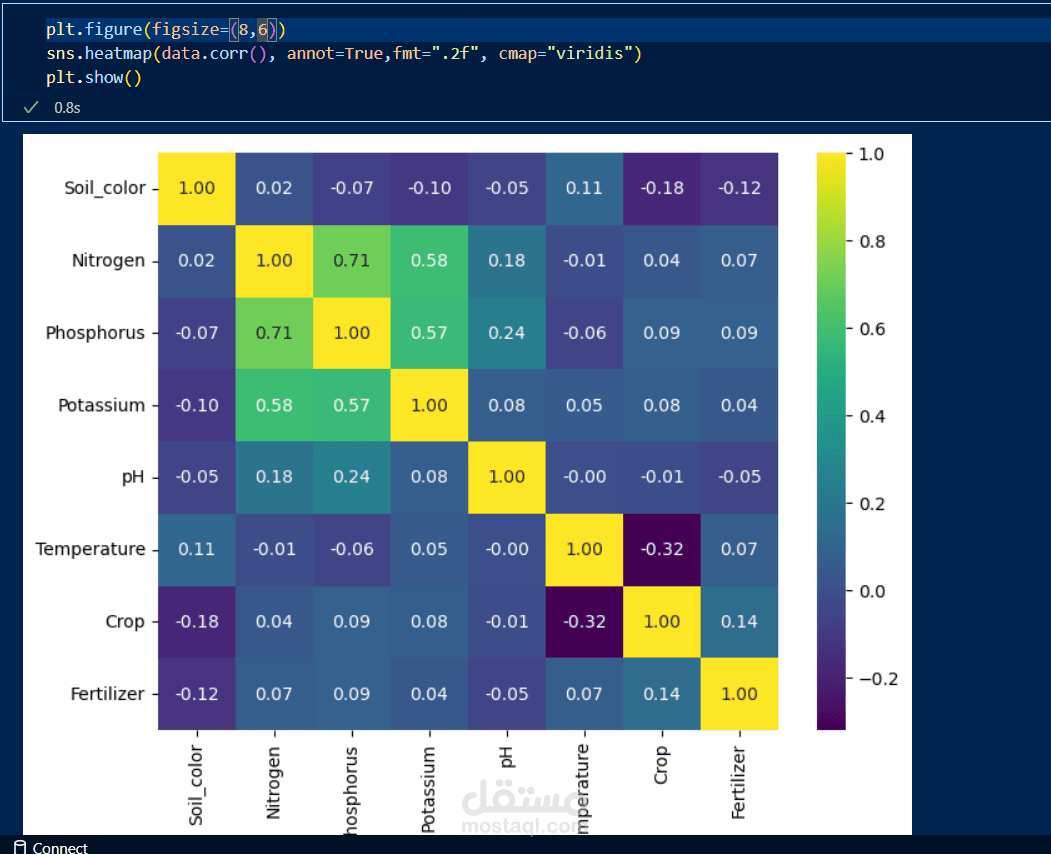
This Jupyter Notebook outlines the data preprocessing steps undertaken for the Crop and Fertilizer Recommendation System. The preprocessing ensures that the dataset is clean, consistent, and suitable for training machine learning models.
Key Steps:
Data Loading: Importing the dataset into the environment for analysis.
Exploratory Data Analysis (EDA): Examining the dataset to understand its structure, identify missing values, and detect anomalies.
Data Cleaning: Handling missing values, correcting inconsistencies, and removing duplicates to ensure data quality.
Feature Engineering: Creating new features or modifying existing ones to enhance model performance.
Encoding Categorical Variables: Transforming categorical features into numerical representations suitable for machine learning algorithms.
Feature Scaling: Normalizing or standardizing features to ensure that all variables contribute equally to the model.
This preprocessing pipeline is crucial for building an effective recommendation system that can accurately suggest suitable crops and fertilizers based on input conditions.