TutorPilot - AI Self-Improving Lesson Planning Agent
تفاصيل العمل
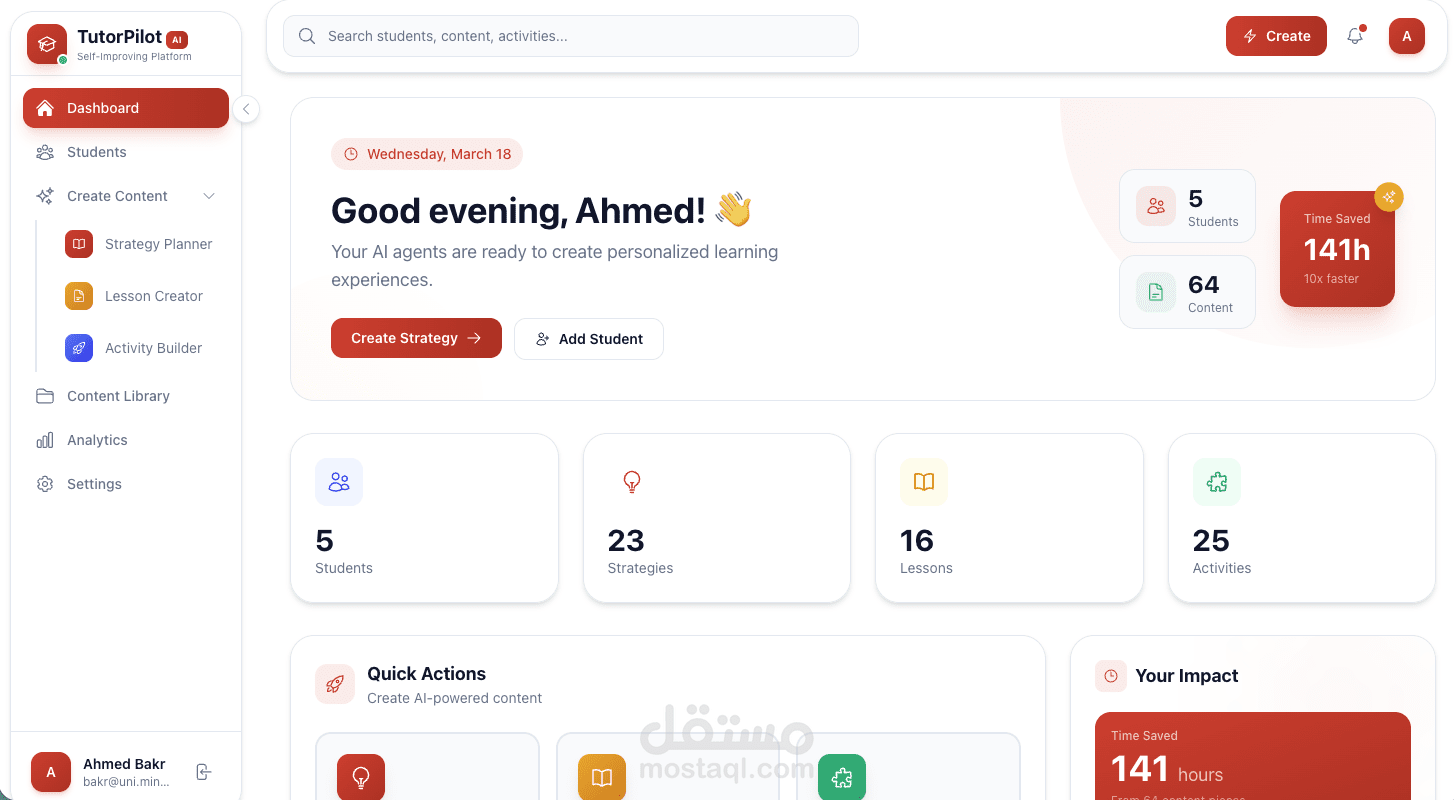
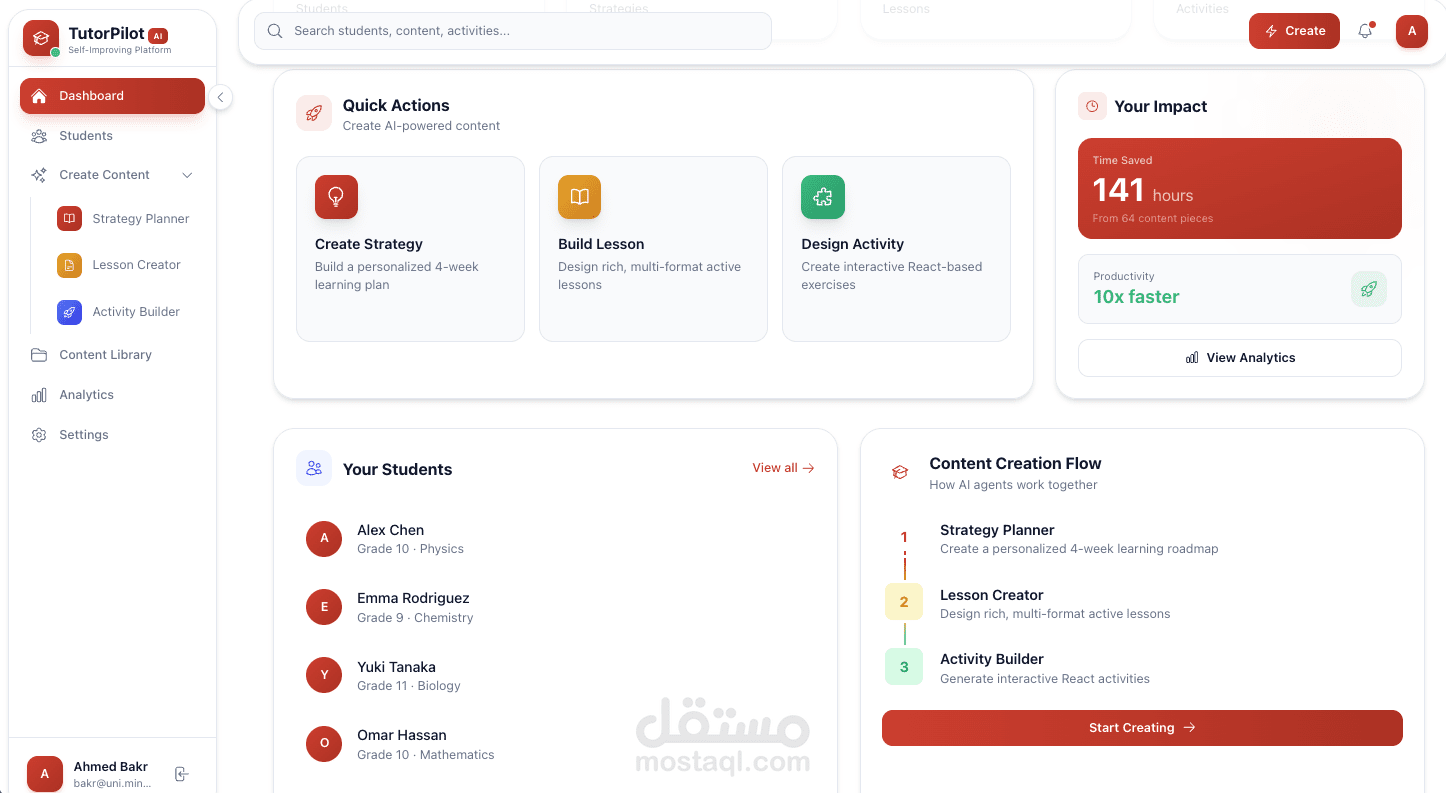
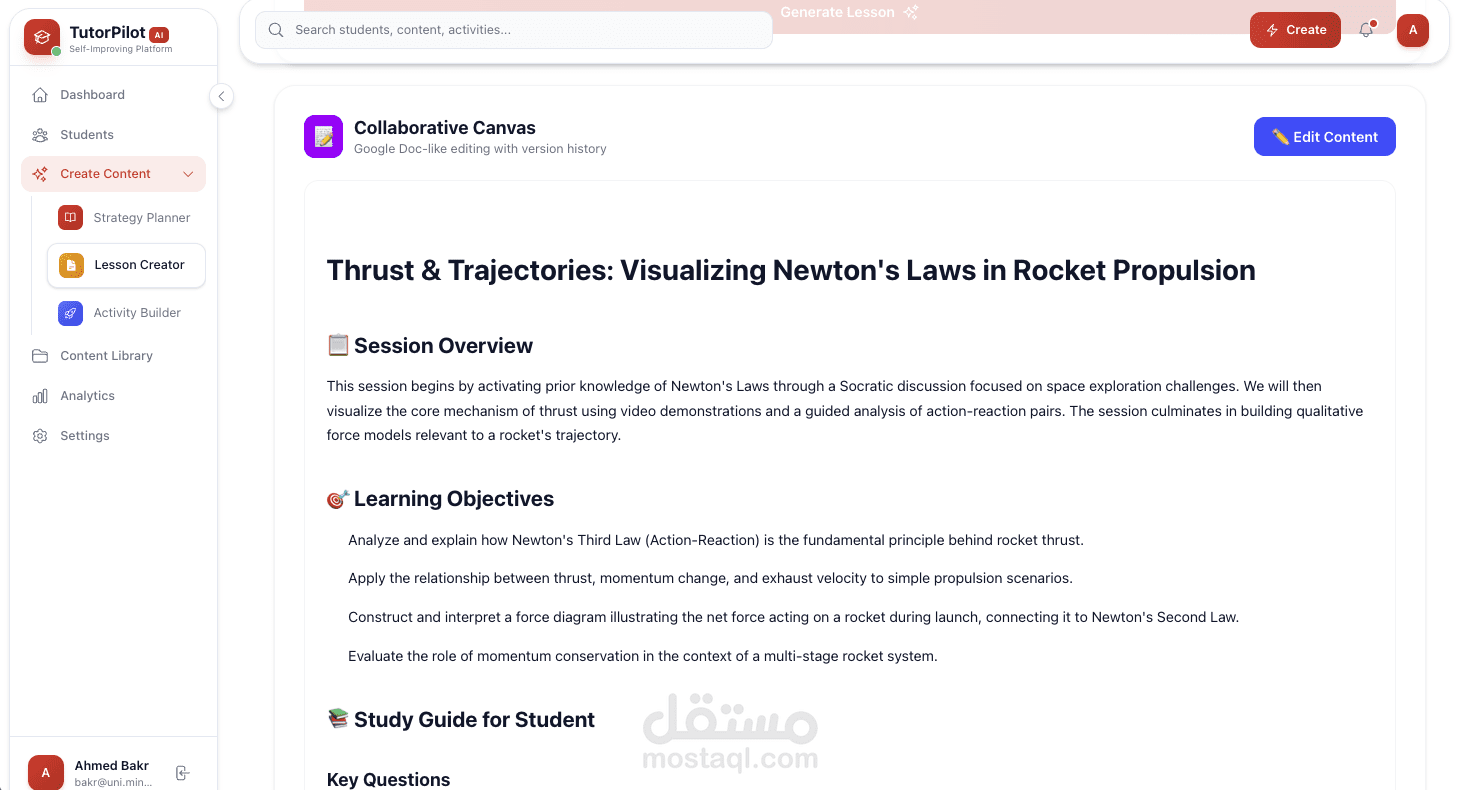
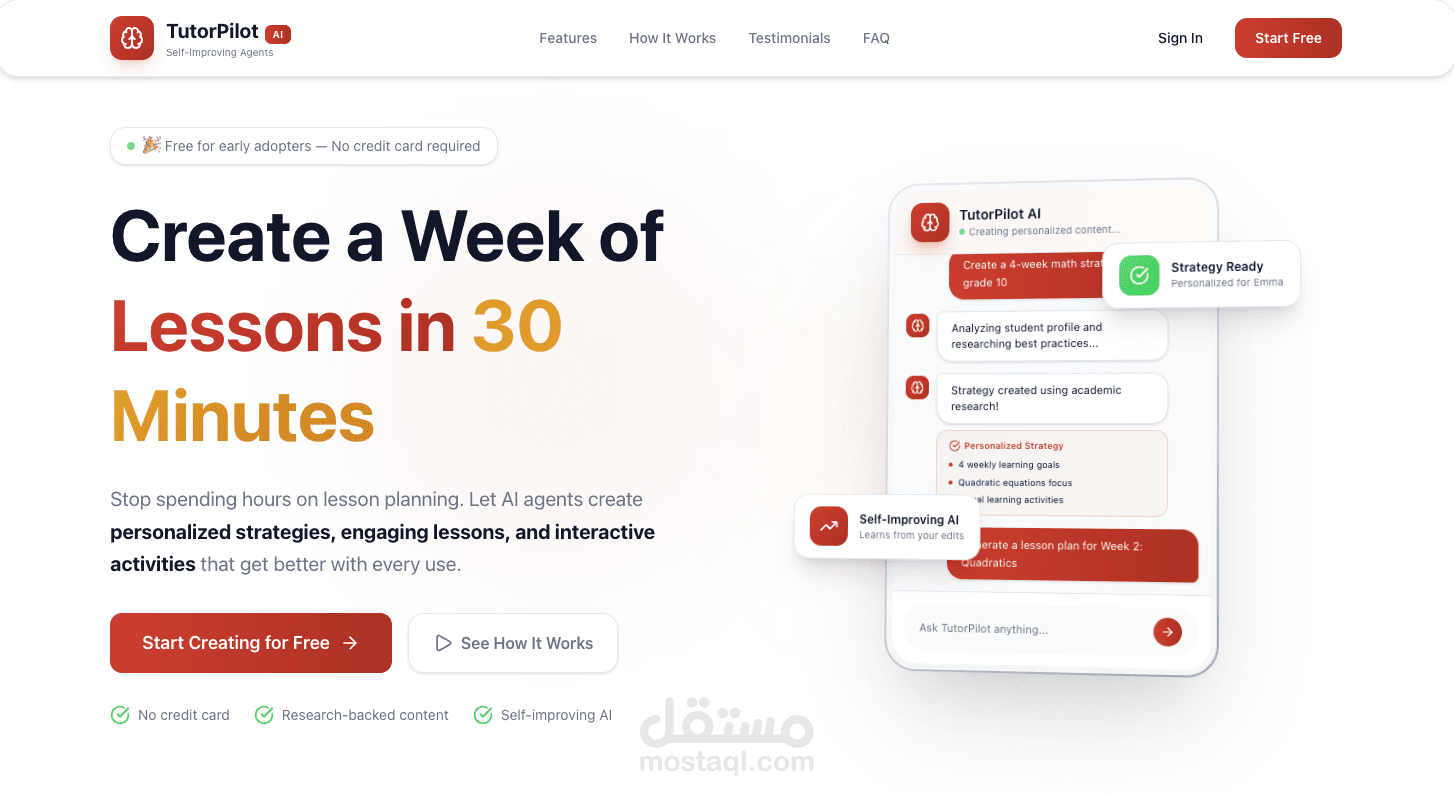
Built a self-improving multi-agent tutoring system using FastAPI with hierarchical context handoff (Strategy → Lesson → Activity agents), implementing dual-reward reinforcement learning from autonomous self-evaluation metrics (6 pedagogical criteria per generation) and tutor feedback captured via version history with explicit edit notes, feeding pattern analysis through LearnLM reflection service that generates actionable insights injected into adaptive prompts—reducing repeated mistakes by 40% and improving engagement scores from 6.5→8.5 average across 50+ generations
Engineered auto-debugging code generation pipeline with Qwen3 Coder 480B + Daytona sandboxes for interactive React simulations (chemistry games, physics playgrounds), implementing 3-attempt error recovery loop that reads sandbox logs and self-fixes deployment failures (85% success rate), integrated with Weave observability tracing all AI calls and agentic memory system storing confidence-weighted student patterns (attention spans, learning styles, cultural context) retrieved via tool calling for dynamic personalization.