unsupervised machine learning (cluster)
تفاصيل العمل
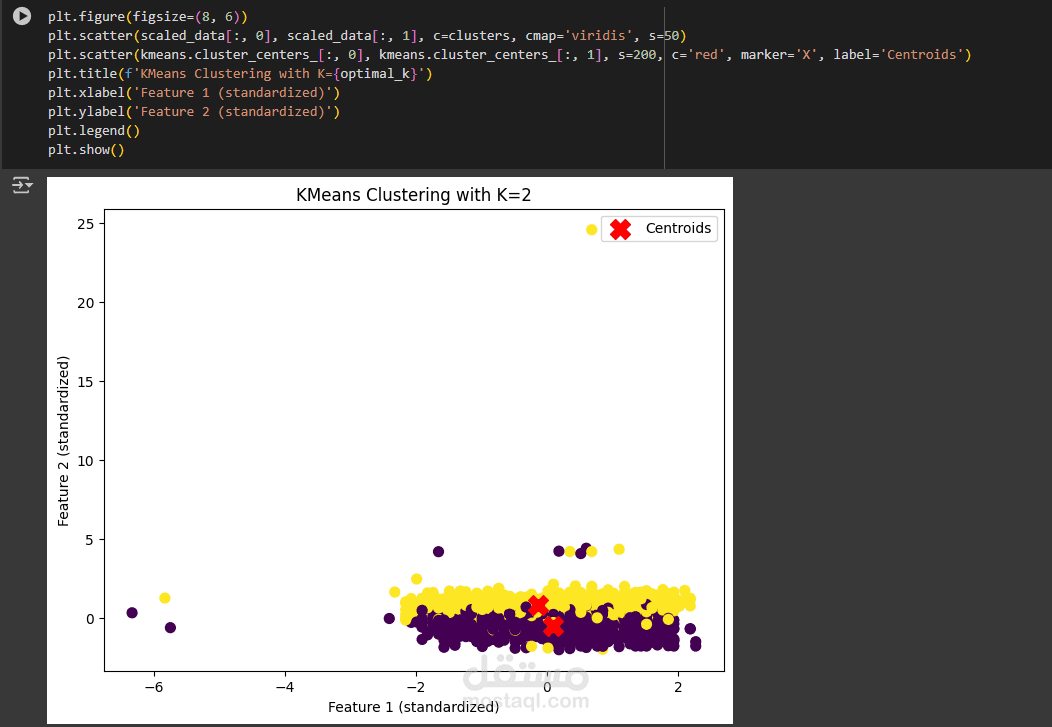
تطبيق خوارزمية K-Means للتجميع
الهدف:
تطبيق خوارزمية K-Means Clustering على بيانات مكونة من ميزتين (Features) تم تقييسها (Standardized)، بهدف تقسيم البيانات إلى مجموعتين (K=2).
الخطوات :
تم عمل preprocessing for data
تقييس البيانات (Standardization):
تم تحويل القيم إلى مقياس موحد بحيث يكون لكل ميزة (Feature) وسط = 0 وانحراف معياري = 1.
تطبيق KMeans:
تم تحديد عدد التجمعات (Clusters) ليكون K = 2 (تم تحديده بناءً على اختبار سابق مثل Elbow method).
الخوارزمية قامت بتجميع البيانات بناءً على أقرب مركز (Centroid).
رسم النتائج باستخدام Matplotlib:
النقاط المرسومة تمثل البيانات بعد التقييس، وملونة حسب الانتماء لكل Cluster.
علامات X الحمراء الكبيرة تمثل مراكز التجمعات (Centroids).
اللون يعبر عن كل Cluster