بوت للتحدث مع الملفات الخاصه
تفاصيل العمل
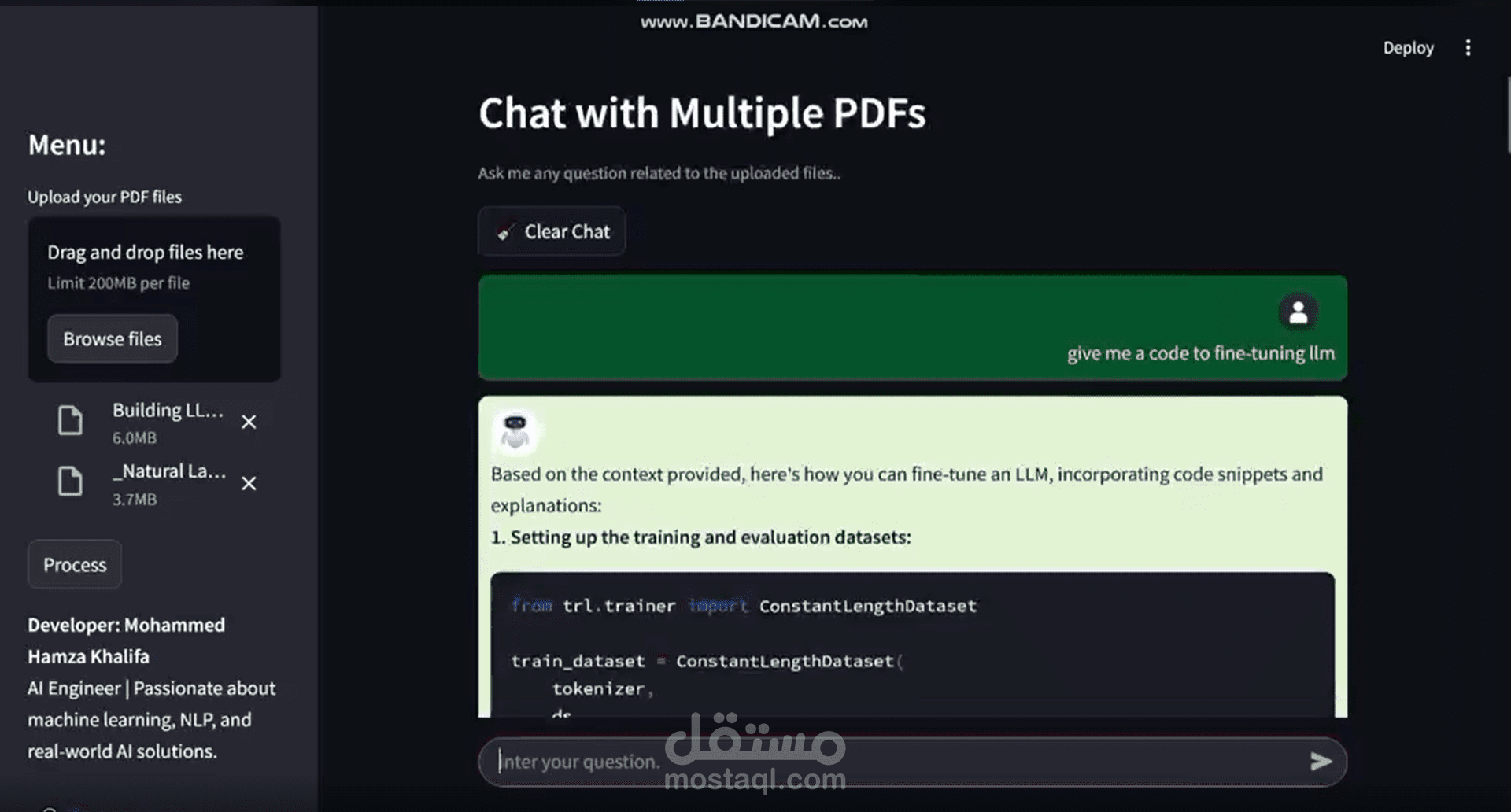
يهدف هذا التطبيق إلى تمكين المستخدمين من التفاعل بشكل طبيعي وذكي مع مستندات PDF متعددة في وقت واحد، وذلك باستخدام تقنيات متقدمة في مجال الذكاء الاصطناعي ومعالجة اللغة الطبيعية (NLP). يقوم النظام بقراءة واستخلاص المحتوى النصي من المستندات، ثم يُحوّله إلى تمثيلات عددية باستخدام تقنيات التضمين الشعاعي (Vector Embeddings)، مما يسمح بفهم عميق للسياق والمعنى.
بعد المعالجة، يمكن للمستخدمين طرح أي عدد من الأسئلة باللغة الطبيعية، وسيتولى النظام تحليل السؤال، البحث في المستندات ذات الصلة، ثم توليد إجابة دقيقة وسياقية بناءً على المعلومات المتوفرة في الملفات. يدعم التطبيق استرجاع المعلومات من مستندات متعددة بشكل متزامن، مما يجعله أداة مثالية للباحثين، المحامين، الطلاب، أو أي شخص يحتاج إلى تحليل كمية كبيرة من البيانات النصية بطريقة سريعة وفعالة.
كما يتميز النظام بسهولة الاستخدام من خلال واجهة تفاعلية بسيطة تُمكّن المستخدم من تحميل المستندات، كتابة الأسئلة، والحصول على الردود فورًا، مما يجعل عملية البحث والفهم أكثر سلاسة وذكاء.