Web Scraping لموقع TechCrunch لاستخراج العناوين والمحتويات
تفاصيل العمل
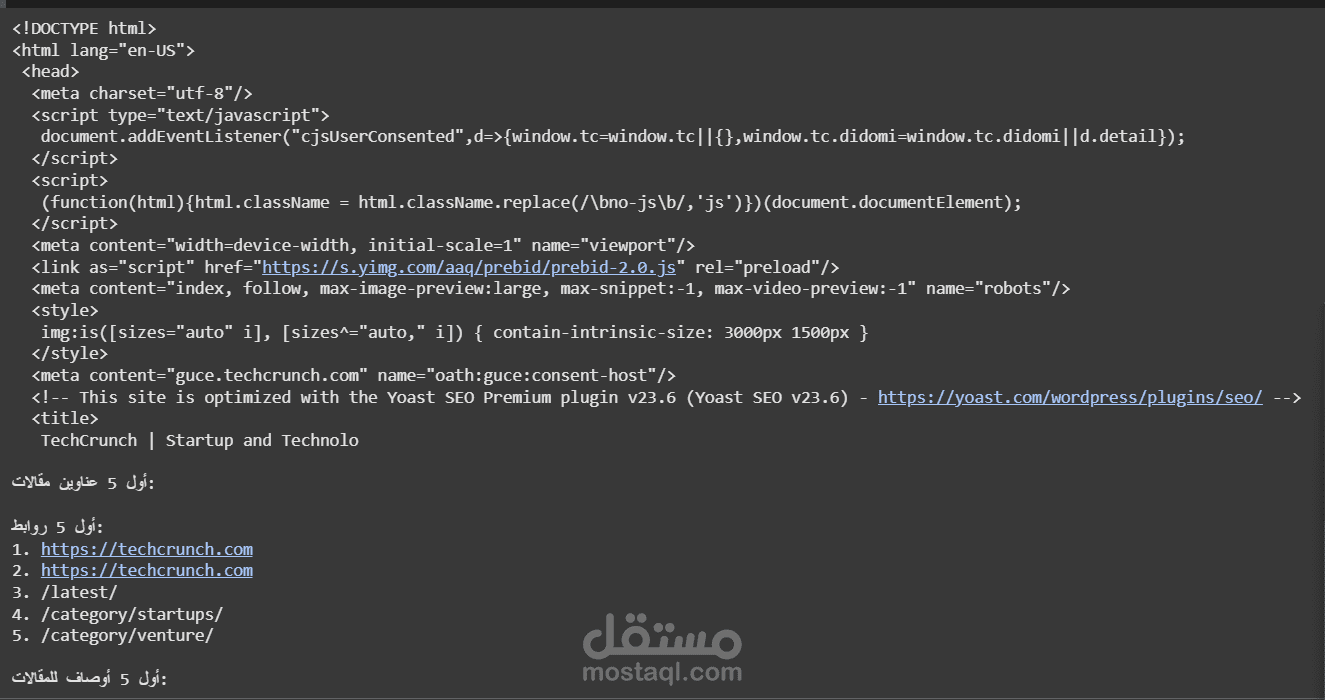
في هذا المشروع، سأقوم باستخدام تقنيات Web Scraping لجمع البيانات من موقع TechCrunch، أحد أكبر المواقع المتخصصة في أخبار التكنولوجيا. سأقوم بتطوير سكربت باستخدام لغة البرمجة Python ومكتبات BeautifulSoup و requests لاستخراج العناوين الرئيسية للمقالات، الروابط الخاصة بالمقالات، وأوصاف المقالات. سيتيح لك هذا السكربت الحصول على رؤى محدثة حول أحدث المواضيع التكنولوجية التي يتم نشرها على الموقع.
الخطوات:
إرسال طلب للحصول على بيانات الموقع: باستخدام مكتبة requests لإرسال طلب إلى موقع TechCrunch.
تحليل الصفحة باستخدام BeautifulSoup: استخراج البيانات الهيكلية من الصفحة وتحديد العناصر المناسبة مثل العناوين والروابط.
استخراج العناوين الرئيسية: جمع العناوين المرتبطة بالمقالات الأكثر أهمية في الموقع.
استخراج الروابط: تحديد الروابط المتعلقة بالمقالات لتوجيه المستخدمين إليها مباشرة.
استخراج أوصاف المقالات: جمع الأوصاف القصيرة للمقالات لتوفير فكرة عن محتوى كل مقال.
تفاصيل إضافية:
الهدف من المشروع: مساعدة الشركات أو الأفراد في متابعة أحدث الأخبار التكنولوجية دون الحاجة للتصفح اليدوي المستمر للموقع.
تصدير البيانات: يمكن تصدير البيانات المستخرجة إلى ملف CSV أو Excel حسب طلب العميل.
الخصائص الإضافية: إمكانية تخصيص السكربت لاستخراج معلومات أخرى أو تصفية المقالات حسب الكلمات المفتاحية.
ملاحظة: يمكن تخصيص السكربت ليعمل مع مواقع أخرى أو لتوسيع نطاق البيانات المستخرجة.