التحكم في العربة Cart-pole باستخدام الذكاء الاصطناعي
تفاصيل العمل


العنوان: التعلم المعزز للتحكم في عربة-قطب باستخدام بيئة Gym
Reinforcement learning
**الوصف:**
في هذا المشروع، تم تطوير نموذج تعلم معزز متقدم للتحكم في بيئة عربة-قطب (CartPole) داخل مكتبة OpenAI Gym. تم استخدام خوارزمية الشبكة العصبية العميقة المزدوجة Double Deep Q-Network (DDQN) لضمان أداء مستقر ومتفوق.
**أبرز ميزات المشروع:**
- **الهندسة المميزة**: تم تنفيذ تقنيات هندسة مميزة متقدمة لاستخراج ميزات جديدة مهمة، مثل اتجاه الحركة، مما عزز قدرة النموذج على اتخاذ القرارات.
- **تكديس الحالات**: تم استخدام تقنية تكديس الحالات (State Stacking) لتمكين الوكيل من استيعاب الحالات الحالية والتاريخية، مما أدى إلى تحسين القدرة التنبؤية.
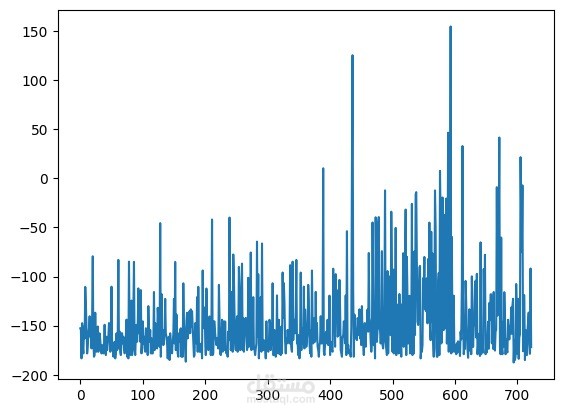
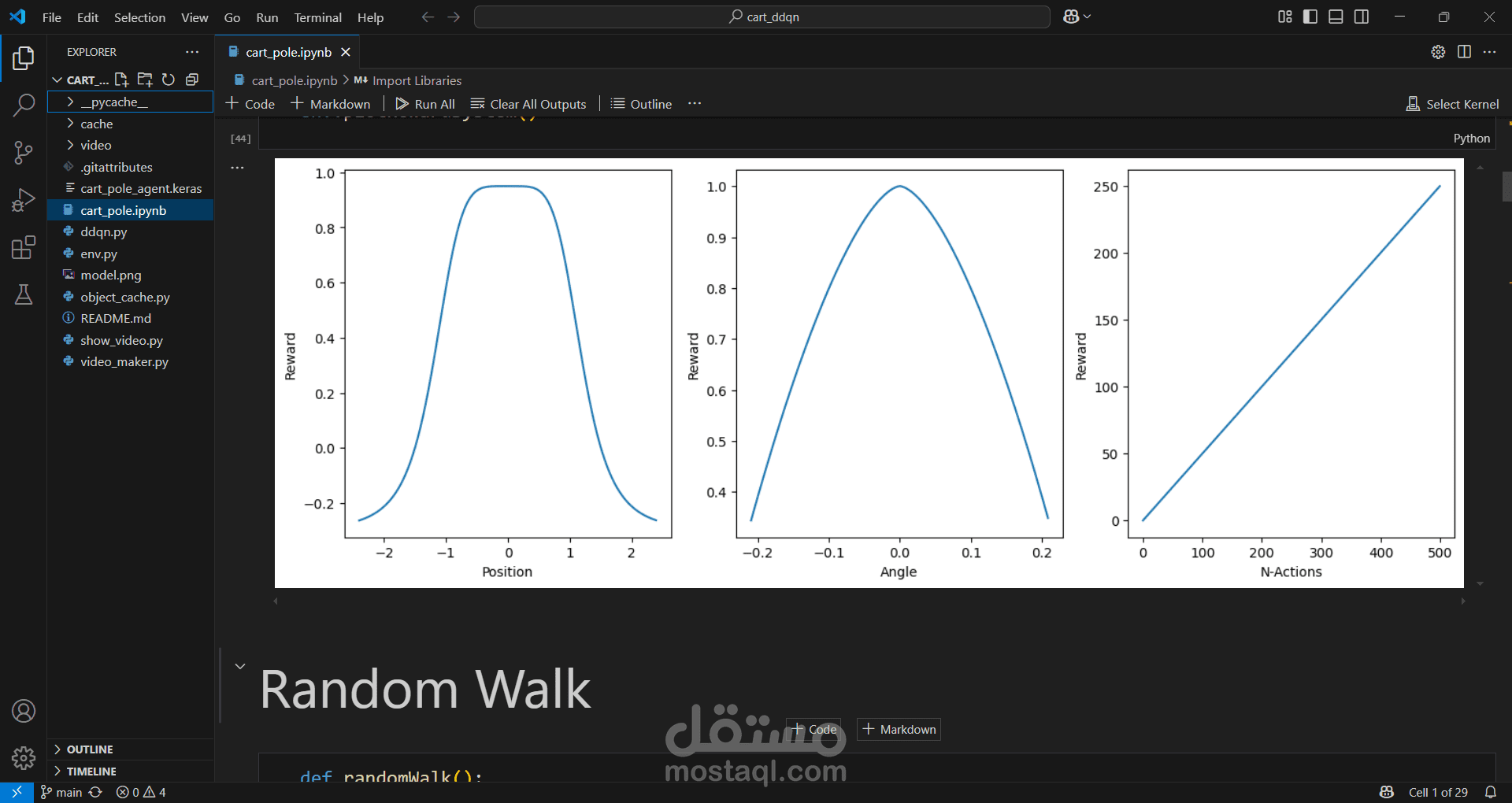
- **إعادة تعريف نظام المكافآت**: تم تعديل هيكل المكافآت استنادًا إلى عوامل مثل موضع العربة، الزمن المستغرق، وزاوية القطب، مما ساعد في تحقيق تحكم أكثر دقة وأداء متوازن.
- **آلية التحديث**: استخدمت مجموعة من طرق التحديث اللين (Soft Update) والتحديث الصلب (Hard Update) لاستهداف الشبكة العصبية بكفاءة والحفاظ على الأداء الأمثل خلال عملية التعلم.
- **انخفاض إبسيلون (Epsilon Decay)**: تم تطبيق تقنية انخفاض إبسيلون ضمن استراتيجية الاستكشاف والاستغلال (Epsilon-Greedy)، مما ساعد في تحقيق تعلم قوي ومستقر.
**النتيجة:**
أدت هذه التقنيات إلى تطوير وكيل ذكاء اصطناعي فعال وقادر على التحكم في مهمة عربة-قطب بكفاءة عالية ومرونة ملحوظة. إذا كنت بحاجة إلى مساعدة إضافية في جوانب مثل الكود أو التحليل، أنا هنا لدعمك!