twitter_Sentiment_Analysis
تفاصيل العمل


**نظرة عامة (Overview)**
يركّز هذا المشروع على بناء نموذج تعلّم آلي لتحليل المشاعر باستخدام بيانات من منصة تويتر. الهدف هو تصنيف التغريدات إلى مشاعر إيجابية أو سلبية أو محايدة باستخدام تقنيات معالجة اللغة الطبيعية (NLP) وخوارزمية Random Forest Classifier.
**التقنيات المستخدمة (Technologies Used)**
* Python
* Scikit-learn
* NLTK وRegular Expressions
* Pandas وNumPy
* Matplotlib وSeaborn
**سير العمل (Workflow)**
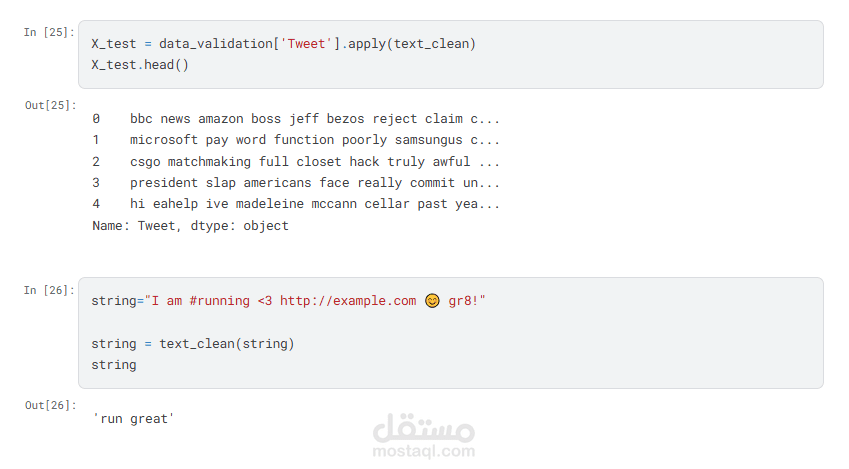
* تنظيف ومعالجة التغريدات (إزالة الضوضاء، الكلمات الشائعة، تطبيق Stemming، وغيرها)
* إجراء تحليل استكشافي للبيانات (EDA) لفهم توزيع المشاعر
* استخراج الميزات باستخدام TF-IDF Vectorizer
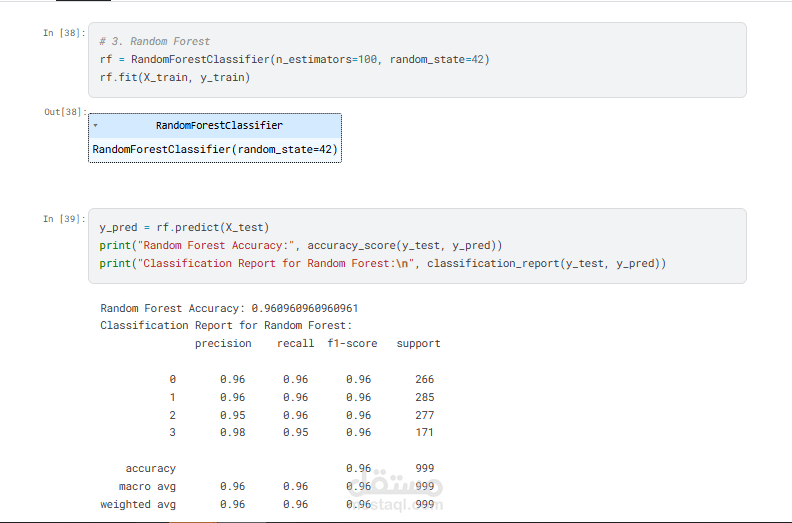
* تدريب عدة نماذج واختيار Random Forest Classifier نظرًا لأدائه المرتفع
* تقييم النموذج باستخدام مقاييس: Accuracy، Precision، Recall، وF1-score
**النتائج (Results)**
تم تحقيق دقة بلغت 96% على مجموعة الاختبار باستخدام Random Forest Classifier، مما يعكس أداءً قويًا في تصنيف المشاعر.
**التطبيقات (Applications)**
* مراقبة مشاعر المستخدمين على وسائل التواصل الاجتماعي وتحليل اتجاهات العلامات التجارية
* تحليل آراء العملاء
* أبحاث السوق والتحليل السياسي
* أنظمة الاستجابة الآلية المعتمدة على تحليل المشاعر