نماذج تعلم آلي لتوقع أسعار السيارات
تفاصيل العمل
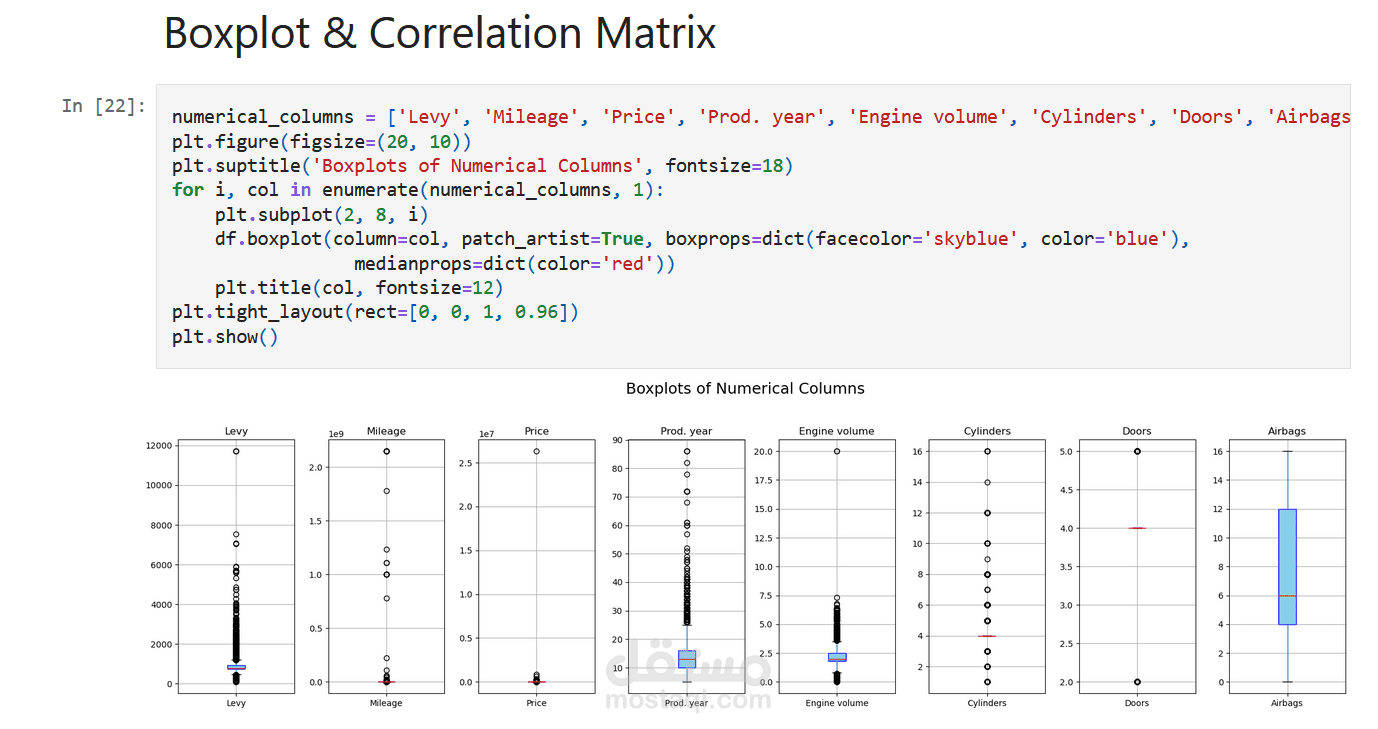
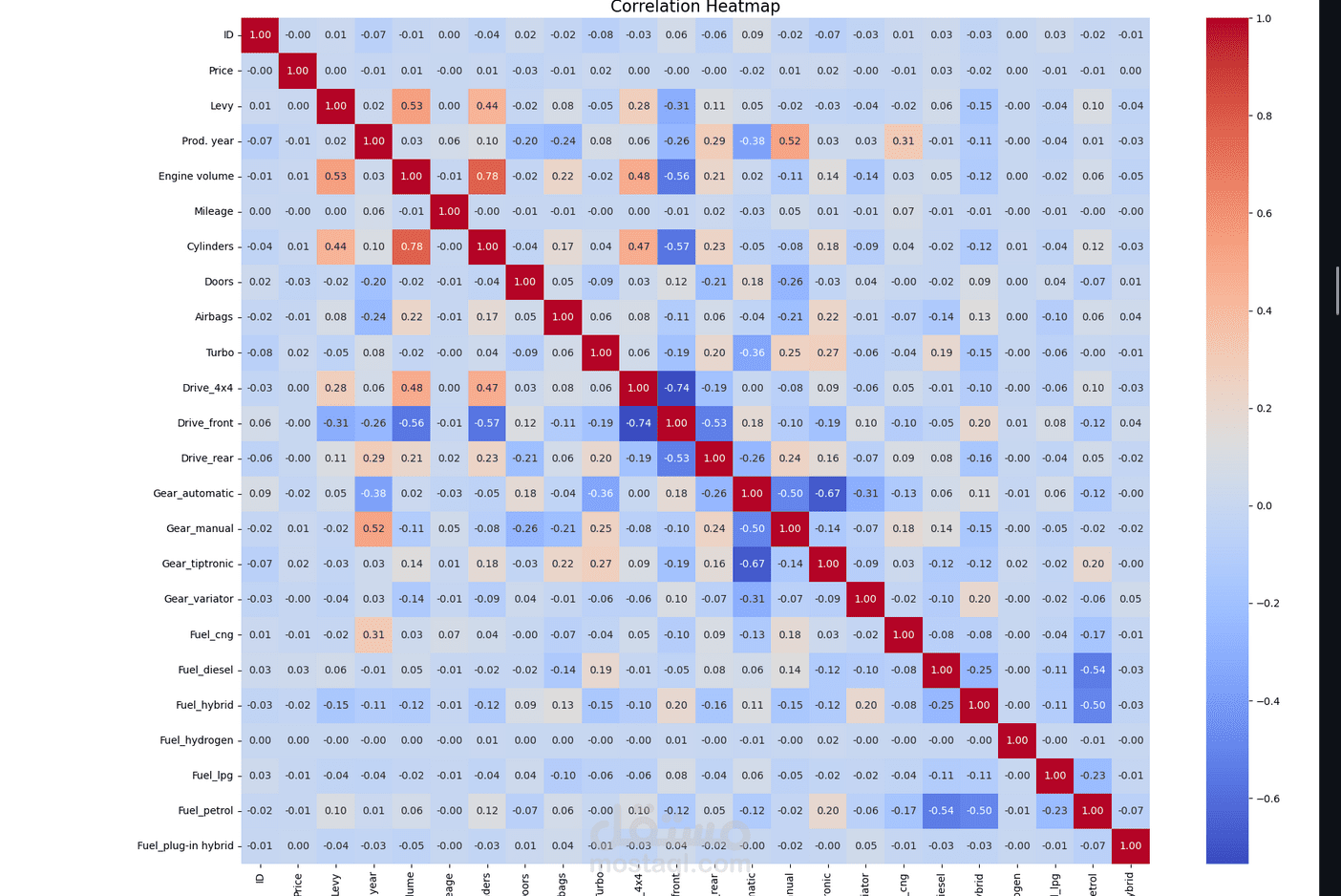
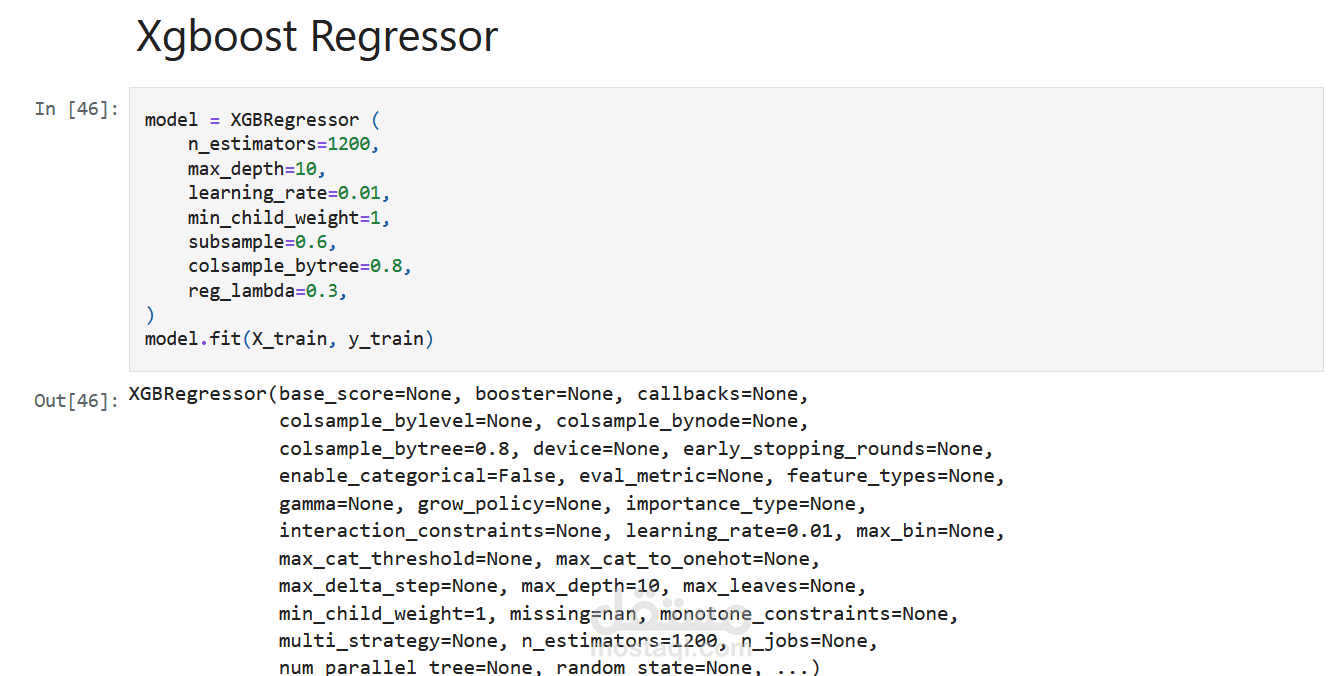
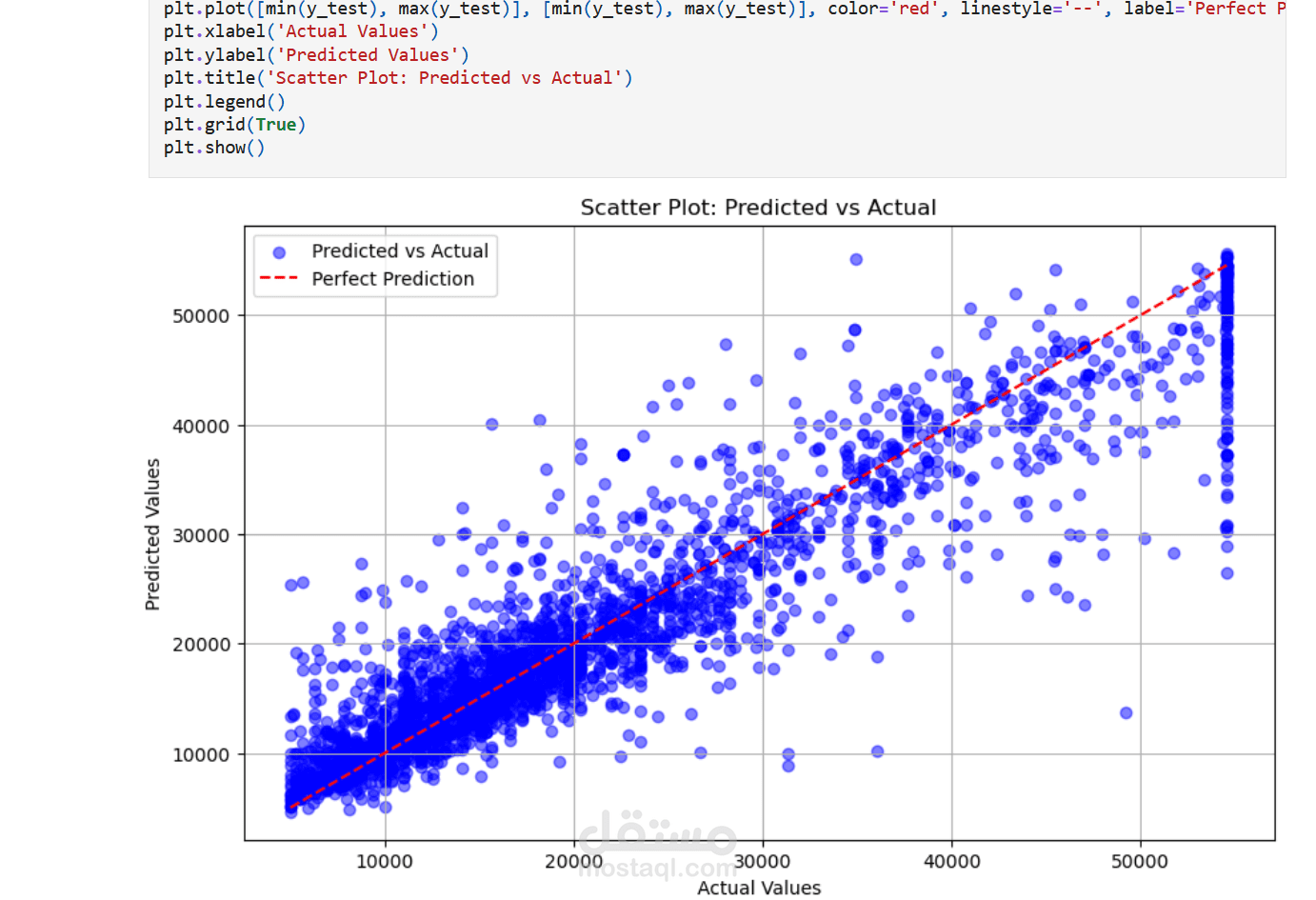
عملت على مشروع توقع أسعار السيارات باستخدام مجموعة بيانات ضخمة تحتوي على أكثر من 19,000 عينة و28 خاصية مختلفة.
تضمن العمل عدة مراحل رئيسية:
معالجة البيانات:
التعامل مع القيم المفقودة وتنظيف البيانات.
تجهيز الخصائص لاستخدامها في النماذج الإحصائية وخوارزميات التعلم الآلي.
تطوير نماذج الانحدار:
الانحدار الخطي (Linear Regression): لبناء نموذج بسيط يعتمد على علاقة خطية بين المتغيرات.
انحدار الجار الأقرب (K-Nearest Neighbors Regression): لبناء نموذج أكثر مرونة يعتمد على أقرب النقاط.
XGBoost Regressor: كنموذج متقدم لتعزيز النتائج وزيادة دقة التوقعات.
تقييم النماذج:
تم استخدام معايير تقييم مختلفة مثل:
متوسط الخطأ المطلق (MAE)
متوسط مربع الخطأ (MSE)
معامل التحديد (R-squared)
نتائج الأداء:
نموذج XGBoost Regressor حقق أفضل أداء مقارنة بباقي النماذج:
MAE: 3179
MSE: 24,318,060
R²: 0.85
مما يدل على قدرة النموذج العالية في توقع أسعار السيارات بدقة ممتازة.
التقنيات والأدوات المستخدمة:
Python
Scikit-Learn
XGBoost
Pandas & NumPy
Matplotlib & Seaborn
للاطلاع على الكود المصدري، يمكن زيارة مستودع المشروع على GitHub عبر رابط المعاينة.