مشروع تحليل المشاعر لنظام Learnwise
تفاصيل العمل
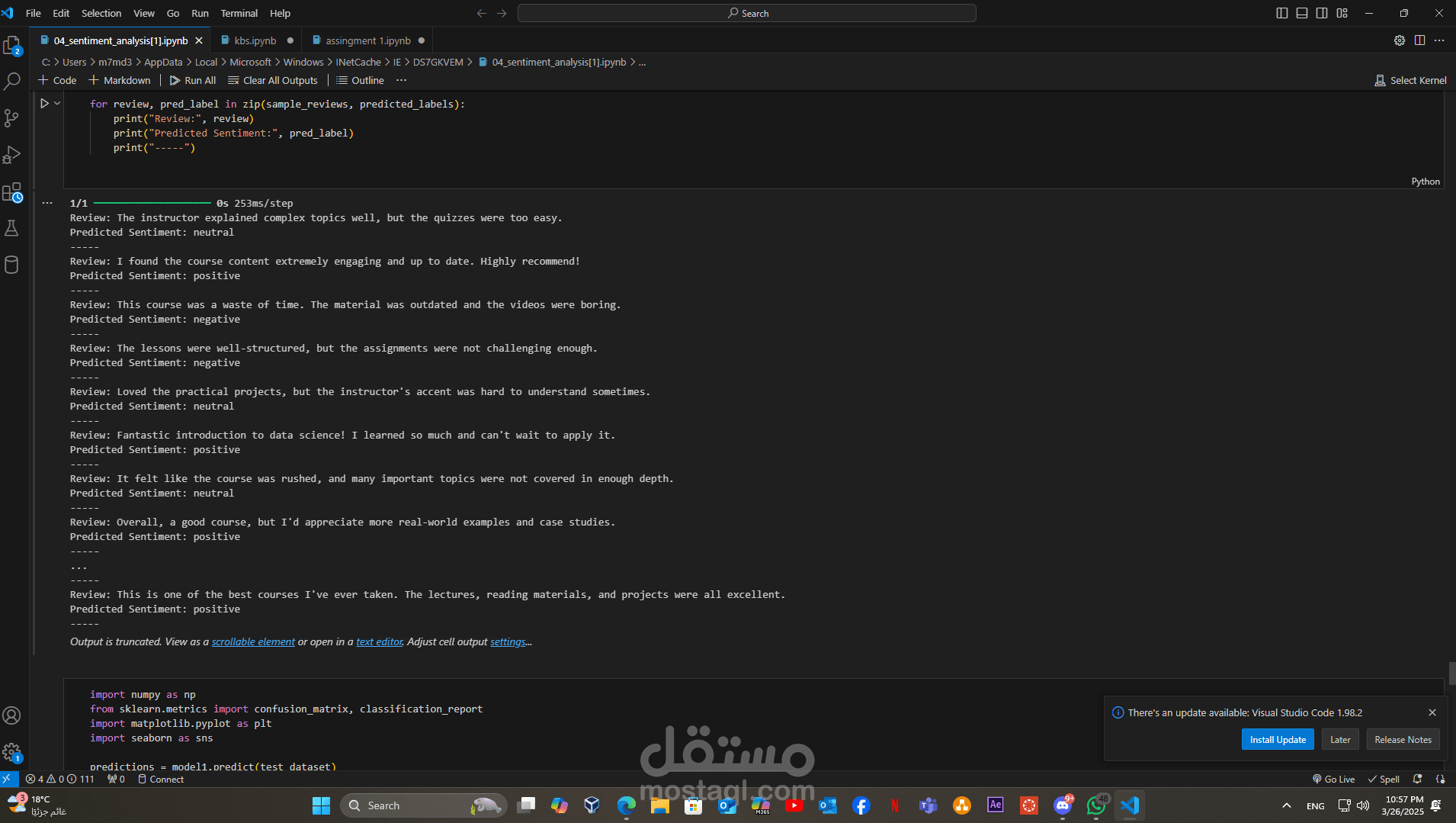
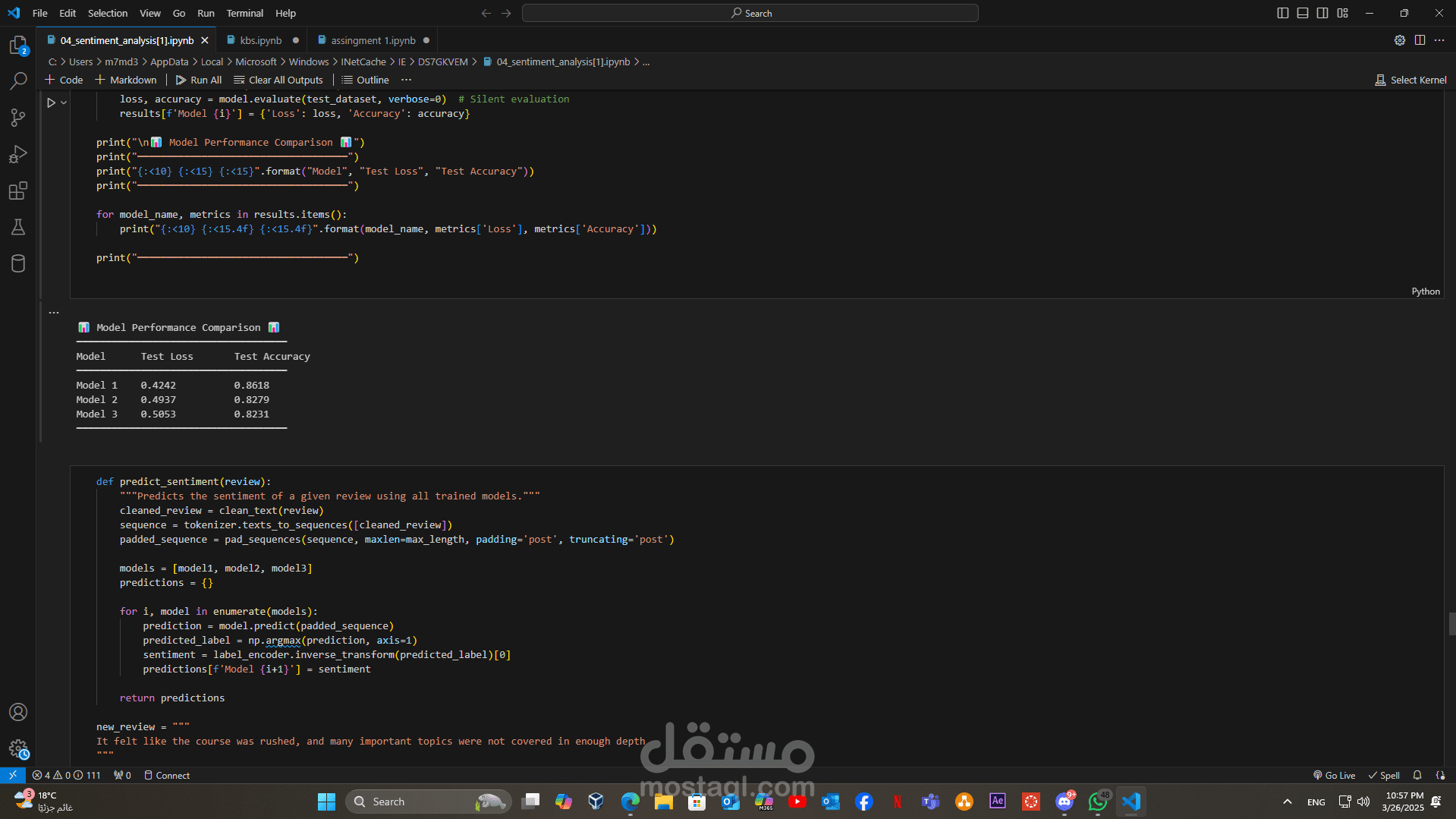
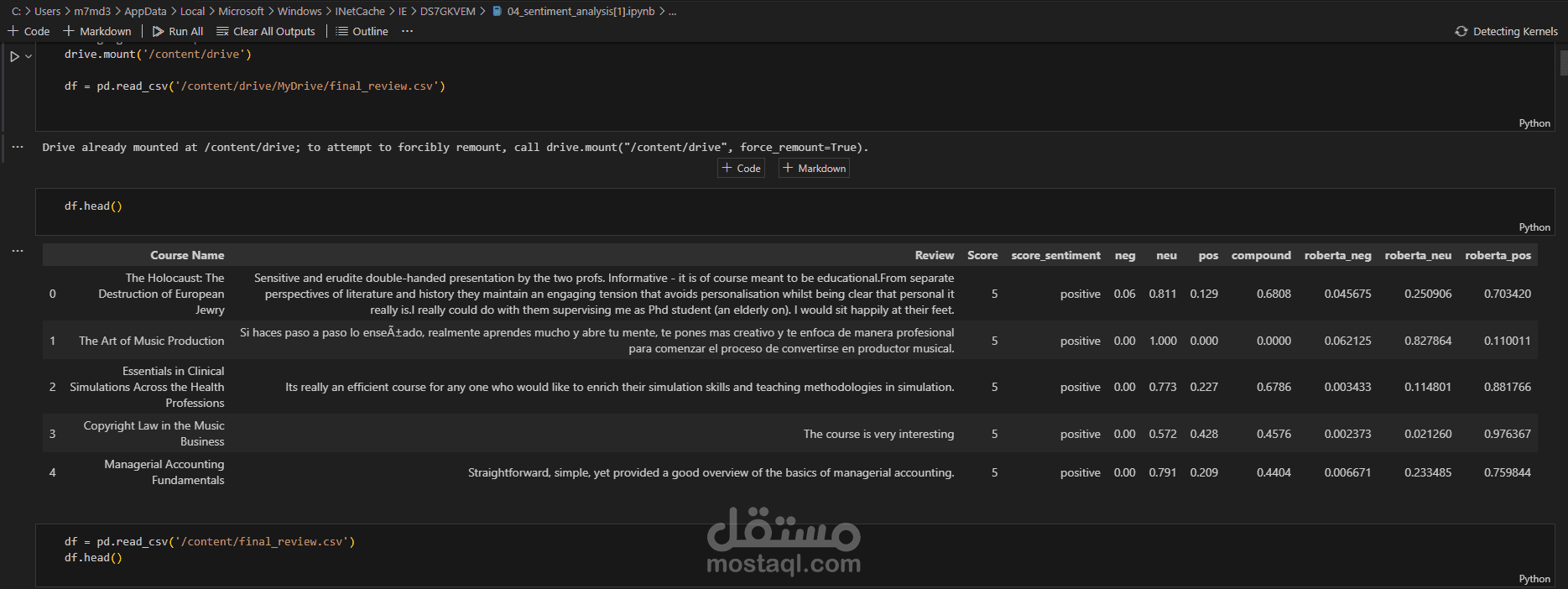
في مشروع Learnwise لتحليل المشاعر، تم تنفيذ سلسلة من التقنيات والأدوات الحديثة لتحويل البيانات النصية إلى نموذج تحليلي دقيق. فيما يلي نظرة تفصيلية على الخطوات والتقنيات المستخدمة:
• جمع البيانات والمعالجة الأولية:
- استخراج أكثر من 60,000 مراجعة من كورسيرا، متضمنة تقييمات النجوم.
- استخدام مكتبات Python مثل Pandas لتنظيف البيانات والتعامل مع القيم المفقودة وإزالة الضوضاء النصية.
• معالجة اللغة الطبيعية (NLP):
- Tokenization: تقسيم النصوص إلى كلمات وعبارات صغيرة.
- إزالة كلمات الوقف (Stop Words): لاستبعاد الكلمات غير المفيدة أثناء التحليل.
- تحويل النص إلى تمثيل رقمي: عبر استخدام تقنية TF-IDF vectorization لتحويل النصوص إلى ميزات عددية قابلة للاستخدام في النماذج.
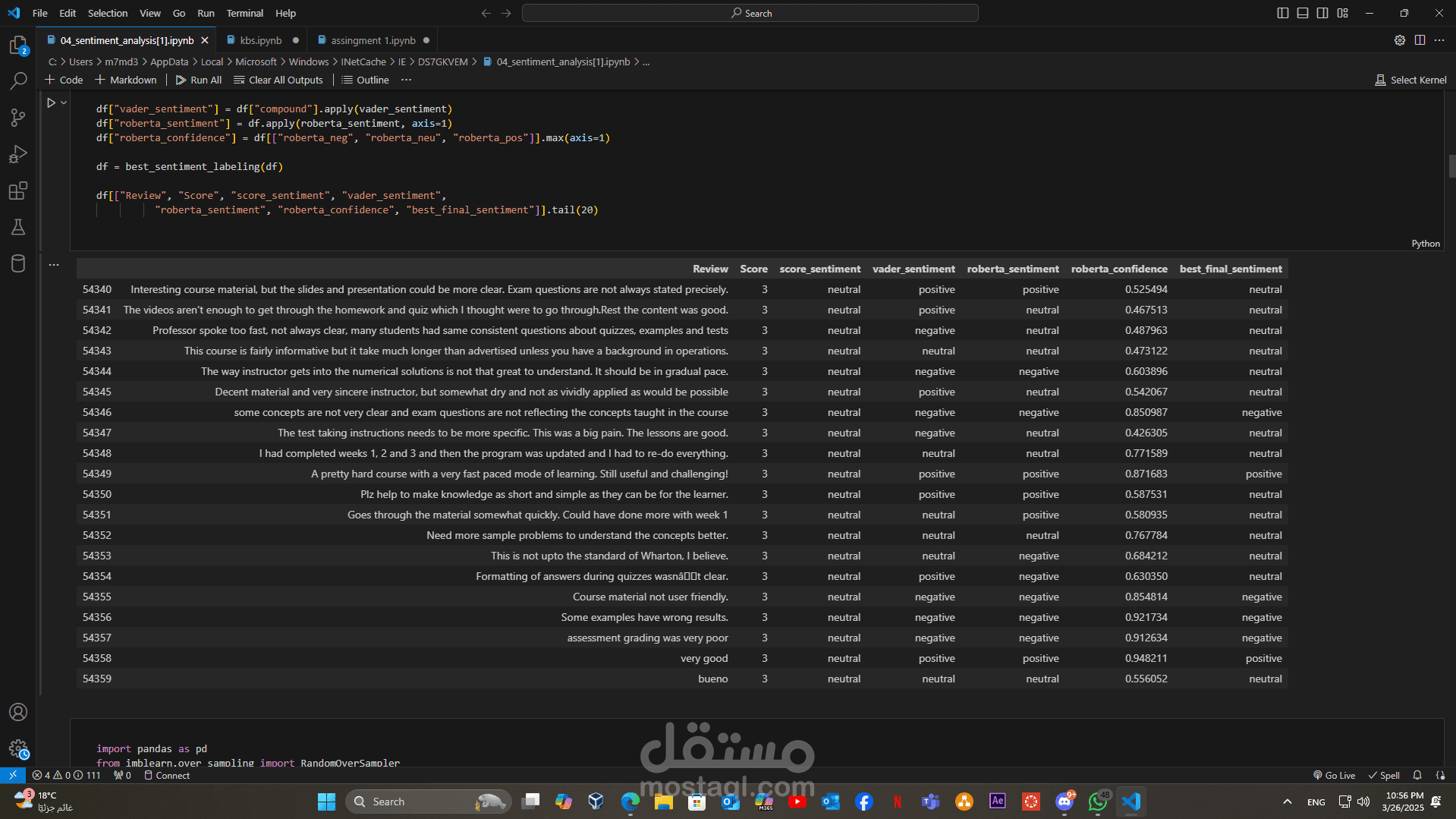
• تقنيات التصنيف وتسمية البيانات:
- تطبيق استراتيجيات متعددة لتسمية المراجعات، سواءً باستخدام أساليب يدوية أو آلية لتحسين جودة التصنيف.
- تجربة عدة نماذج تصنيف مثل Logistic Regression وSVM، واختبار أداء النماذج باستخدام تقنيات مثل cross-validation وتقسيم البيانات لمجموعات تدريب واختبار.
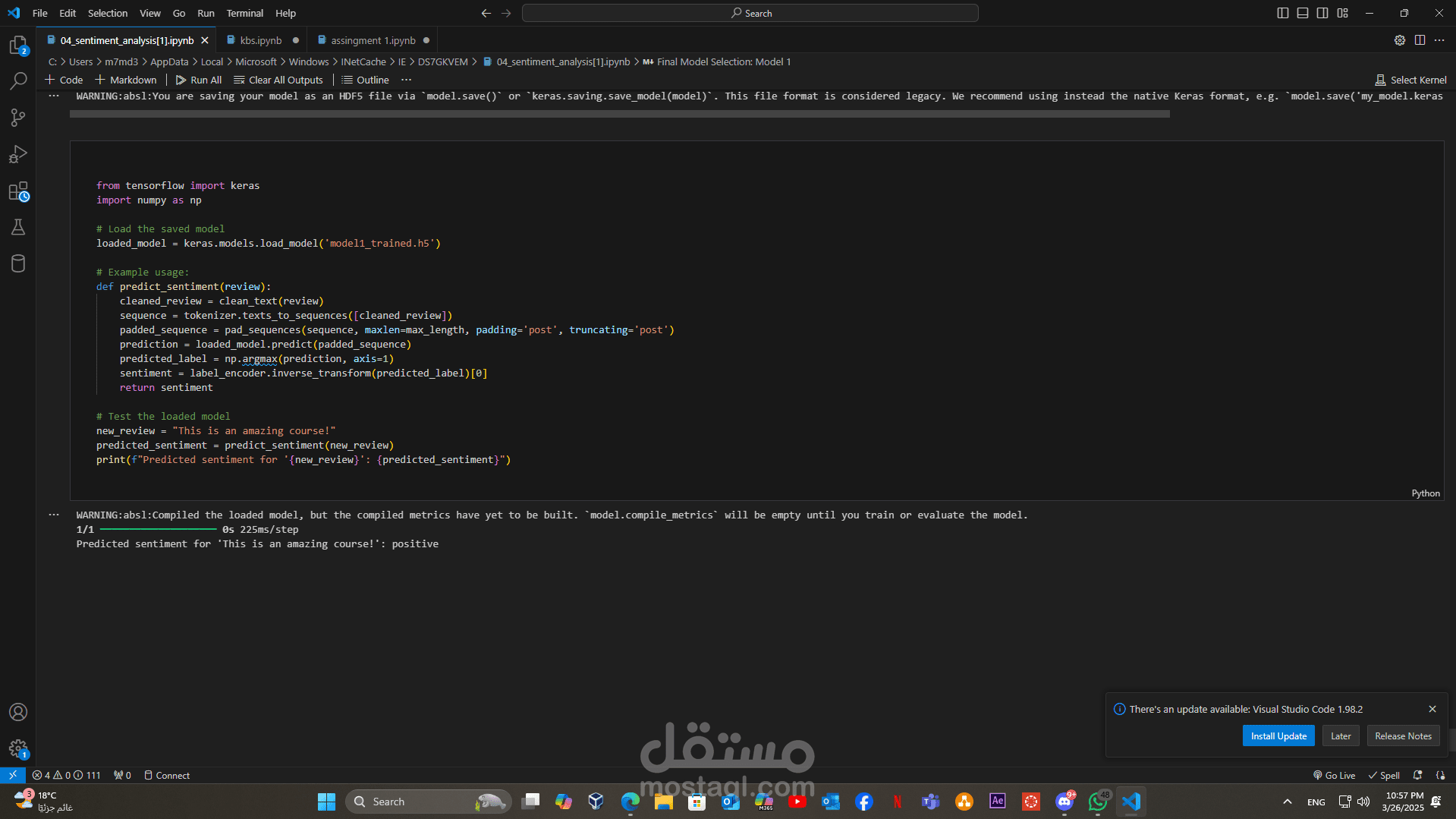
• النموذج النهائي باستخدام RNN:
- بعد التجارب مع النماذج التقليدية، تم استخدام شبكة عصبية تكرارية (RNN) لمعالجة السياق التسلسلي في النصوص بشكل أفضل.
- تم تطبيق تقنيات ضبط الهايبر باراميترز (Hyperparameter Tuning) لتحسين أداء نموذج الـ RNN وضمان أعلى دقة ممكنة في التصنيف.
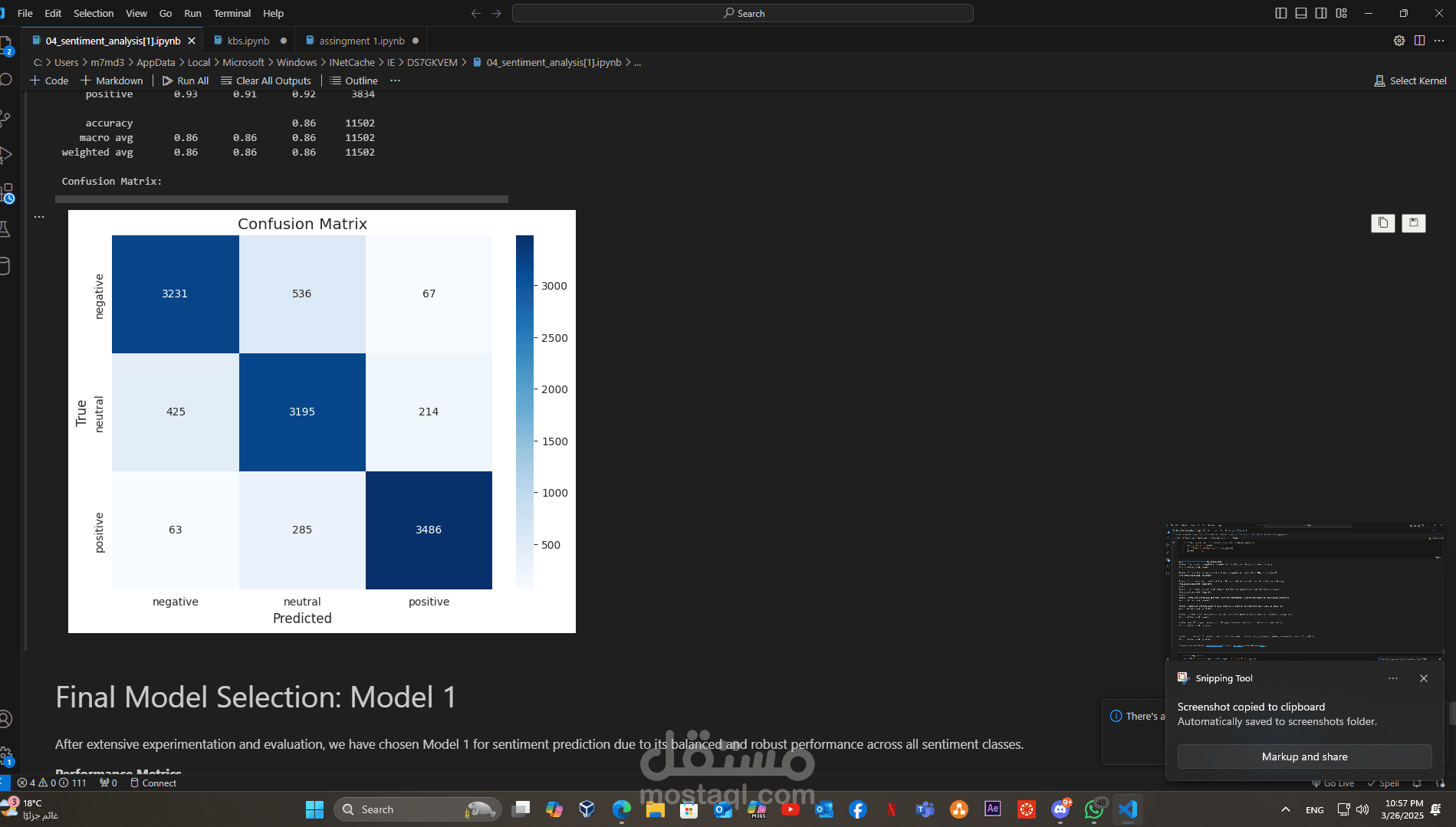
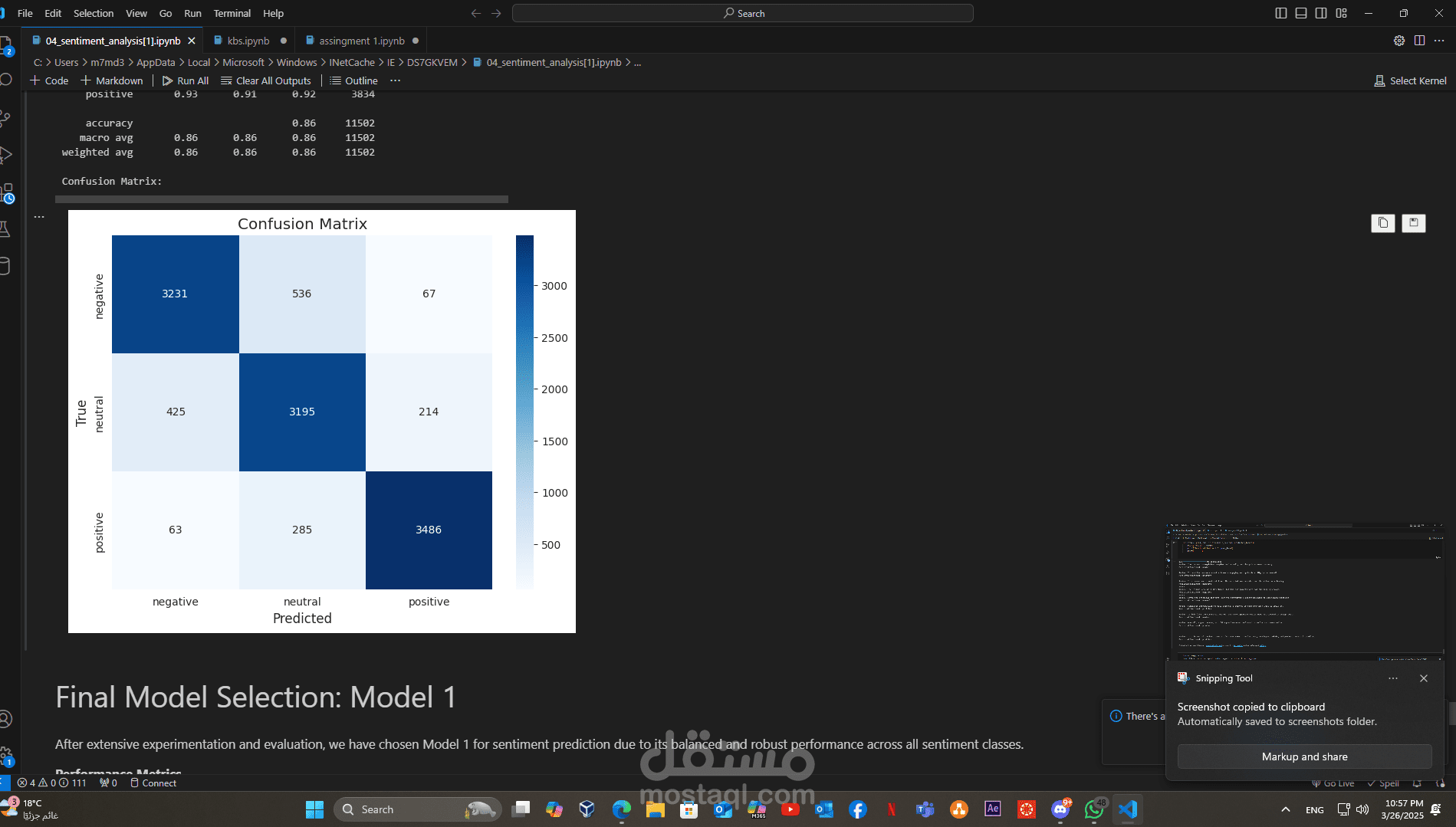
• تنفيذ وتقييم النموذج:
- استخدام مكتبة Scikit-learn مع دمج أطر عمل Deep Learning مثل TensorFlow أو PyTorch لتدريب نموذج RNN.
- تقييم النموذج باستخدام مقاييس الأداء مثل الدقة وF1-score مع رسم التقارير البيانية باستخدام Matplotlib أو Seaborn لتوضيح النتائج.
هذا المشروع يبرز قدرتي على التعامل مع مشاريع NLP متكاملة، بدءًا من جمع البيانات ومعالجتها وصولاً إلى تطوير نموذج RNN متقدم بعد إجراء التولنينج المناسب. يُظهر المشروع كيف يمكن تحويل كميات كبيرة من البيانات النصية إلى رؤى قابلة للتنفيذ، مما يُسهم في تحسين توصيات الدورات وتجربة المستخدم على منصات التعليم.