Crime prediction
تفاصيل العمل
Crime Prediction Using Machine Learning
Objective
The project aims to predict the occurrence of Dacoity (a type of crime) in different districts based on various crime-related features. Using machine learning techniques, specifically RandomForestClassifier, the goal is to create a model that can accurately classify whether a crime event will occur based on historical data.
1.Loads and Prepares Data
Reads the crime_district.csv dataset, which contains crime-related information across different districts. Cleans the data by handling missing values. Converts categorical features (like district names) into numerical form using one-hot encoding.
2.Feature Engineering & Splitting
Selects relevant features (X) and defines the target variable (y), which indicates whether "Dacoity" occurs. Splits the dataset into training (80%) and testing (20%) sets.
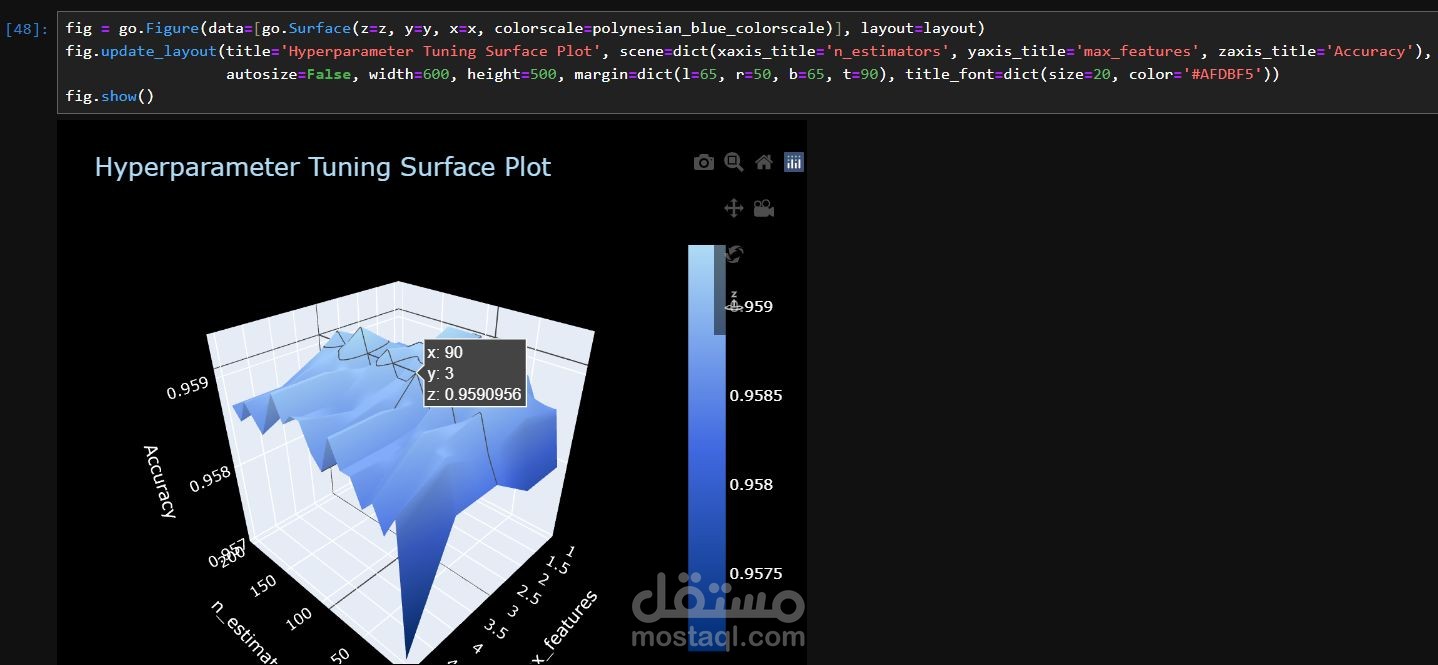
3.Hyperparameter Tuning with GridSearchCV
Uses RandomForestClassifier (an ensemble learning method) to predict crime occurrences. Optimizes model performance by tuning hyperparameters, such as: n_estimators (number of trees in the forest) max_depth (tree depth limit) min_samples_split (minimum samples to split a node) Evaluates multiple combinations using cross-validation to find the best settings.
4.Model Evaluation
Trains the best model using the optimal hyperparameters. Measures performance using accuracy score, classification report, and confusion matrix. Visualizes feature importance to understand which factors contribute most to crime predictions.
Final Outcome
The project successfully improves crime prediction accuracy through hyperparameter tuning. The trained model can help in identifying high-risk districts and assist law enforcement in decision-making. The analysis provides insights into important crime factors, helping in policy-making and crime prevention strategies.