fake_news_predictor
تفاصيل العمل
في هذا المشروع، قمت بتطوير نموذج معالجة اللغة الطبيعية (NLP) والذكاء الاصطناعي لاكتشاف الأخبار المزيفة (Fake News Detection). يهدف النموذج إلى التمييز بين الأخبار الحقيقية والمزيفة من خلال تحليل النصوص باستخدام تقنيات التعلم الآلي.
الخطوات التي قمت بها:
تنظيف البيانات: إزالة الضوضاء، الرموز غير الضرورية التكرار، وتوحيد النصوص
تحليل البيانات الاستكشافية (EDA) دراسة توزيع البيانات، الكلمات الأكثر شيوعًا، والروابط بين الكلمات.
تحويل النصوص إلى بيانات عددية TF-IDF
بناء النماذج:
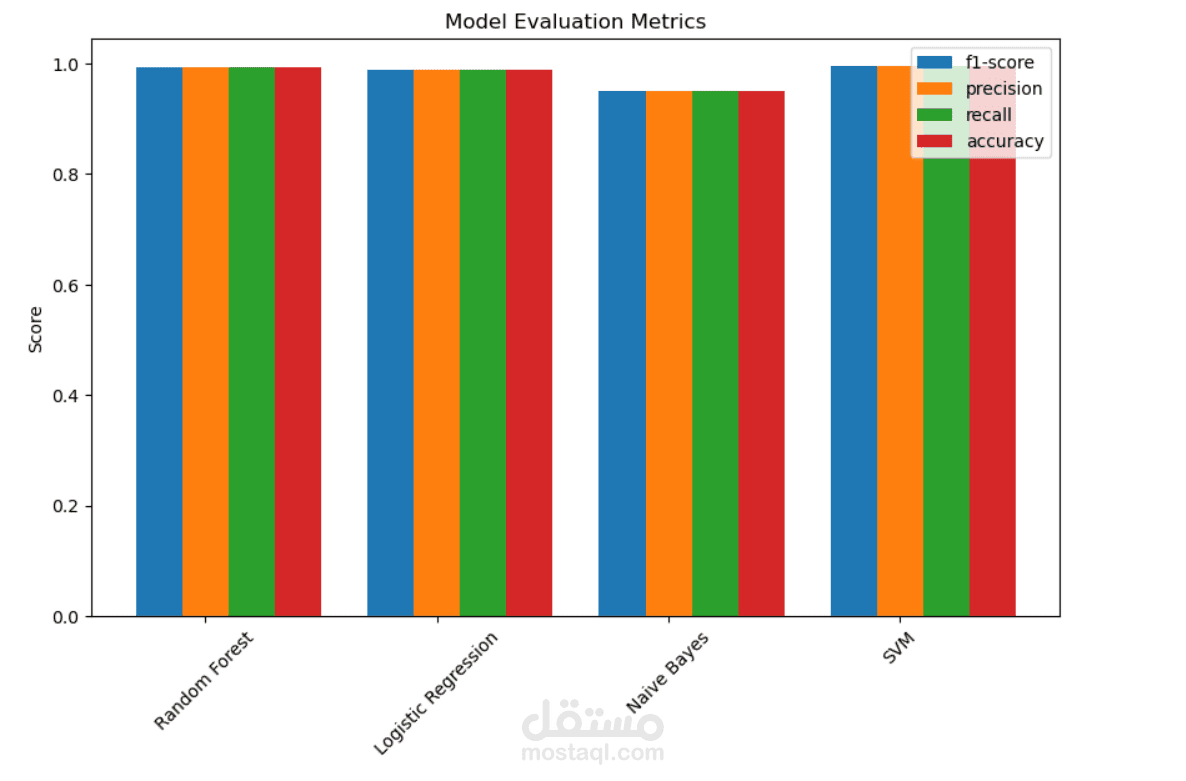
تدريب عدة نماذج مثل Logistic Regression, Random Forest, Naïve Bayes, SVM, لتصنيف الأخبار.
تحسين النموذج: ضبط Hyperparameters واختبار أداء النماذج باستخدام مقاييس مثل Accuracy, Precision, Recall, F1-score.
تحليل النتائج: مقارنة أداء النماذج المختلفة وتحديد النموذج الأكثر كفاءة لاكتشاف الأخبار المزيفة.
التقنيات والأدوات المستخدمة:
Python, Pandas, NumPy, Scikit-learn, matplotlib,seaborn
NLTK(لتحليل النصوص)
TF-IDF, Word2Vec, Count Vectorizer
Logistic Regression, Naïve Bayes, Random Forest, SVM
النتيجة: حقق النموذج SVM دقة عالية جدا في كشف الأخبار المزيفة، مما يساعد في مكافحة التضليل الإعلامي وتعزيز مصداقية المحتوى الإخباري.