Data Analysis and Classification Using Machine Learning Algorithms
تفاصيل العمل
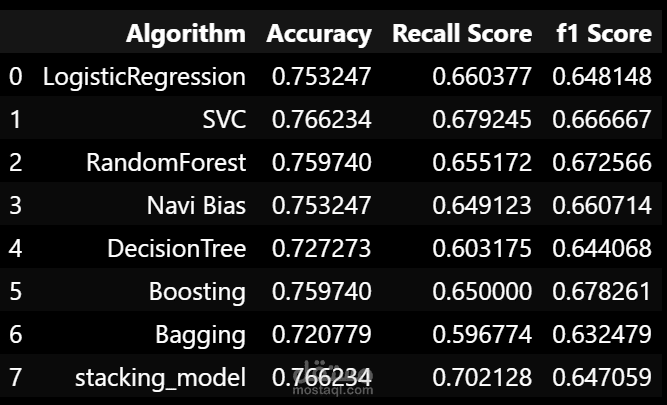
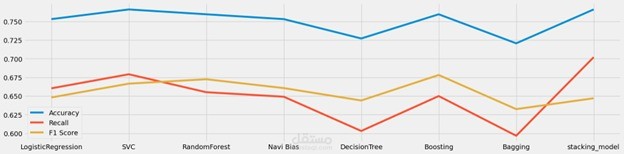
This project focuses on data analysis and classification using various machine learning algorithms such as Logistic Regression, SVM, Random Forest, Decision Tree, Naïve Bayes, and AdaBoost. The process involves data preprocessing, feature selection, model training, and evaluation using metrics like accuracy, confusion matrix, and F1-score.
The project utilizes Pandas, NumPy, Seaborn, Scikit-learn, and Matplotlib for data manipulation, visualization, and model assessment.