Loan Prediction Dataset EDA and Preprocessing
تفاصيل العمل
The code performs a loan prediction task using machine learning. It involves the following steps:
Data Loading and Preprocessing:
Loads training and testing data from CSV files.
Handles missing values by imputing them with the mode.
Converts categorical features into numerical representations using one-hot encoding.
Creates new features like 'TotalIncome', 'LoanAmount_Log', and 'IncomeRatio' for better model performance.
Exploratory Data Analysis (EDA):
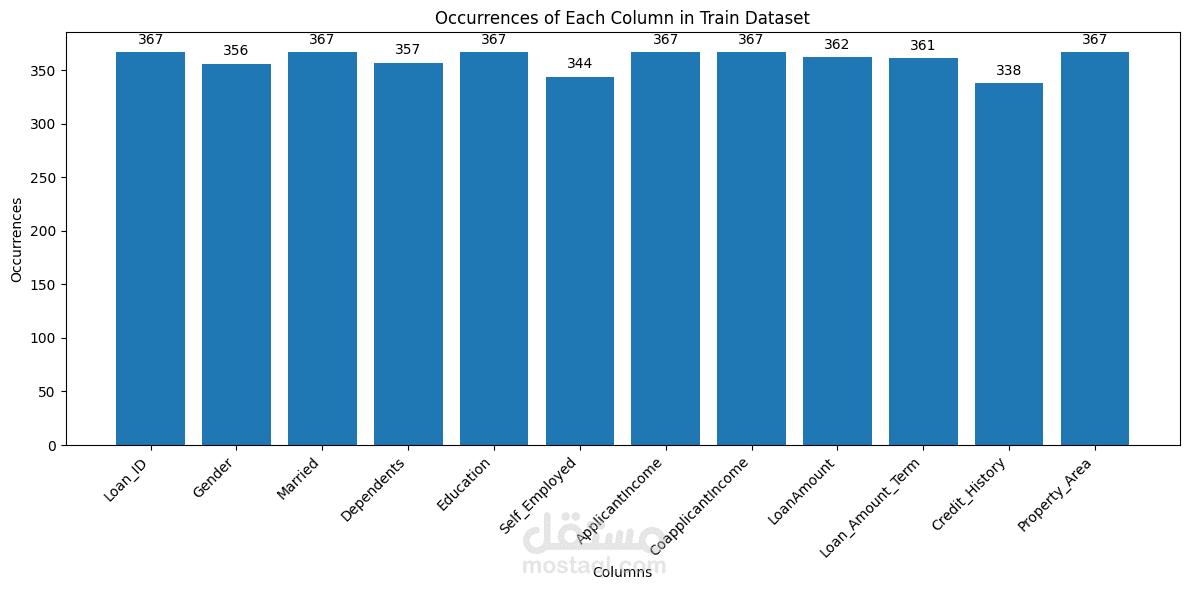
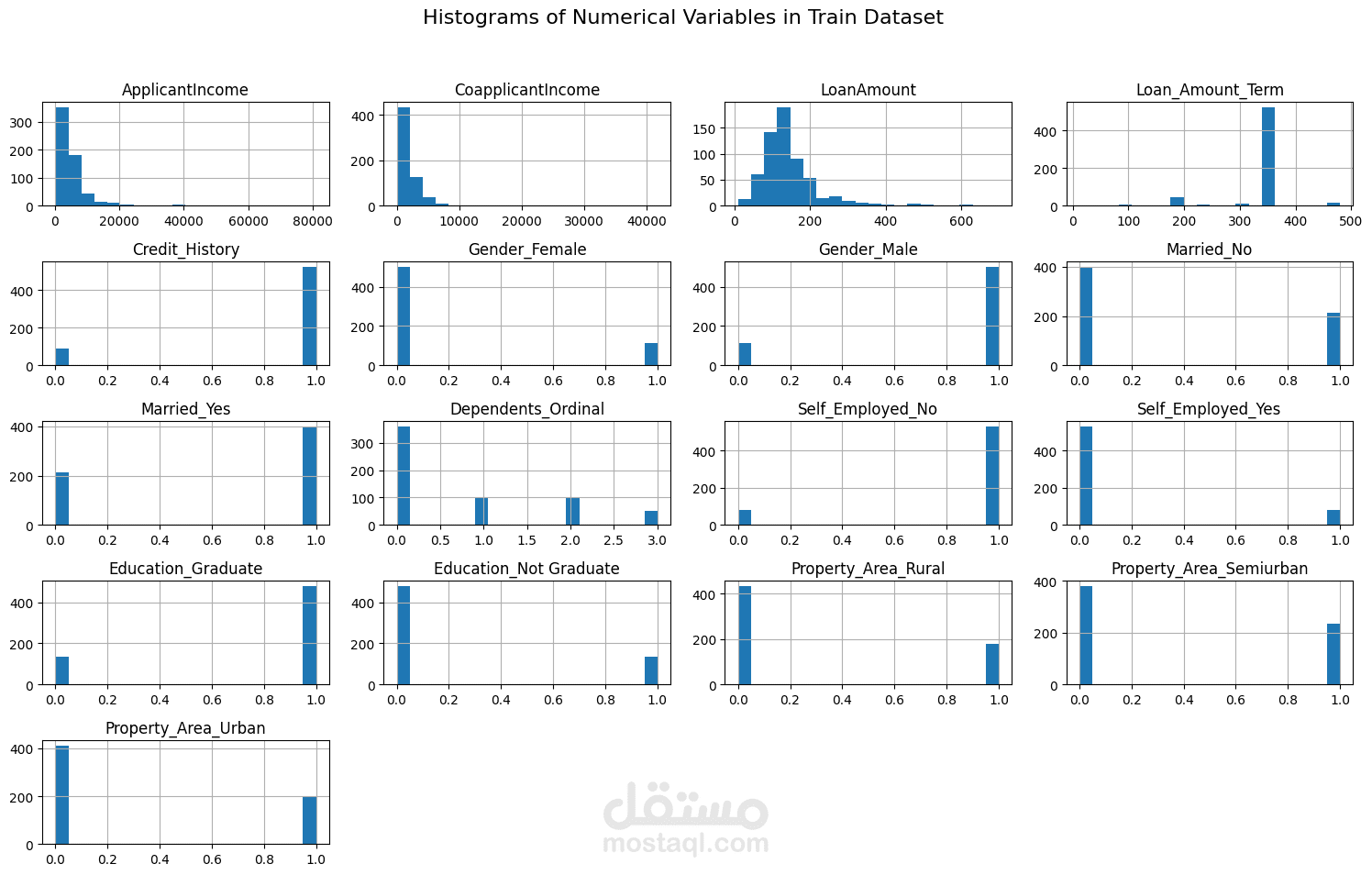
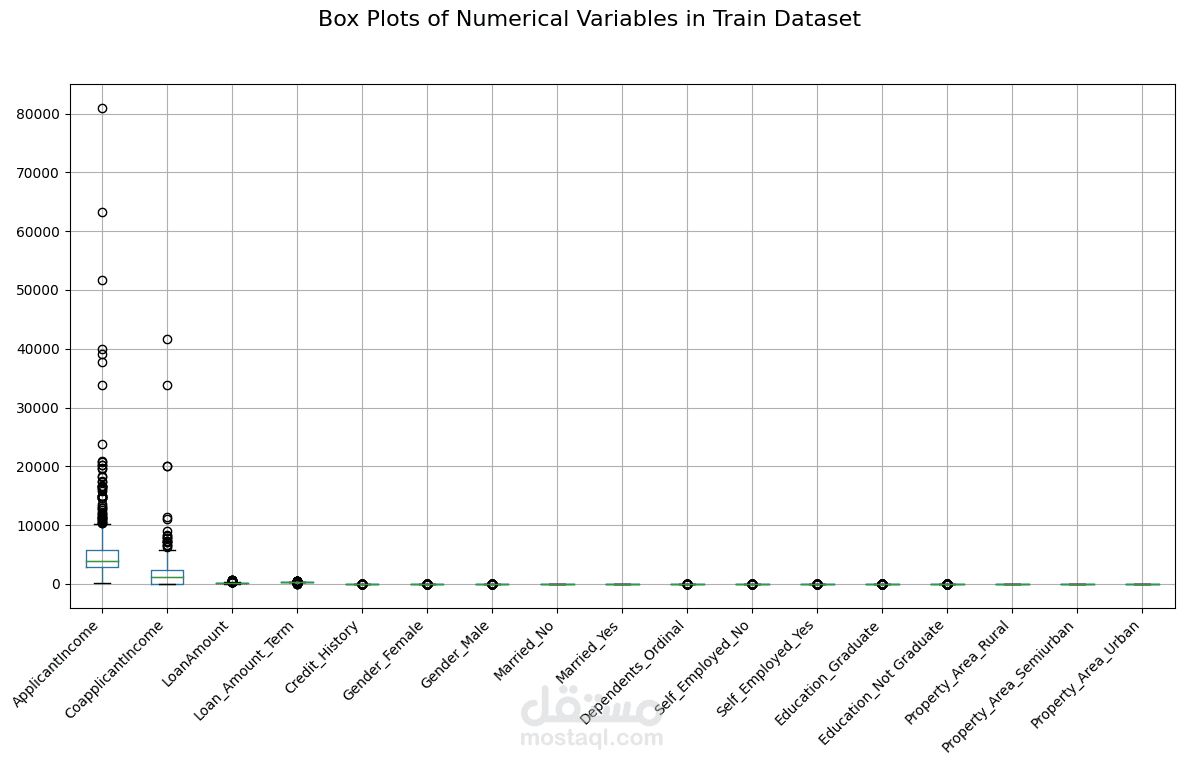
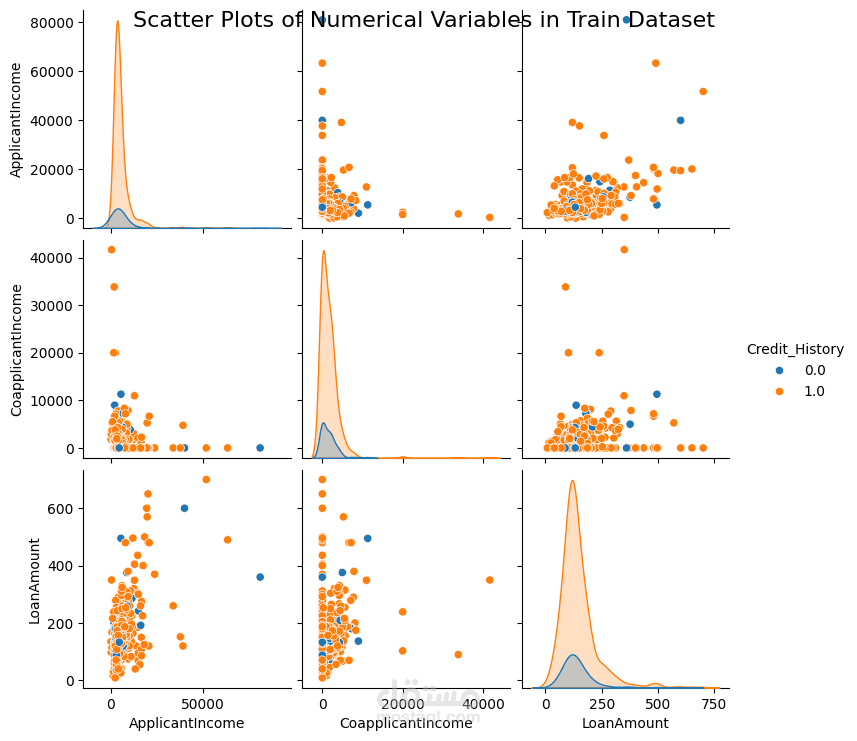
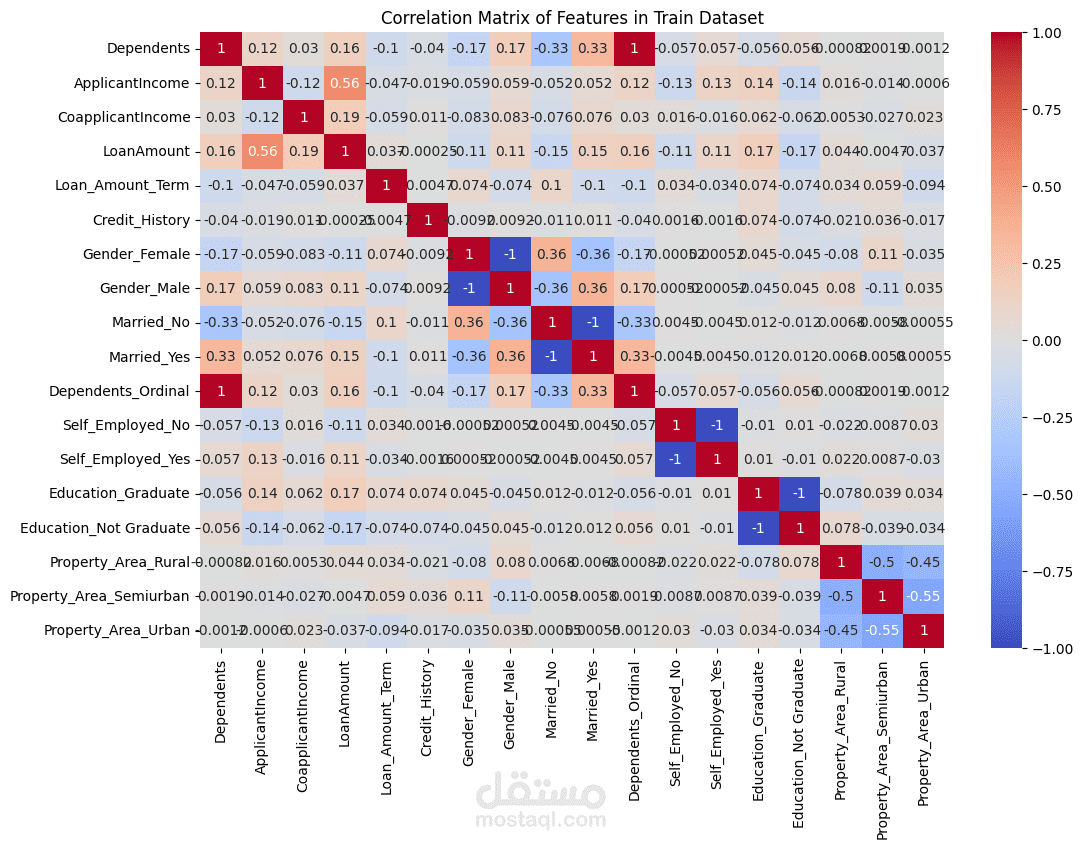
Performs descriptive statistics and visualizations to understand data distribution and relationships between features.
Uses histograms, box plots, scatter plots, and correlation matrices for visualization.
Feature Selection:
Applies feature selection techniques like SelectKBest with chi-squared score function to identify important features for loan prediction.
Model Training and Evaluation:
Splits the training data into training and validation sets.
Trains various machine learning models including Logistic Regression, Decision Tree, Random Forest, Gradient Boosting, and SVM.
Evaluates the models using accuracy and classification report metrics on the validation set.
Overall Objective:
The main objective of the task is to build a predictive model that can accurately classify loan applications as either approved or rejected based on the given features. The code explores different machine learning algorithms and evaluates their performance to select the best model for loan prediction.