EDA and Data Preprocessing for adult dataset
تفاصيل العمل
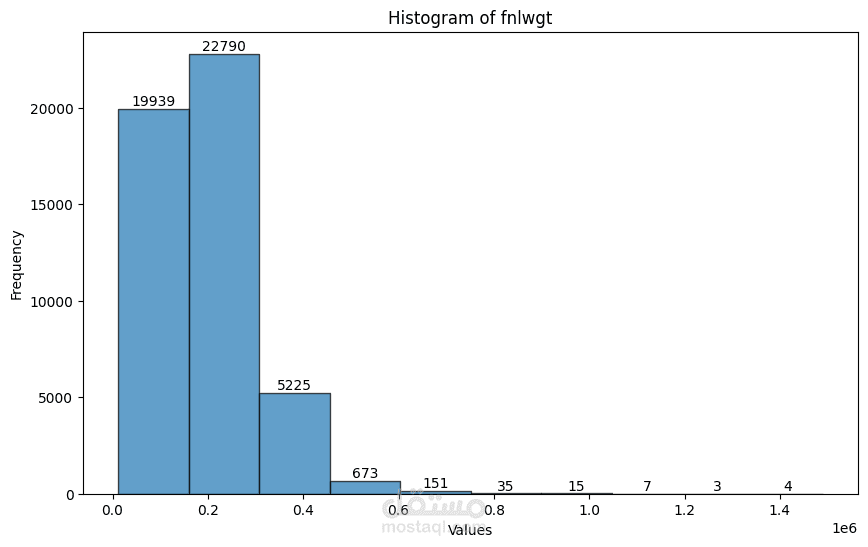
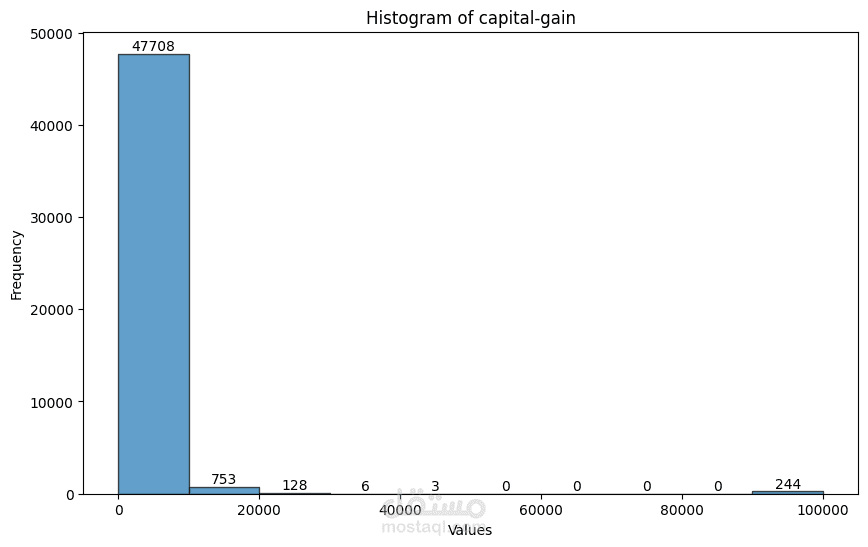
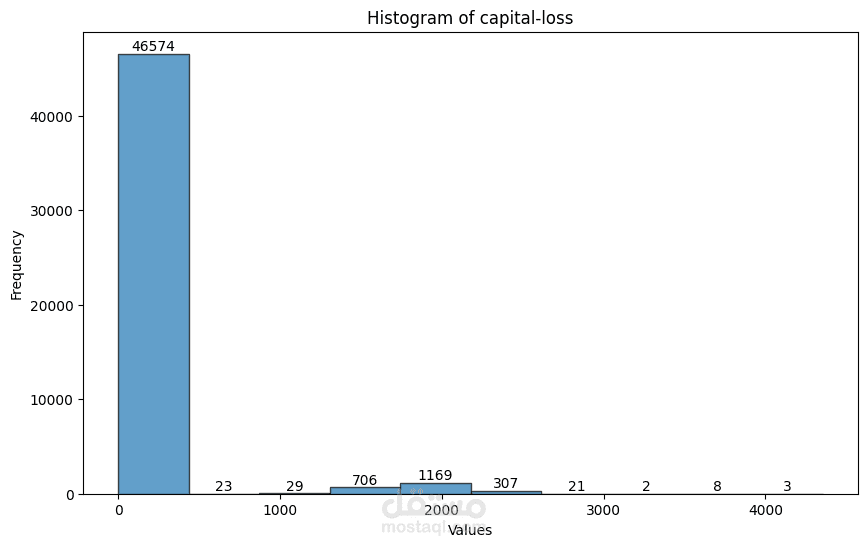

The code performs Exploratory Data Analysis (EDA) and Data Preprocessing on the adult.csv dataset. Here's a breakdown of the steps:
Data Loading and Initial Exploration:
The code starts by loading the dataset into a pandas DataFrame.
It then performs basic data exploration using functions like head(), describe(), shape, and info() to get an overview of the data, its structure, and statistical summary.
Handling Missing Values:
The code checks for missing values and replaces them using appropriate strategies like imputation with the mode.
Identifying and Handling Duplicates:
The code detects and removes duplicate rows in the dataset, ensuring data integrity.
Outlier Detection and Treatment:
Outliers are identified in numerical features using techniques like the Interquartile Range (IQR) method.
Outliers are then handled by either removing them or applying transformations to reduce their impact on the analysis.
Encoding Categorical Features:
Categorical features are converted into numerical representations using encoding techniques such as one-hot encoding, binary encoding, and ordinal encoding. This is necessary for many machine learning algorithms that work primarily with numerical data.
Feature Scaling and Standardization:
Numerical features are scaled or standardized to bring them to a similar range. This can improve the performance of some machine learning algorithms.
The code uses MinMaxScaler for feature scaling and StandardScaler for standardization.
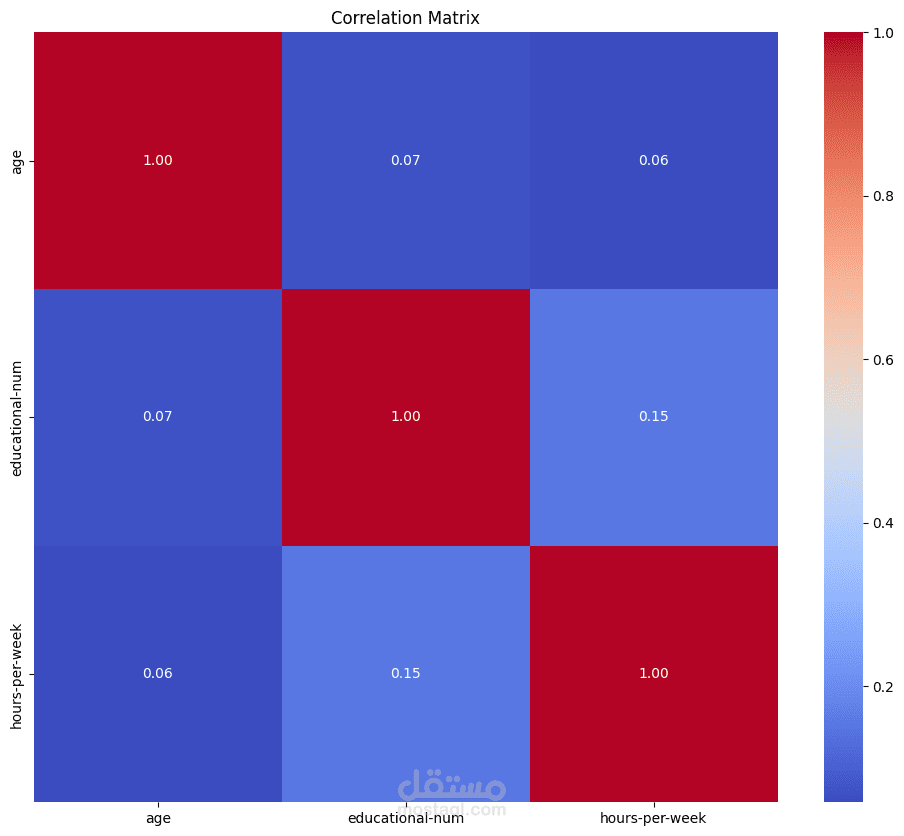
Correlation Analysis:
The correlation between numerical features is examined using a correlation matrix and visualized using a heatmap. This helps understand relationships between variables.
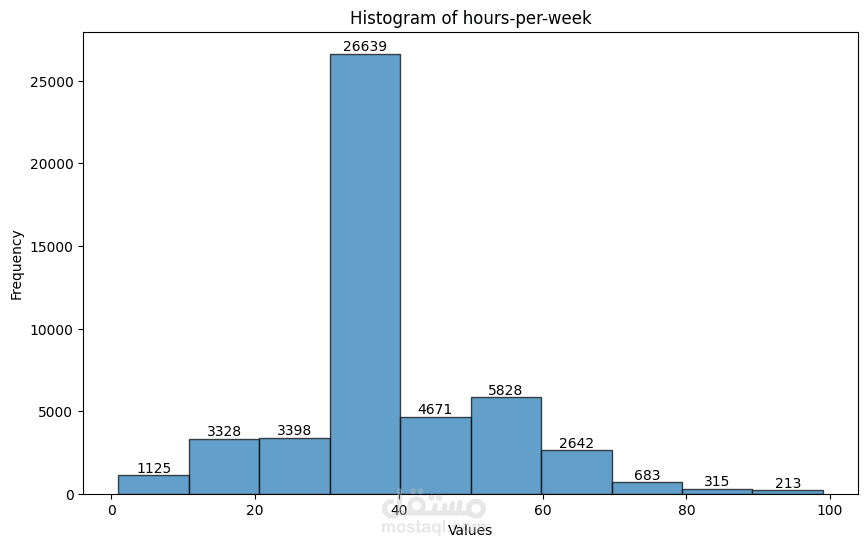
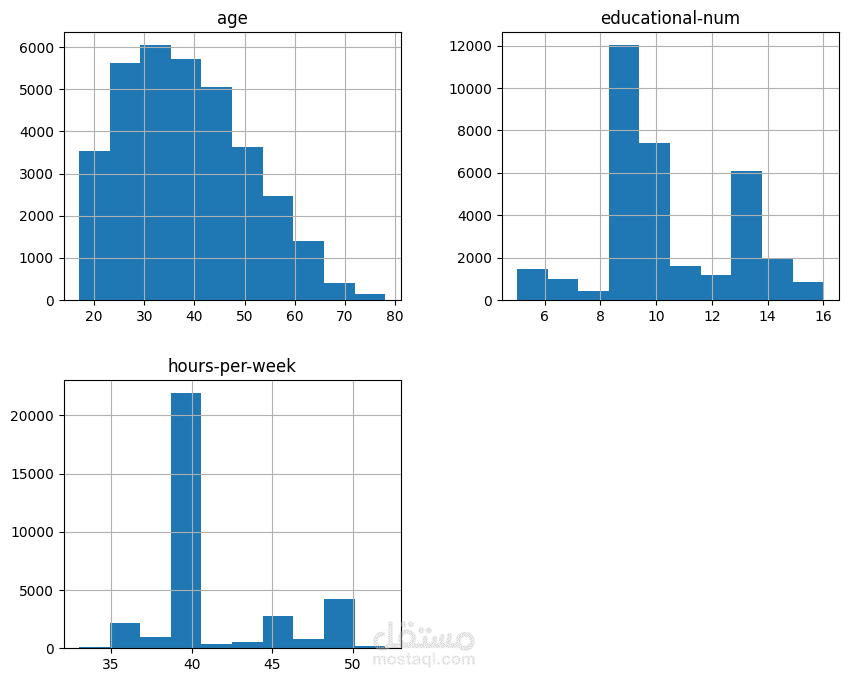
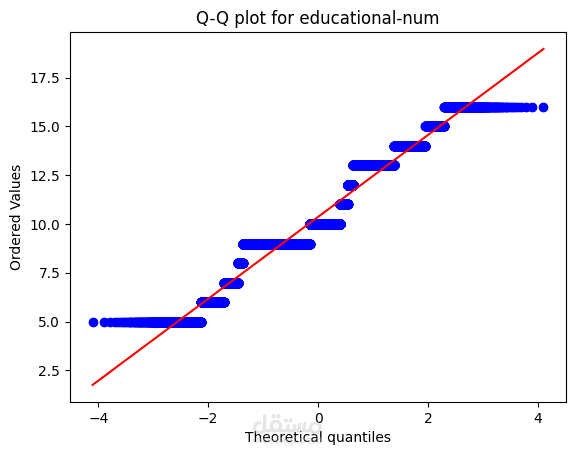
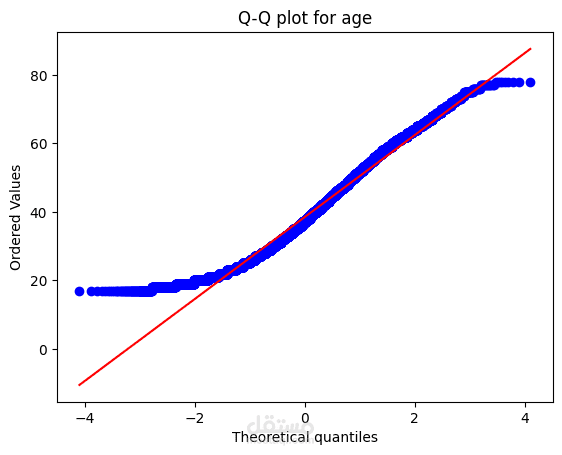
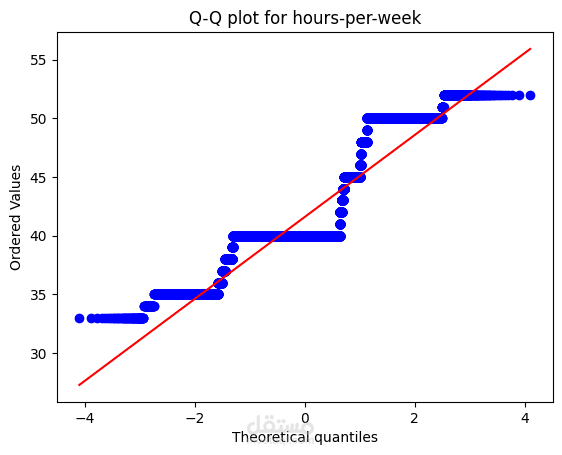
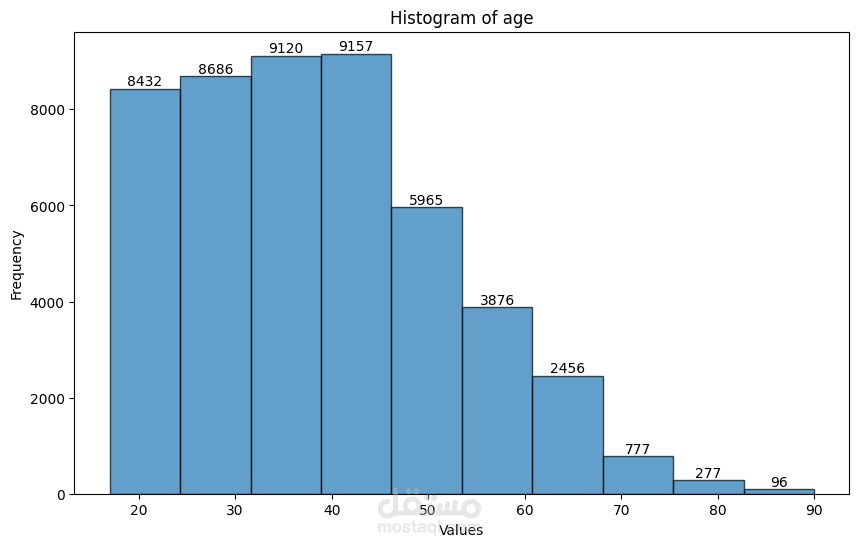
Distribution Analysis and Transformation:
The distribution of numerical features is visualized using histograms and Q-Q plots.
If the data is not normally distributed, transformations like log transformation, square root transformation, or Box-Cox transformation are applied to improve normality.