lab tests analysis
تفاصيل العمل
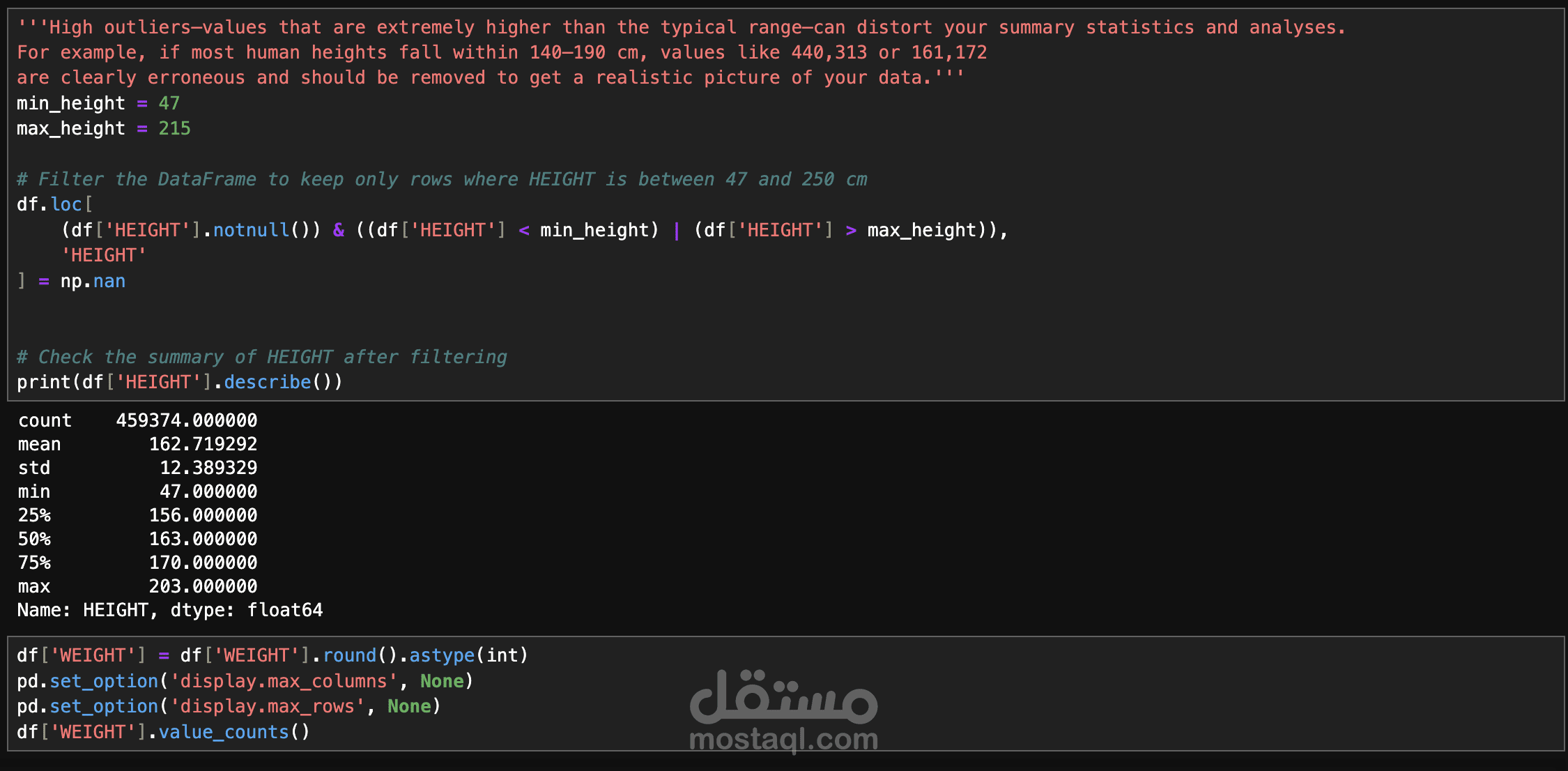
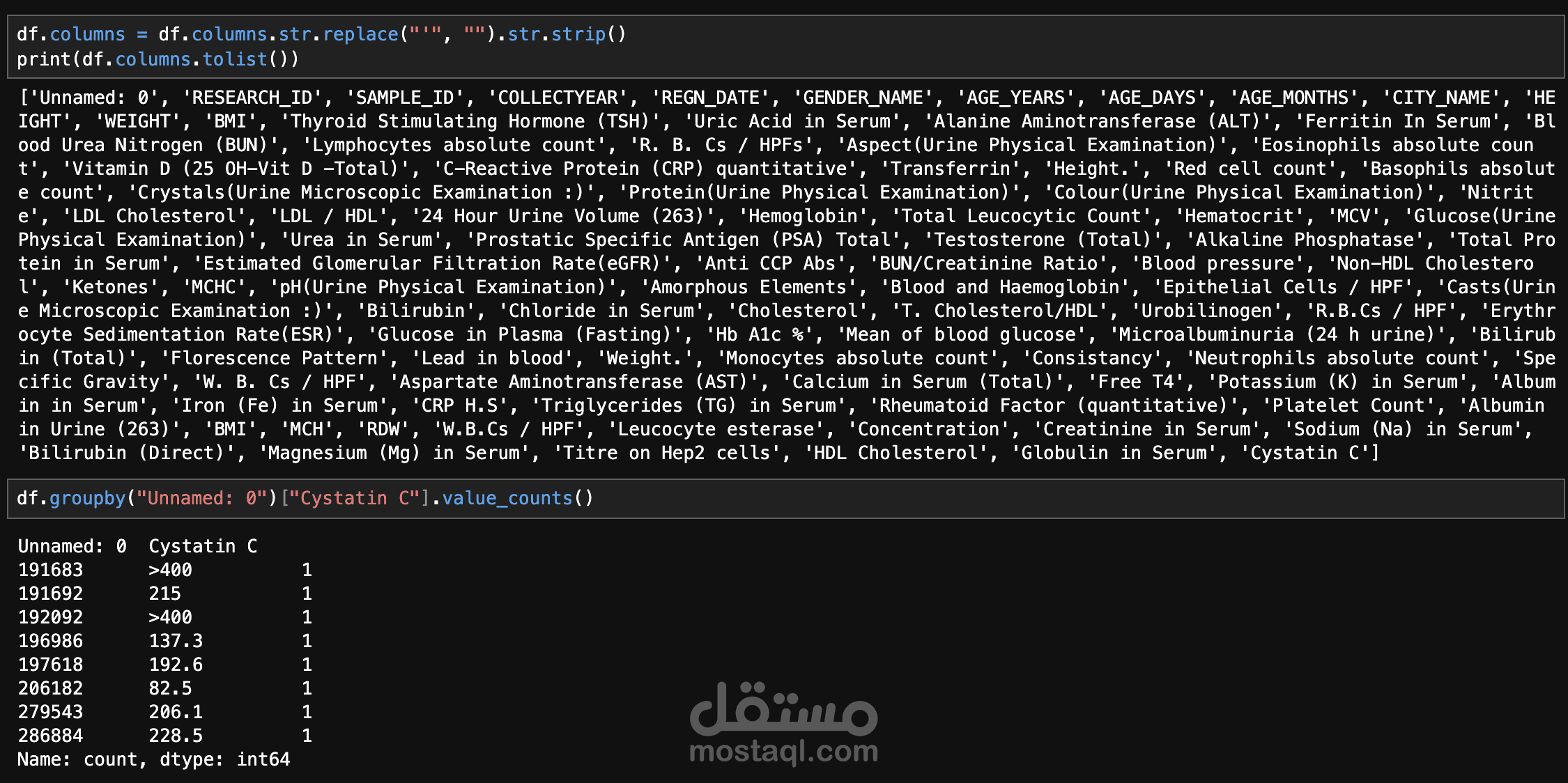
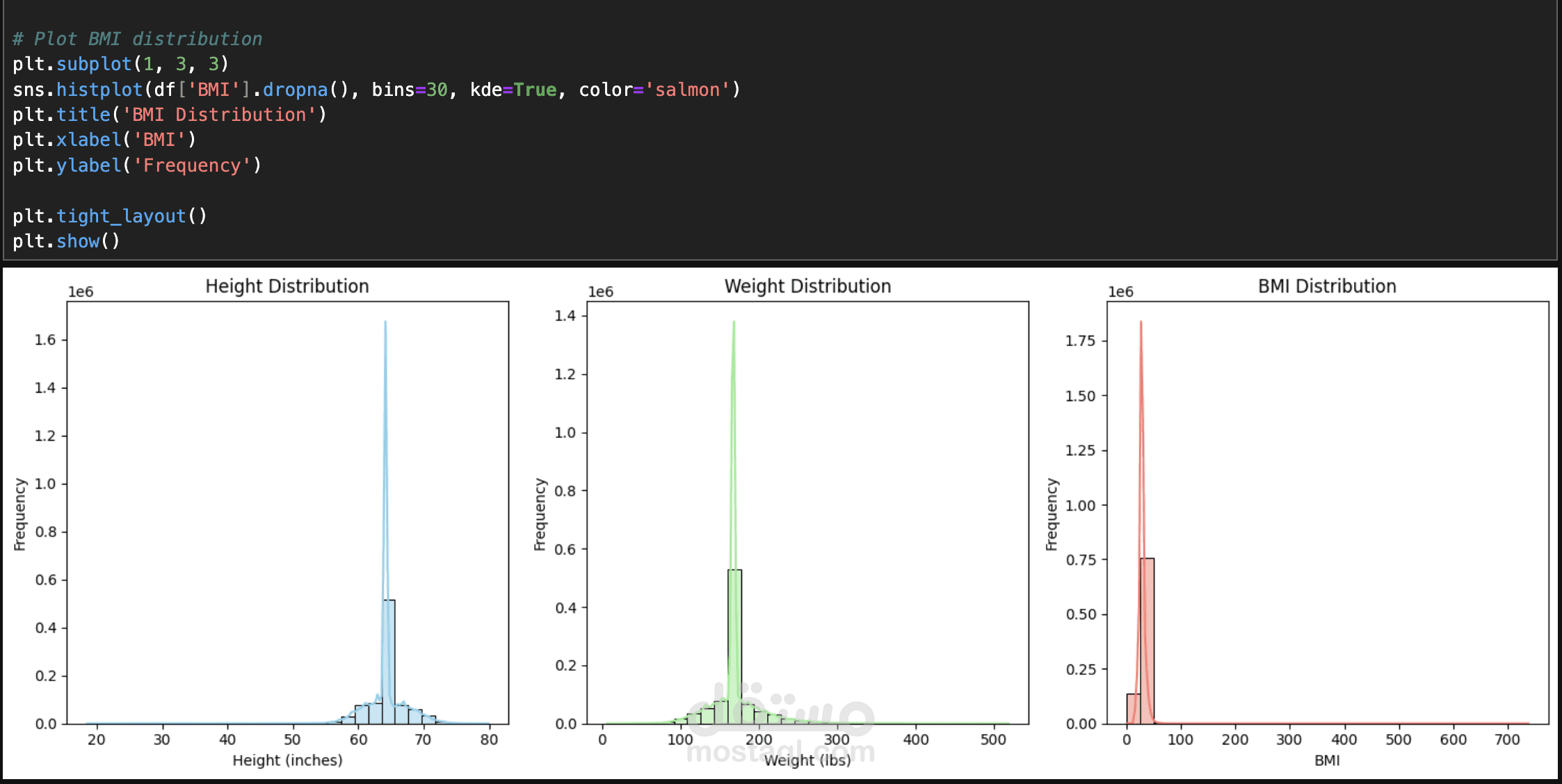
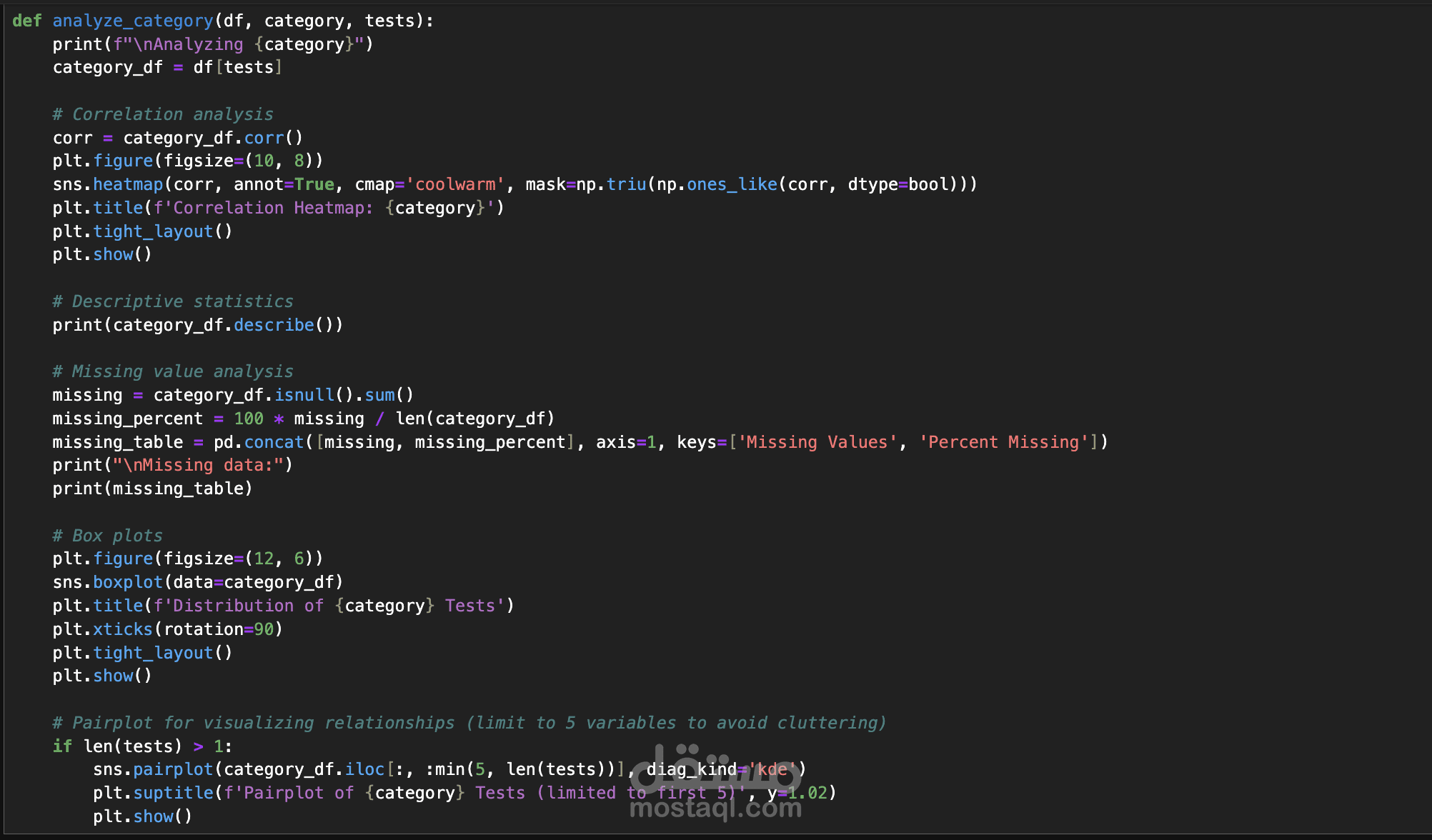
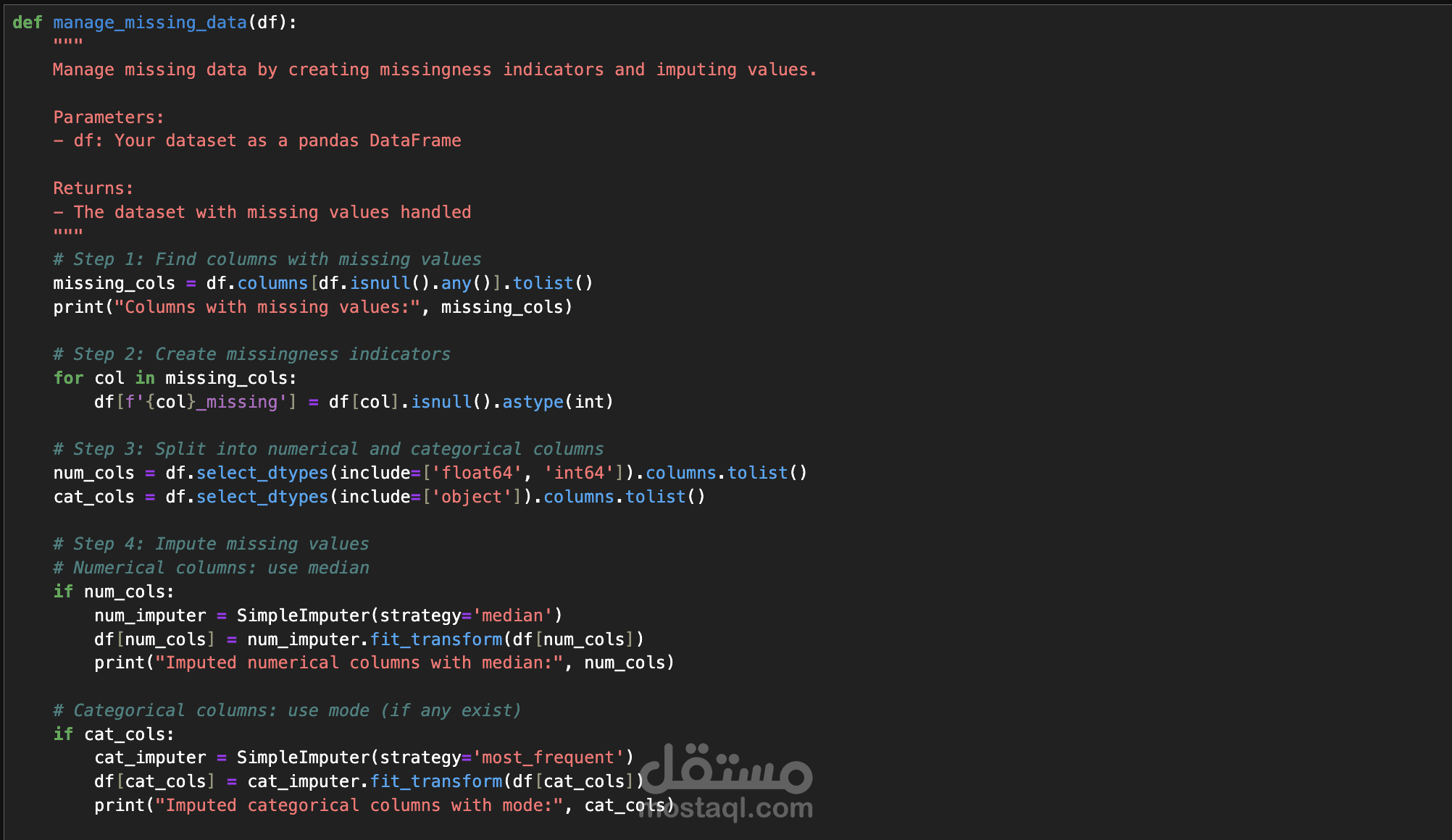
هذا المشروع يهدف إلى تحليل وتنقية بيانات طبية ضخمة لتحسين جودتها وجعلها جاهزة للتحليل الإحصائي أو بناء نماذج تعلم الآلة. يتضمن المشروع معالجة مجموعة بيانات تحتوي على 96 عمودًا و900,000 سجل، تضم اختبارات طبية متنوعة مثل هرمون تحفيز الغدة الدرقية (TSH)، حمض اليوريك في المصل (Uric Acid in Serum)، معدل ترشيح الكبيبات (eGFR)، مستويات الكوليسترول (LDL/HDL)، وفيتامين د (Vitamin D). تم تنفيذ عدة مراحل أساسية لتنظيف البيانات، تشمل تصحيح القيم السلبية غير المنطقية، تقييد القيم الشاذة (outliers) باستخدام حدود عليا معقولة، إدارة البيانات المفقودة باستخدام تقنية الاستبدال بالوسيط (median imputation) مع إنشاء مؤشرات للبيانات المفقودة، إزالة التكرارات من الصفوف المطابقة تمامًا ومعالجة إدخالات المرضى المتعددة باختيار أحدث سجل لكل مريض، تحويل أنواع البيانات لضمان أن تكون جميع الأعمدة الاختبارية رقمية (numeric) مع تحويل القيم غير الصالحة إلى NaN، وأخيرًا توحيد الوحدات لضمان تناسق القياسات (مثل تحويل الوحدات من mmol/L إلى mg/dL للجلوكوز). الهدف الأساسي هو تحسين جودة البيانات لدعم تطبيقات متقدمة مثل التحليل الإحصائي، بناء نماذج التنبؤ باستخدام التعلم الآلي، أو استخلاص رؤى طبية. يشمل المشروع أيضًا خطوات مستقبلية مثل هندسة المزايا (feature engineering) بإنشاء ميزات جديدة مثل النسب (ratios) والعلامات السريرية (clinical flags)، وتحديد المزايا الأكثر أهمية باستخدام تقنيات مثل تحليل الارتباط (correlation analysis) ونماذج مثل Random Forest لتقليل الأبعاد وتحسين الأداء. يتم تنفيذ المشروع باستخدام أدوات مثل Python ومكتبات مثل pandas، scikit-learn، وmatplotlib لضمان دقة النتائج وتقديم بيانات موثوقة للسياقات الطبية أو البحثية.