Customer Churn Predictions
تفاصيل العمل

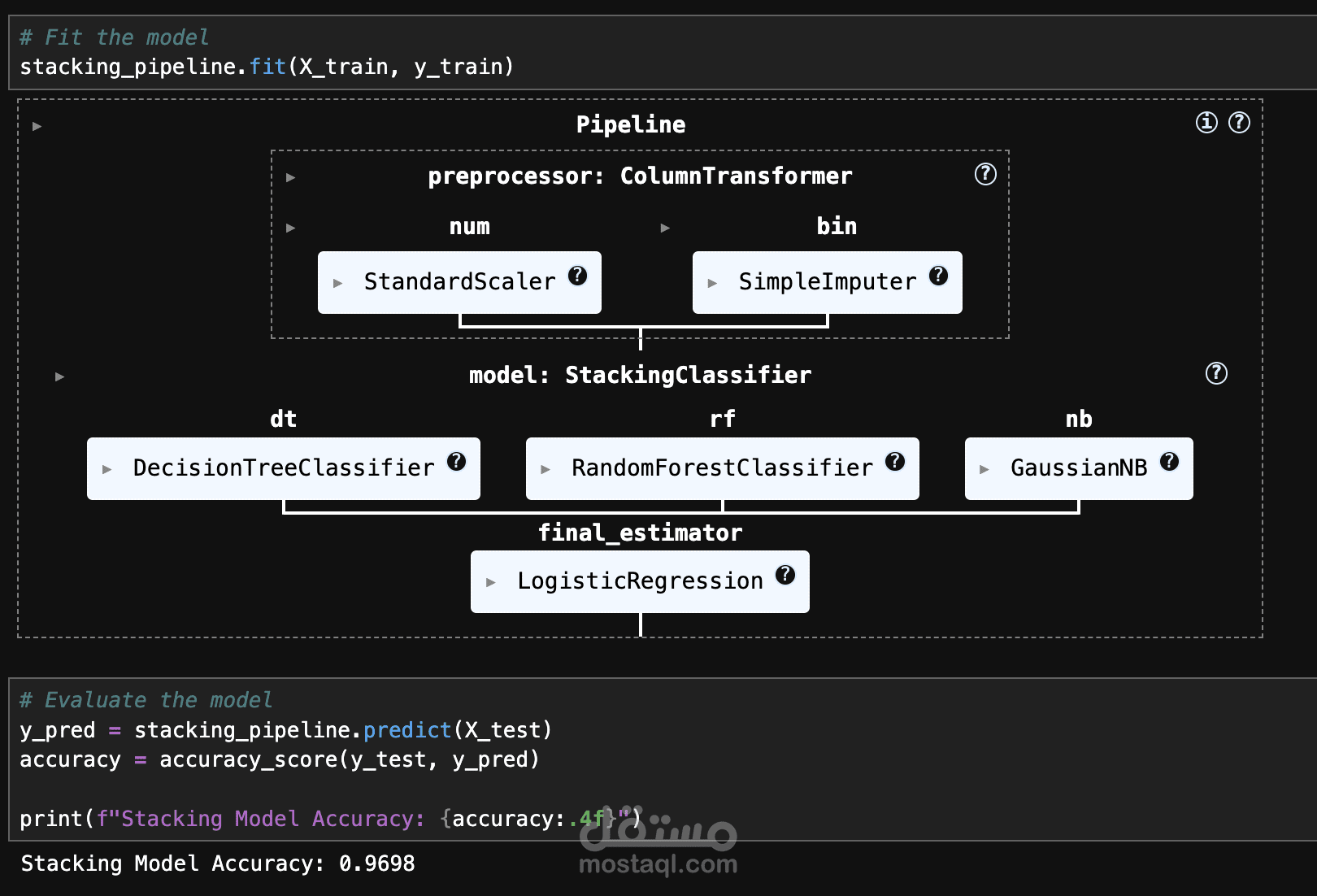
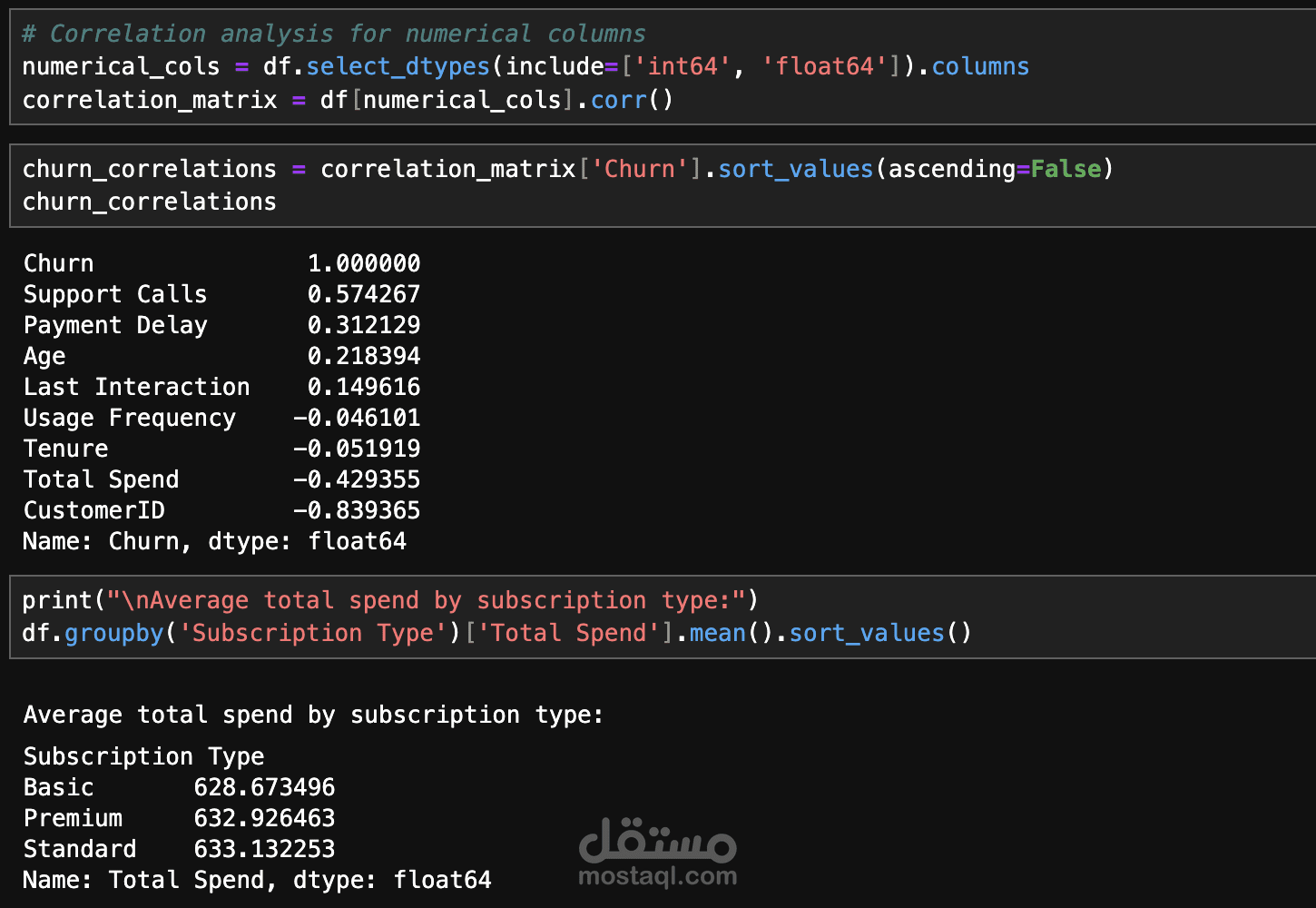
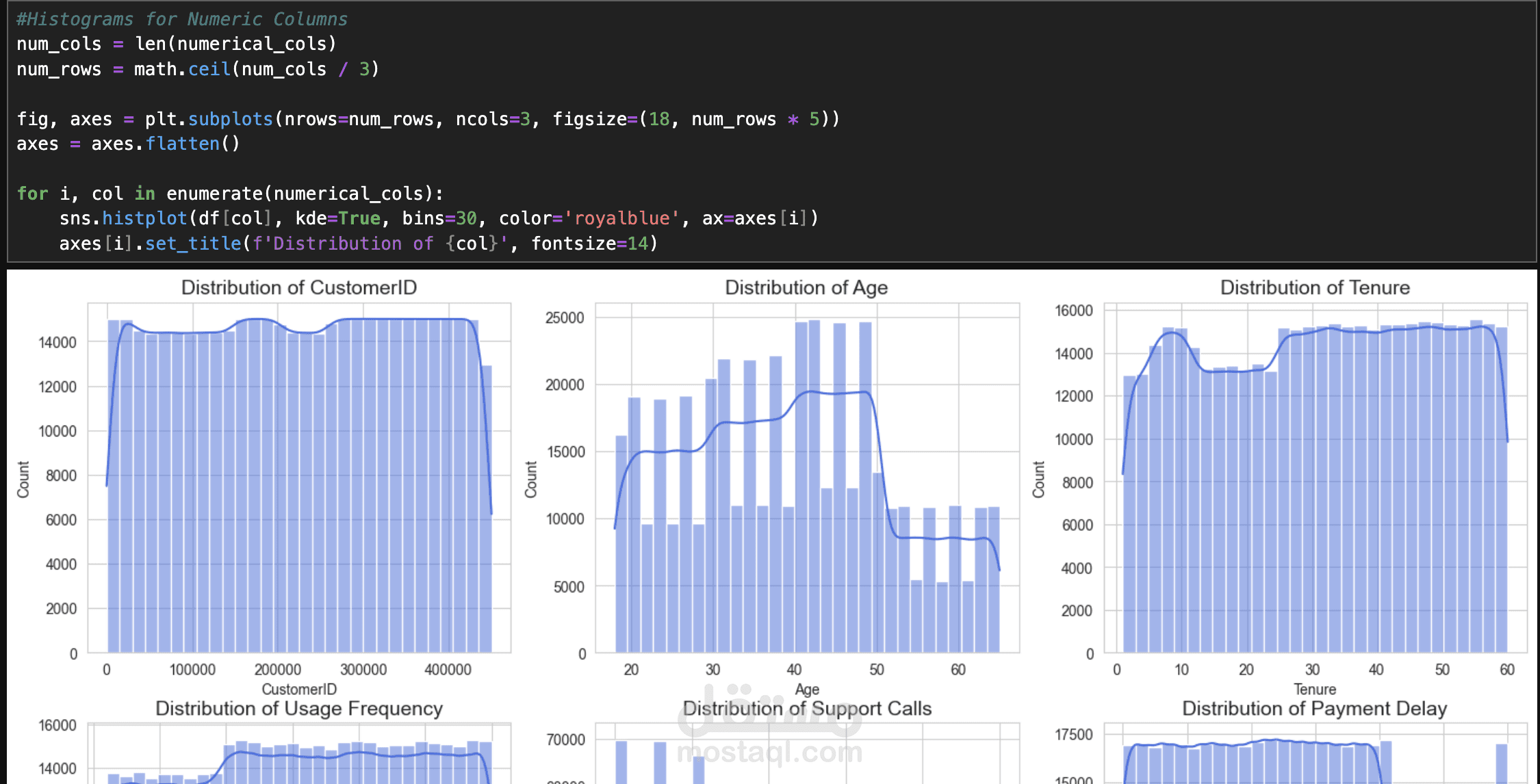
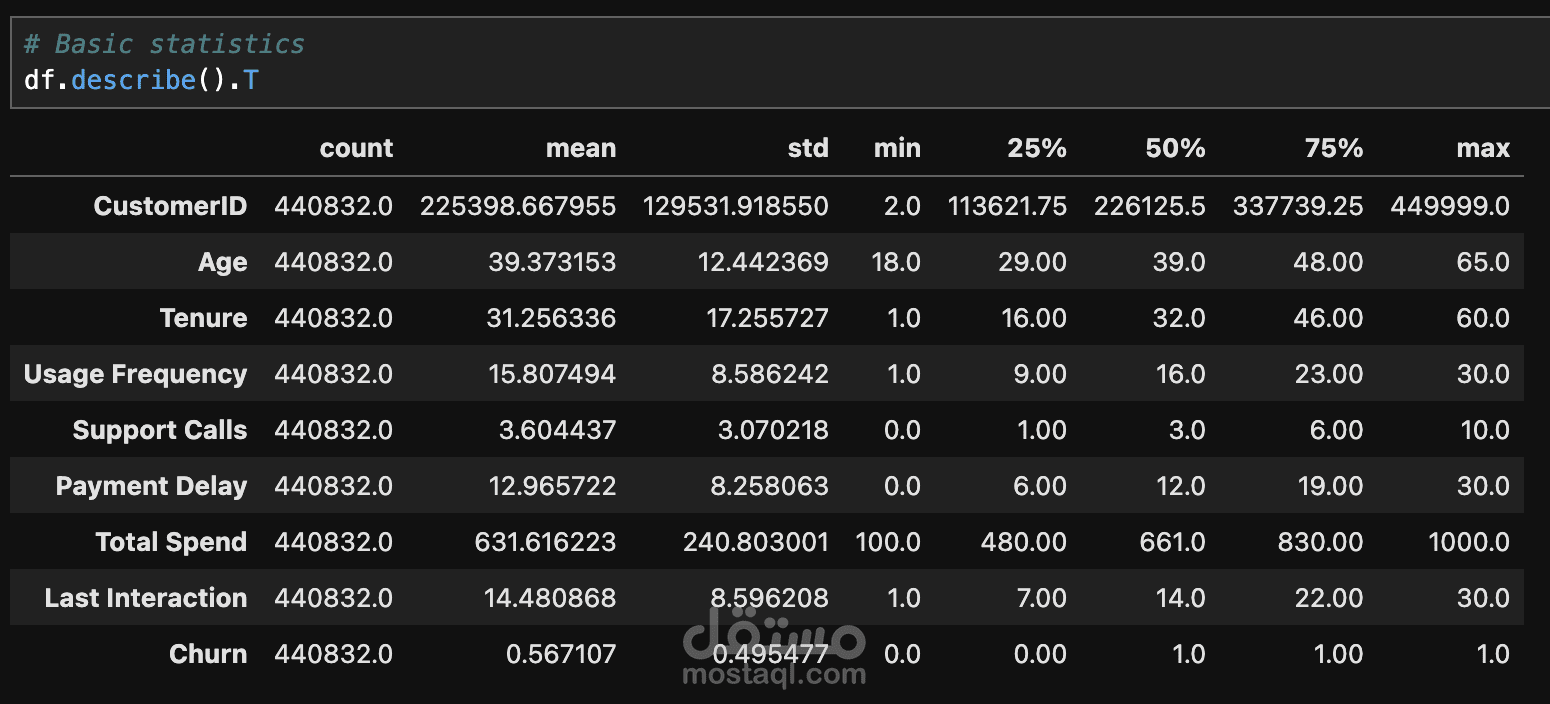
يهدف هذا المشروع إلى بناء نموذج Machine Learning باستخدام تقنية Stacking Model لتحليل وتصنيف البيانات بدقة عالية. تبدأ العملية بمعالجة البيانات (Data Cleaning) حيث يتم تنظيف البيانات من القيم المفقودة والشاذة، يليها مرحلة استكشاف البيانات (Exploratory Data Analysis - EDA) من خلال تقنيات التصور البياني (Data Visualization) لفهم الأنماط والعلاقات داخل البيانات.
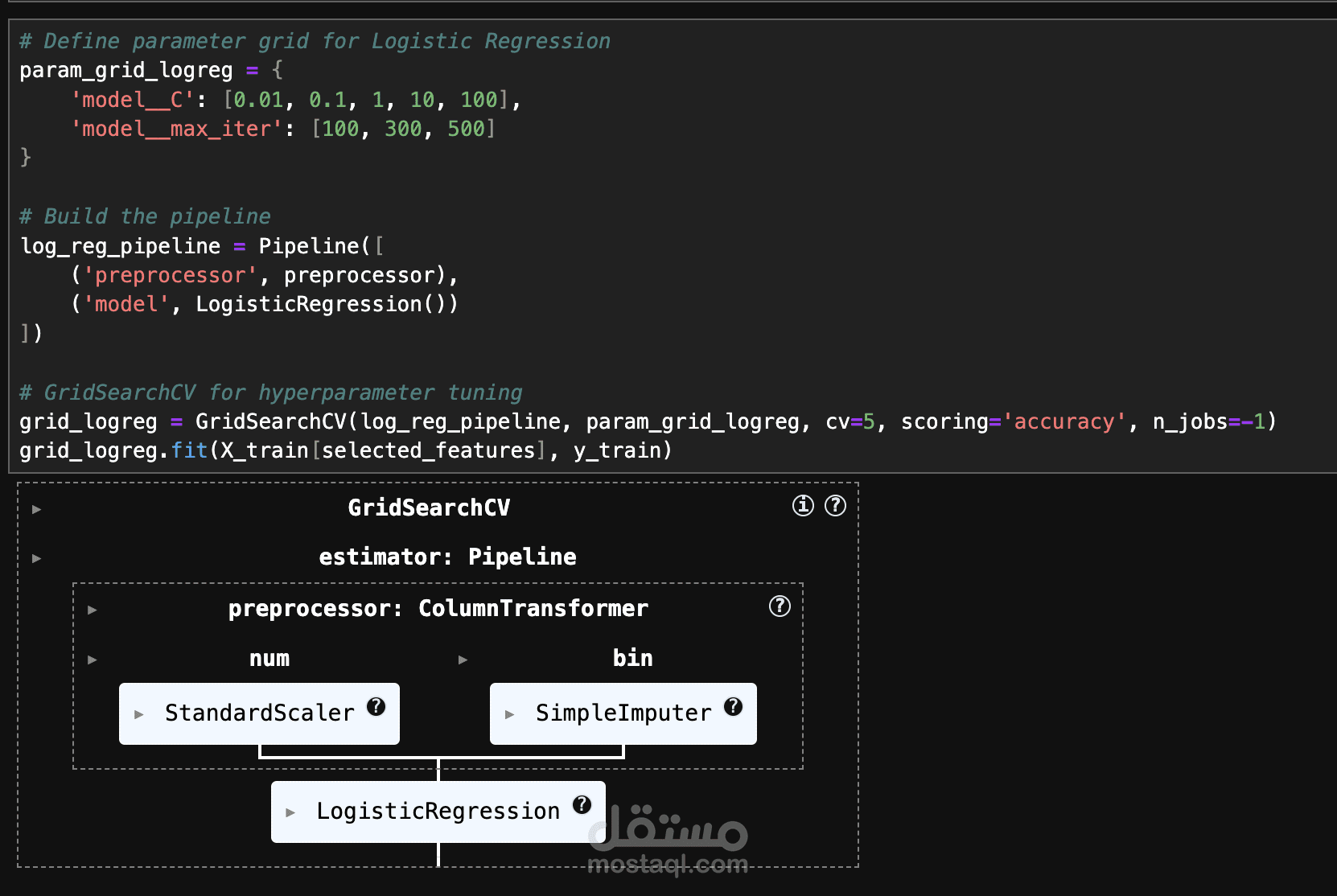
بعد ذلك، يتم تحضير البيانات (Data Preprocessing) عبر تحويلها إلى تنسيقات مناسبة، مثل التشفير (Encoding) وتطبيع القيم (Normalization) إذا لزم الأمر. ثم يتم بناء النموذج باستخدام Stacking Classifier، وهو أسلوب يجمع بين عدة Machine Learning Models لتحسين الأداء.
يتم تقييم النموذج باستخدام Confusion Matrix و Learning Curve لقياس الأداء واكتشاف أي Overfitting عبر تقنيات مثل Cross-validation و Regularization. أظهر النموذج دقة تصل إلى 96.98%، مما يعكس كفاءته في تصنيف البيانات بشكل موثوق.
هذا المشروع مناسب لتطبيقات مثل تحليل البيانات، الذكاء الاصطناعي، والتنبؤ بسلوك المستخدمين، مما يجعله مفيدًا في العديد من المجالات مثل التسويق الرقمي، الرعاية الصحية، والتمويل.