Model Accuracy Comparison for Diabetes Dataset
تفاصيل العمل
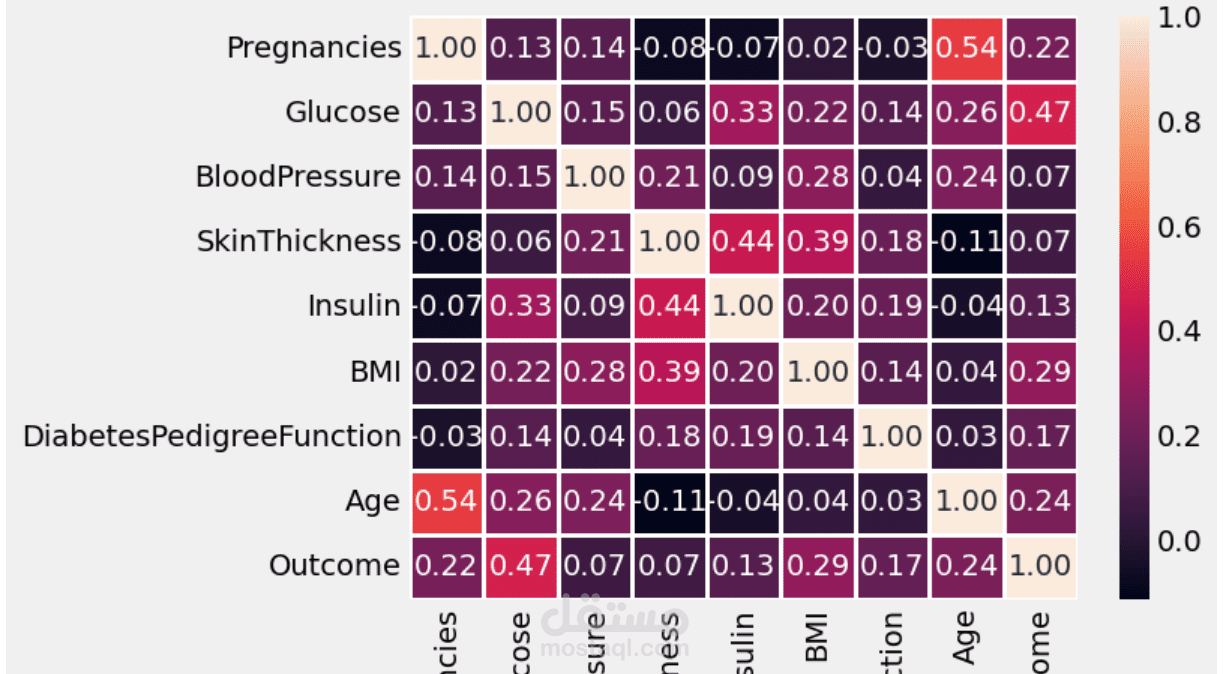
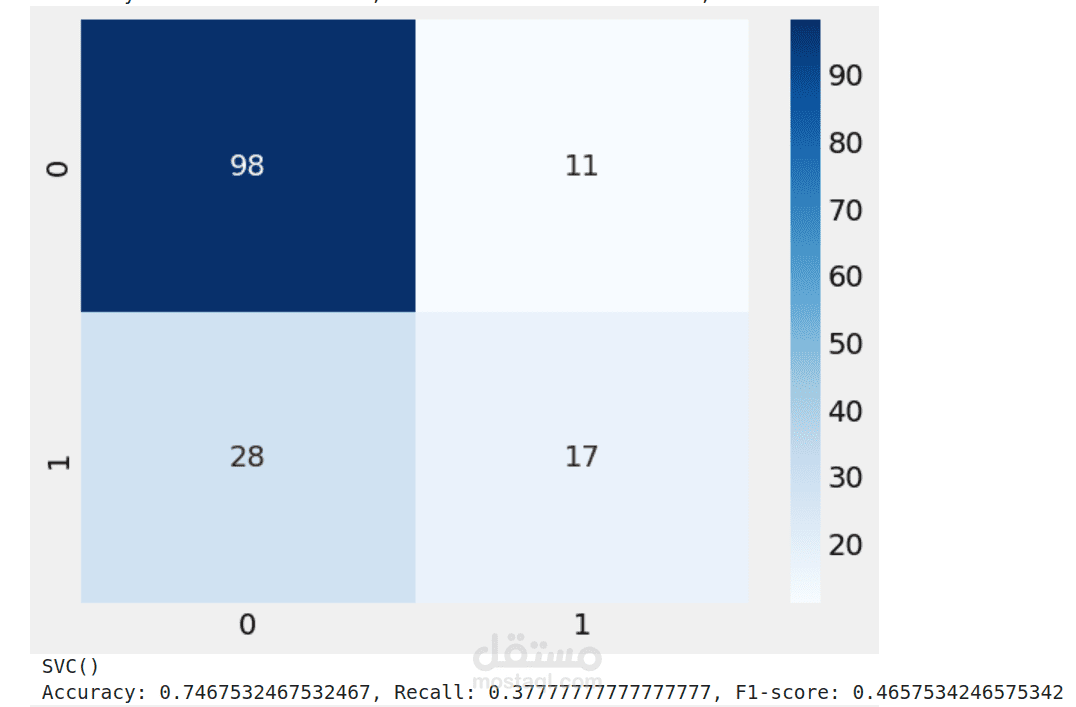
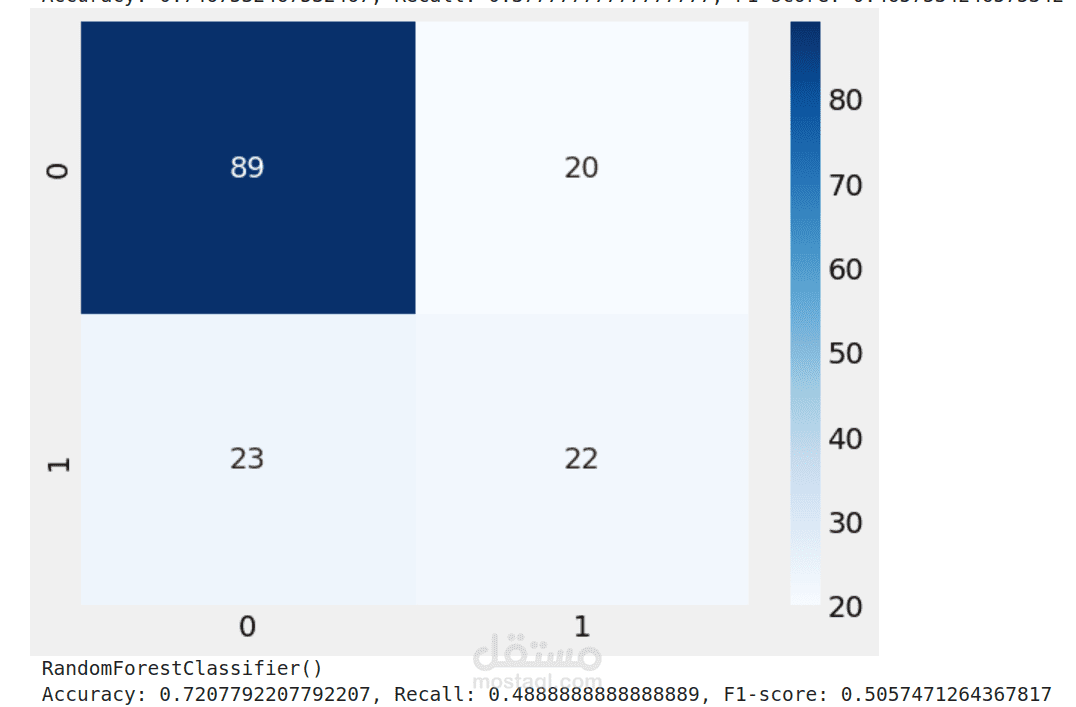
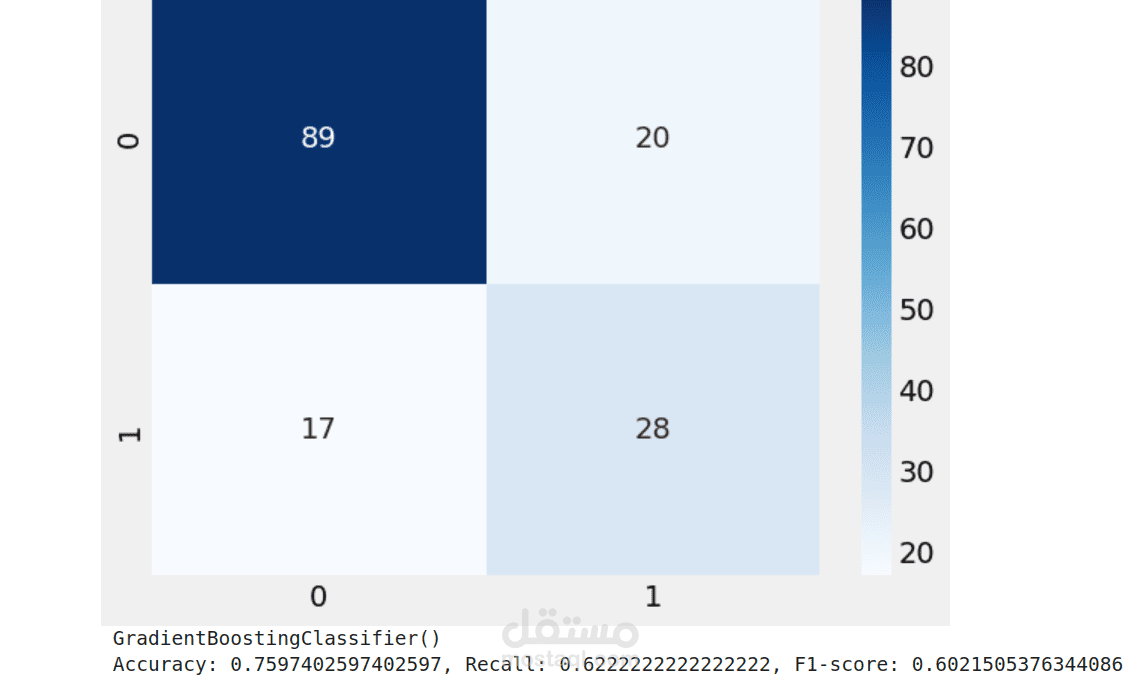
هذا المشروع كان تجربة حقيقية لمعرفة أي نموذج من نماذج تعلم الآلة يمكنه تقديم أفضل أداء في توقع مرض السكري. استخدمت بيانات تحتوي على عوامل طبية مثل نسبة الجلوكوز، ضغط الدم، الأنسولين، مؤشر كتلة الجسم، والعمر، ثم جربت عدة نماذج لمعرفة أيها يقدم نتائج أدق.
النماذج اللي استخدمتها
جربت أربعة نماذج مختلفة:
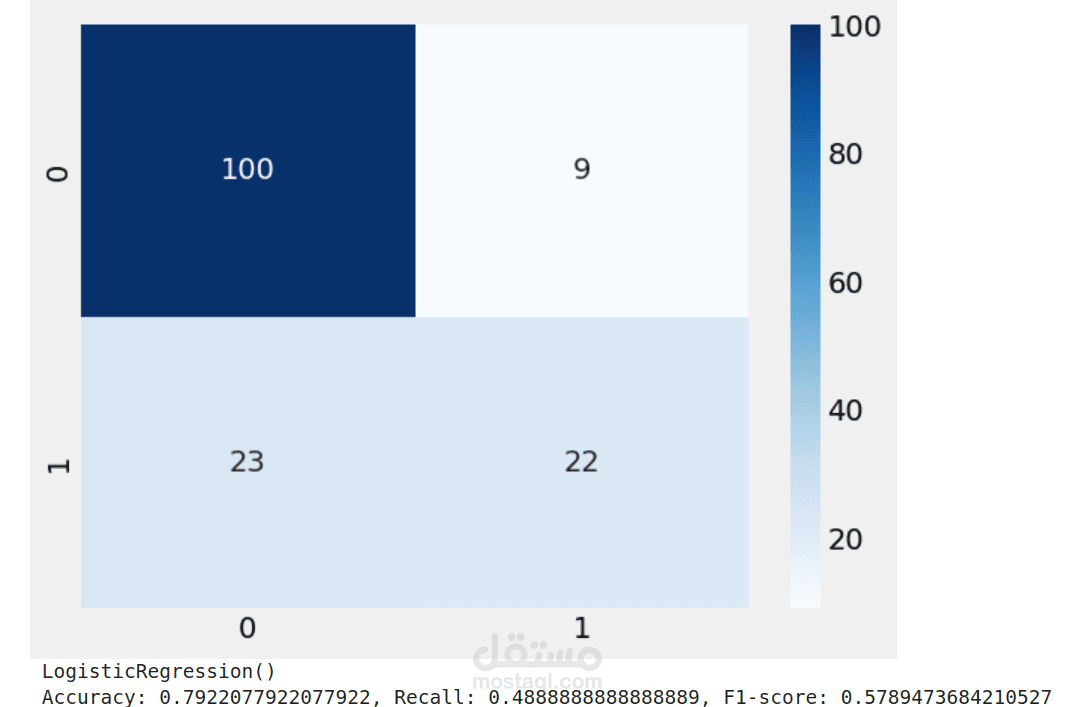
(Logistic Regression): نموذج بسيط لكنه فعال في بعض الحالات.
(SVC): يعتمد على إيجاد الحد الفاصل الأفضل بين الفئات، لكنه لم يكن الأفضل هنا.
(Random Forest): نموذج قوي يعتمد على عدة أشجار قرار، وكانت نتائجه جيدة.
(Gradient Boosting): نموذج متقدم يعتمد على تحسين التوقعات تدريجيًا، وكان الأفضل بينهم.
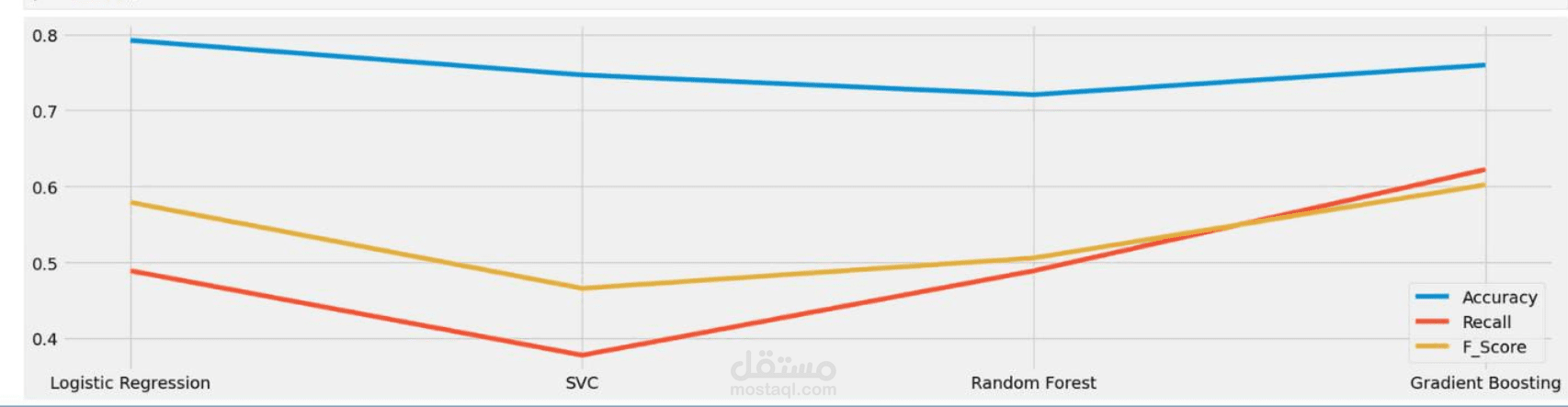
كيف قمت بتقييم النماذج؟
اعتمدت على ثلاث مقاييس أساسية:
(Accuracy): ببساطة، كم مرة توقع النموذج بشكل صحيح؟
F1 (F1-score): مقياس يوازن بين الدقة والاسترجاع، وهو مفيد جدًا عندما تكون البيانات غير متوازنة.
(Recall): كم عدد الحالات الإيجابية التي تمكن النموذج من التقاطها؟