مشروع تصنيف لمجموعة بيانات "الحب من اللقاء الأول"
تفاصيل العمل
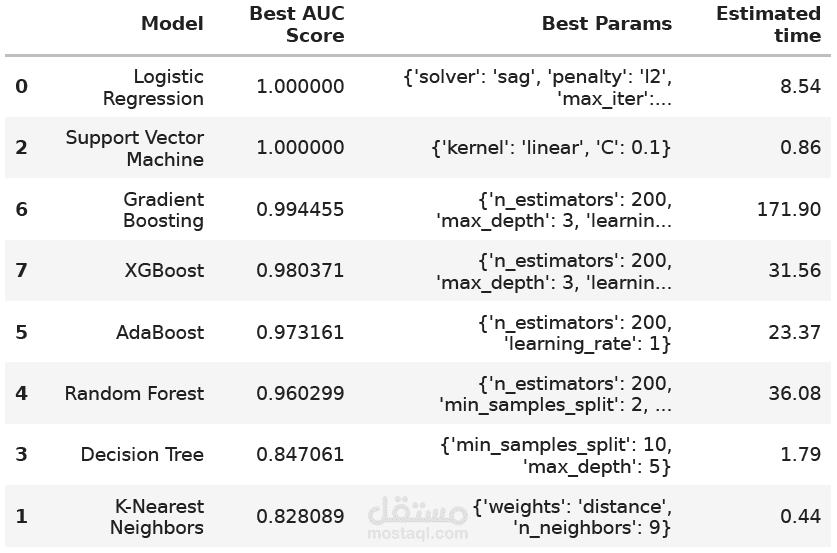
في هذا المشروع، تم تطوير نموذج تصنيف يعتمد على مجموعة بيانات "الحب من اللقاء الأول"، حيث تم تنفيذ مجموعة من الخطوات لمعالجة البيانات وتحليلها وتطوير نماذج تعلم آلي متعددة.
الخطوات المتبعة:
تنظيف البيانات ومعالجتها: شملت إزالة القيم المفقودة، التعامل مع القيم الشاذة، وتحويل المتغيرات الفئوية إلى تنسيقات قابلة للاستخدام في النماذج.
تحليل استكشافي للبيانات (EDA): تم تحليل توزيع البيانات، تحديد التباينات والارتباطات بين الميزات المختلفة، والتعامل مع البيانات غير المتوازنة باستخدام تقنيات مثل SMOTE.
تقليل الأبعاد (Dimensionality Reduction): تم تطبيق تحليل المكونات الرئيسية (PCA) لاستخلاص الميزات وتقليل التعقيد الحسابي.
بناء نماذج التصنيف: تم استخدام عدة خوارزميات مثل:
الانحدار اللوجستي
أقرب الجيران (KNN)
شجرة القرار
الآلة الداعمة للنقاط (SVM)
التعزيز التدريجي (Gradient Boosting)
أدا بوست (AdaBoost)
إكس جي بوست (XGBoost)
الغابة العشوائية (Random Forest)
تقييم الأداء: تمت مقارنة النماذج بناءً على مقياس AUC، حيث حقق كل من نموذج الانحدار اللوجستي وSVM درجة AUC كاملة بلغت 1، مما يدل على دقة عالية في التنبؤ بالنتائج.
يبرز هذا المشروع أهمية معالجة البيانات بفعالية قبل بناء النماذج، كما يعكس القدرة على استخدام وتقييم خوارزميات تعلم الآلة لاختيار النموذج الأمثل لمشكلة التصنيف.