Amazon Web Scraping
تفاصيل العمل
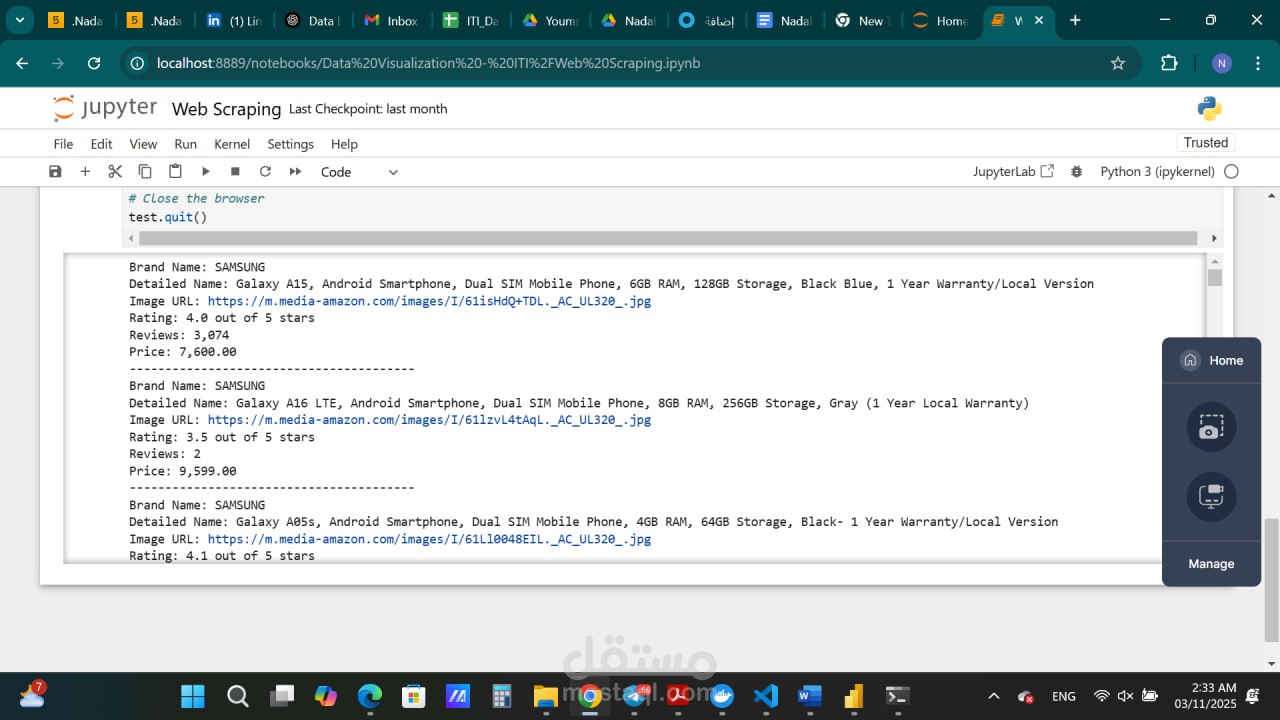
This web scraping script uses **Selenium** to extract product details from an e-commerce website, Amazon. It first locates all product listings on the page using XPath, then loops through each product to extract key details such as the **brand name, product title, image URL, rating, number of reviews, and price**. The script includes **error handling** to assign default values if any information is missing. Finally, it prints the extracted data in a structured format and **closes the browser session** to free up resources.