تحليل سلوك عملاء التجارة الإلكترونية
تفاصيل العمل




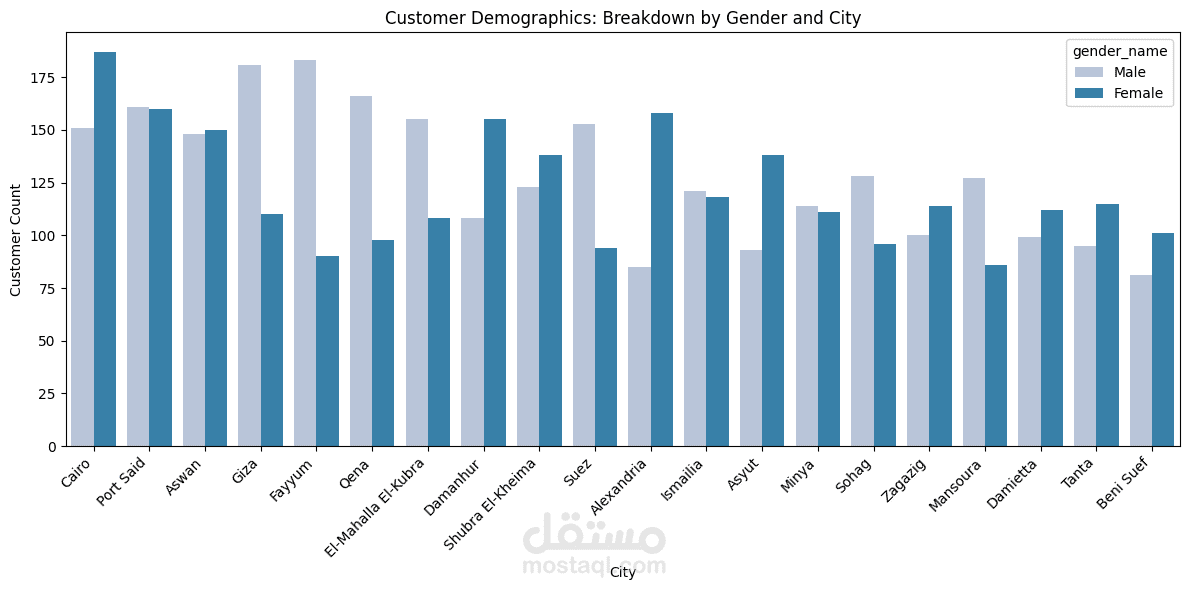

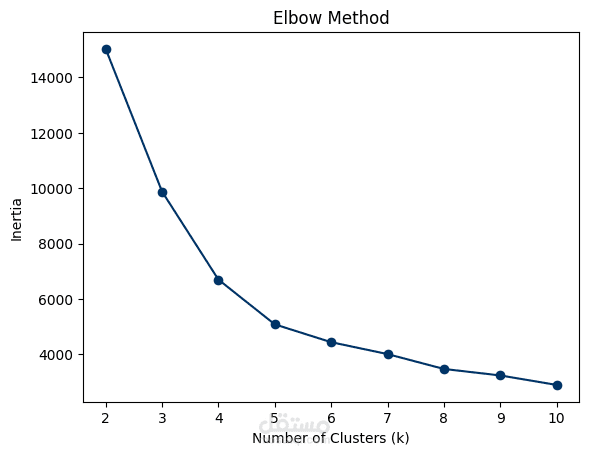
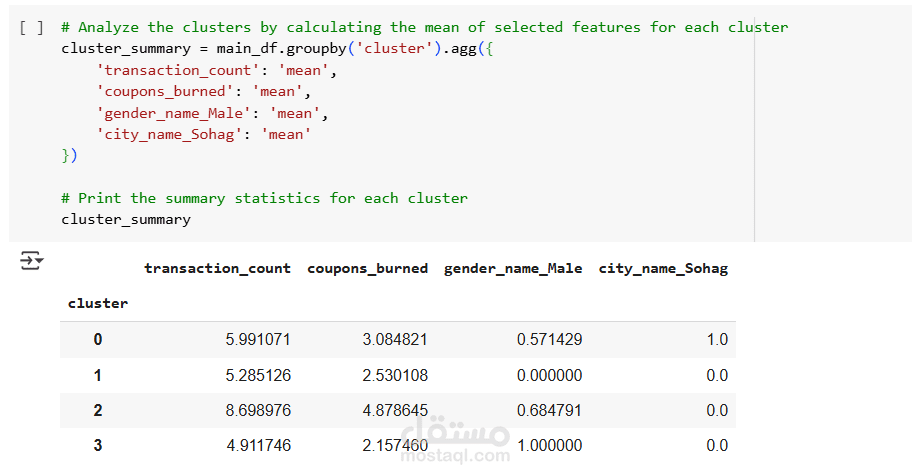
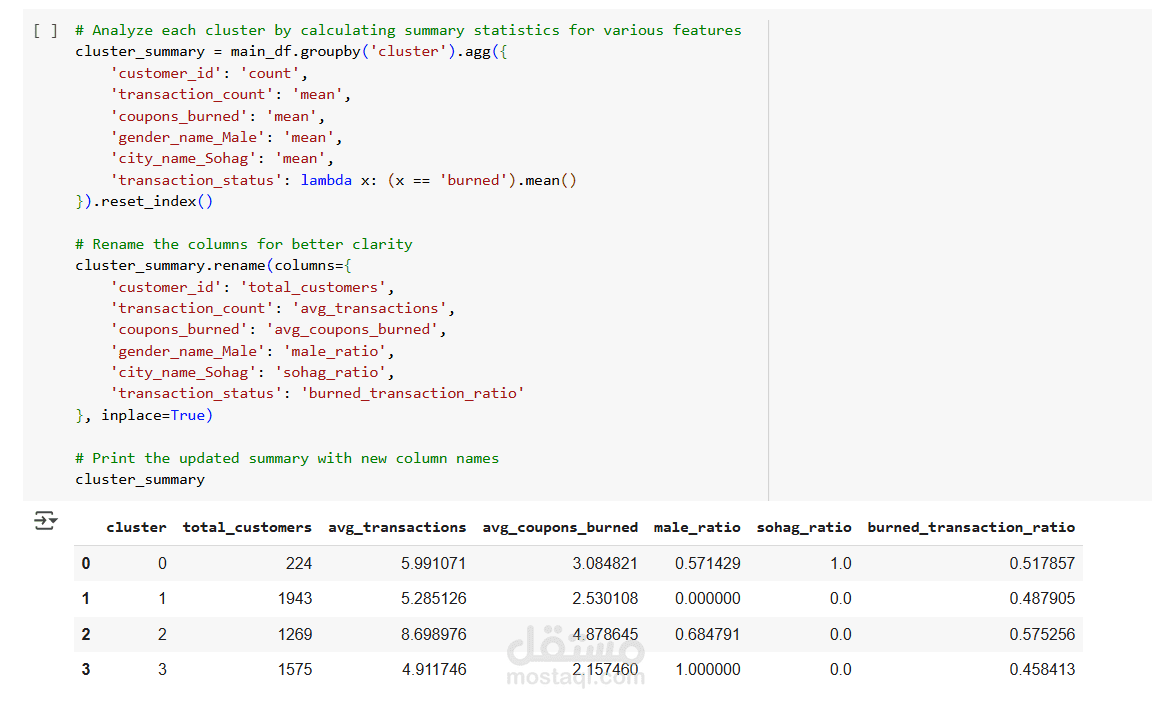
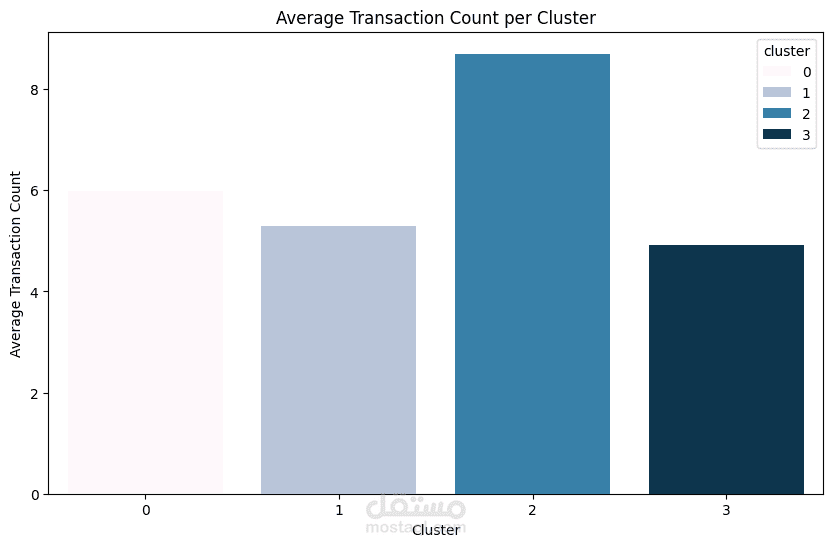

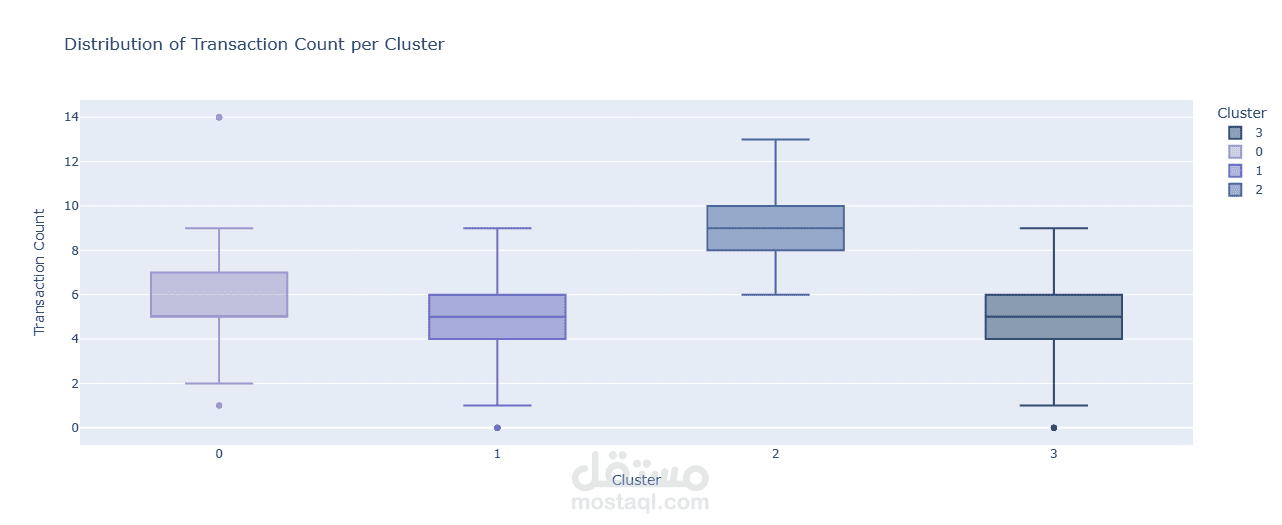

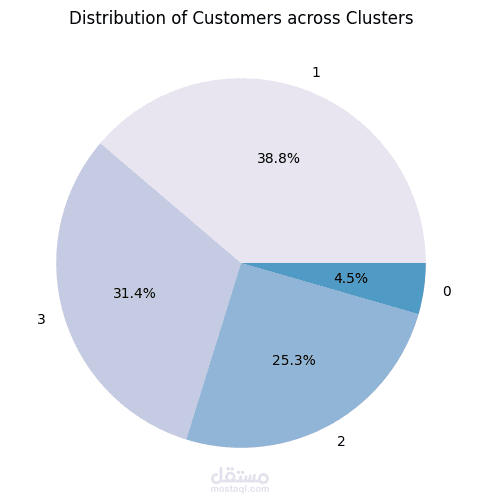

يهدف هذا المشروع إلى تحليل بيانات العملاء وتصنيفهم باستخدام تقنيات تحليل البيانات والتعلم الآلي، وذلك لاستخراج أنماط السلوك الشرائي وتقديم استراتيجيات تسويقية مخصصة. يعتمد المشروع على خوارزمية K-Means Clustering لتقسيم العملاء إلى مجموعات بناءً على معدل الشراء، استخدام القسائم الشرائية، والموقع الجغرافي.
-- المهام التي تم تنفيذها:
- تنظيف البيانات وإزالة القيم المفقودة والتكرارات.
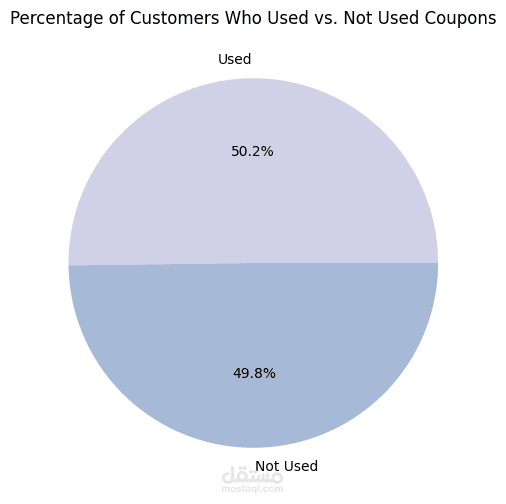
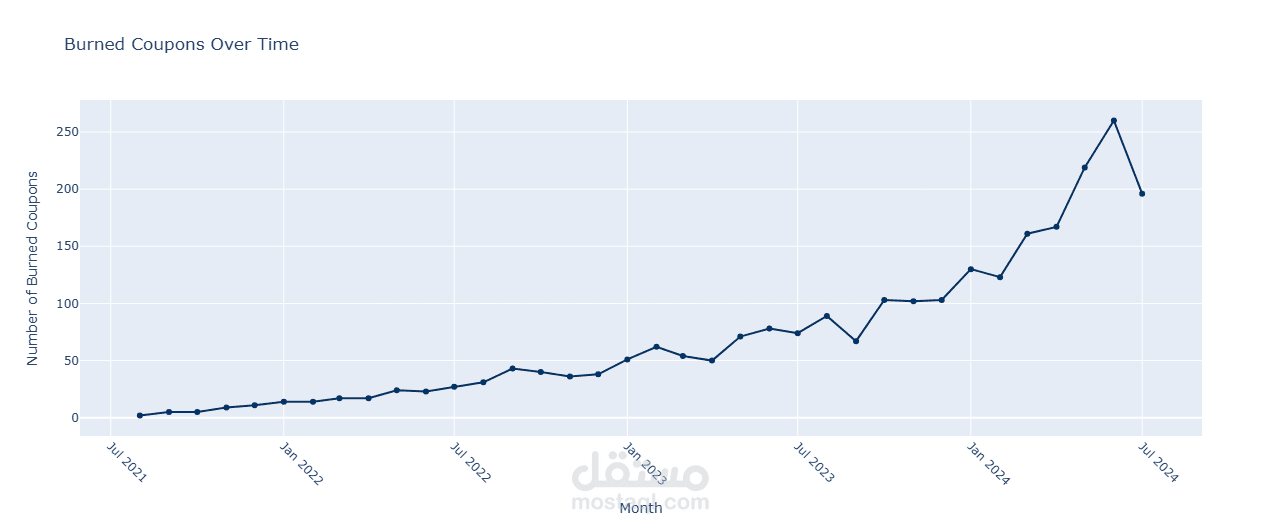
- تحليل استخدام القسائم الشرائية ومعرفة نسبة العملاء الذين لم يستخدموها.
- تصنيف العملاء باستخدام K-Means Clustering لاكتشاف الفئات المختلفة من العملاء.
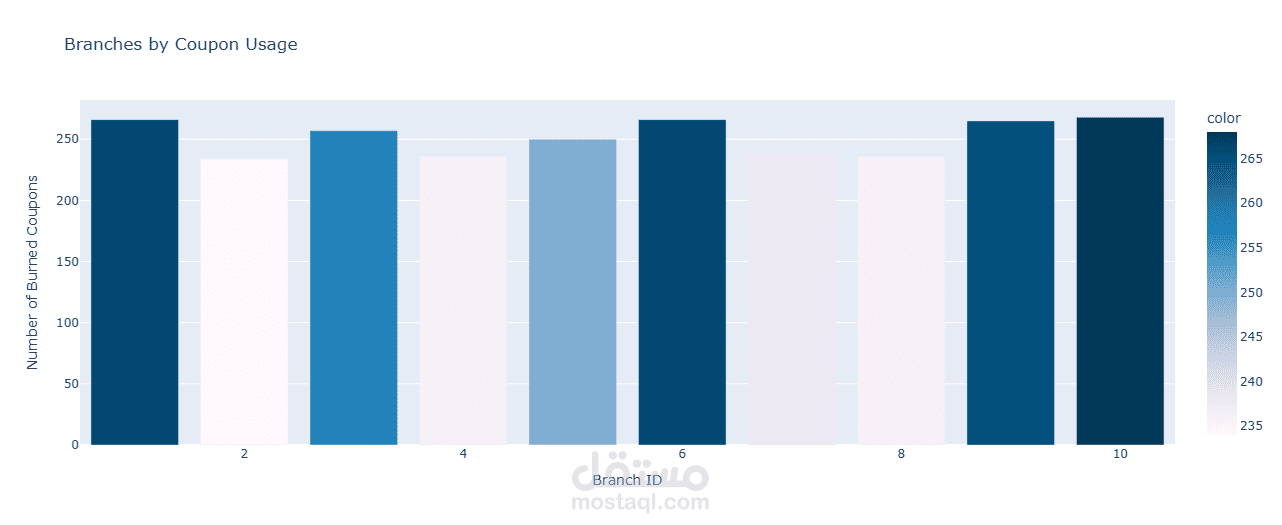
- تحديد المدن الأكثر نشاطًا من حيث استخدام القسائم.
- تصميم لوحات بيانات تفاعلية باستخدام Matplotlib و Seaborn و Plotly.
- تقييم جودة التصنيف باستخدام مؤشر Silhouette Score.
-- التقنيات والأدوات المستخدمة:
- لغة البرمجة: Python
- المكتبات: Pandas، NumPy، Scikit-learn، Matplotlib، Seaborn، Plotly
- خوارزميات الذكاء الاصطناعي: K-Means Clustering
- تحليل البيانات والتصورات البيانية
-- نتائج المشروع:
- تصنيف العملاء إلى 4 مجموعات رئيسية بناءً على سلوكهم الشرائي.
- اكتشاف أن 50% من القسائم لم تُستخدم، مما يشير إلى فرصة لتحسين استراتيجيات التسويق.
- اقتراح تحسينات في استراتيجيات التسويق، مثل إرسال تذكيرات للعملاء وتخصيص العروض حسب سلوكهم.
-- كيف يمكن الاستفادة منه؟
يمكن استخدام هذا النظام من قبل الشركات لفهم عملائها بشكل أعمق، وتحسين استراتيجيات التسويق، وزيادة معدل استخدام القسائم الشرائية لتحقيق زيادة في المبيعات وتحسين تجربة العملاء.
-- هل لديك مشروع مشابه؟
إذا كنت بحاجة إلى تحليل بيانات العملاء وتحسين استراتيجيات التسويق باستخدام الذكاء الاصطناعي، لا تتردد في التواصل معي!