titanic dataset
تفاصيل العمل
وصف مشروع تحليل بيانات الركاب على متن سفينة تايتانيك باستخدام التعلم الآلي
نبذة عن المشروع:
يهدف هذا المشروع إلى تحليل وتصنيف بيانات الركاب على متن سفينة تايتانيك باستخدام تقنيات التعلم الآلي، وذلك من خلال بناء نموذج يعتمد على خوارزمية الغابة العشوائية (Random Forest) للتنبؤ باحتمالية نجاة الركاب بناءً على مجموعة من الميزات الديموغرافية والسلوكية.
أهداف المشروع:
معالجة وتحليل البيانات لتحديد العوامل الأكثر تأثيرًا في نجاة الركاب.
بناء نموذج تصنيف دقيق باستخدام خوارزمية Random Forest.
تقييم أداء النموذج من خلال مقاييس مثل الدقة، الاسترجاع، F1-score، ومصفوفة الالتباس.
عرض تصورات بصرية متقدمة تساعد في فهم أداء النموذج وأهمية الميزات المستخدمة.
️ التقنيات والأدوات المستخدمة:
Python لتنفيذ وتحليل البيانات.
Pandas و NumPy لتنظيف البيانات وتحليلها.
Scikit-learn لتطبيق نماذج التعلم الآلي واختبارها.
Seaborn و Matplotlib لإنشاء تصورات بصرية متقدمة.
تحليل وتقييم الأداء:
تم استخدام مجموعة متنوعة من المقاييس والتصورات البصرية لتقييم النموذج، ومنها:
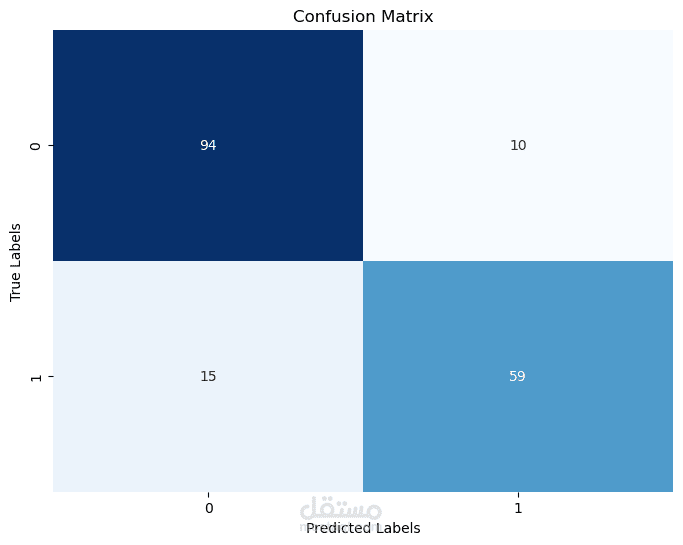
مصفوفة الالتباس (Confusion Matrix): لتوضيح صحة التصنيفات التي قام بها النموذج.
مخطط الدقة والاسترجاع لكل فئة: لتحليل أداء النموذج في تصنيف الناجين وغير الناجين.
أهمية الميزات (Feature Importance): لتحديد المتغيرات الأكثر تأثيرًا في توقع النجاة.
منحنى ROC-AUC: لتقييم جودة النموذج في التمييز بين الفئات المختلفة.
إمكانيات التوسع:
يمكن تحسين هذا النموذج من خلال تجربة خوارزميات أخرى مثل SVM و XGBoost، أو باستخدام تقنيات تعزيز النموذج مثل تحسين المعلمات Grid Search. بالإضافة إلى ذلك، يمكن توسيع نطاق المشروع ليشمل تحليل بيانات أخرى مماثلة في مجالات مختلفة مثل تحليل سلوك العملاء أو التنبؤ بنتائج العمليات الطبية.
يوفر المشروع حلاً فعالًا لدراسة العوامل المؤثرة في النجاة على متن تايتانيك، مع إمكانية تطبيق الأساليب المستخدمة في مجالات متعددة من تحليل البيانات والتعلم الآلي.