Iris data set
تفاصيل العمل
وصف مشروع تصنيف الأزهار باستخدام خوارزمية KNN
نبذة عن المشروع:
يهدف هذا المشروع إلى تطوير نموذج ذكاء اصطناعي يعتمد على خوارزمية K-Nearest Neighbors (KNN) لتصنيف أنواع الأزهار بدقة، وذلك بالاعتماد على خصائصها الفيزيائية مثل طول وعرض البتلة والكأس. يستخدم النموذج مجموعة بيانات Iris، ويعتمد على معالجة البيانات وتحليلها للوصول إلى أدق النتائج الممكنة.
أهداف المشروع:
تطوير نموذج تصنيف فعال يمكنه التمييز بين أنواع الأزهار بناءً على بيانات جديدة.
تحسين دقة التصنيف من خلال تجربة عدة قيم لـ K واختيار القيمة المثلى.
تقديم تحليلات بصرية متقدمة لشرح أداء النموذج وتعزيز فهم العميل لآلية التصنيف.
️ التقنيات والأدوات المستخدمة:
Python - لتنفيذ الخوارزميات ومعالجة البيانات.
Pandas, NumPy - لتحليل البيانات وتنظيفها.
Scikit-learn - لبناء نموذج KNN وتقييمه.
Seaborn, Matplotlib - لإنشاء تصورات ورسوم بيانية توضيحية.
تحليل وتقييم الأداء:
يتم تقييم النموذج باستخدام مجموعة من الأدوات الإحصائية والبصرية، بما في ذلك:
مصفوفة الارتباك (Confusion Matrix) لتوضيح دقة التصنيف لكل فئة.
تقرير التصنيف (Classification Report) لقياس أداء النموذج باستخدام معايير الدقة والاسترجاع وF1-score.
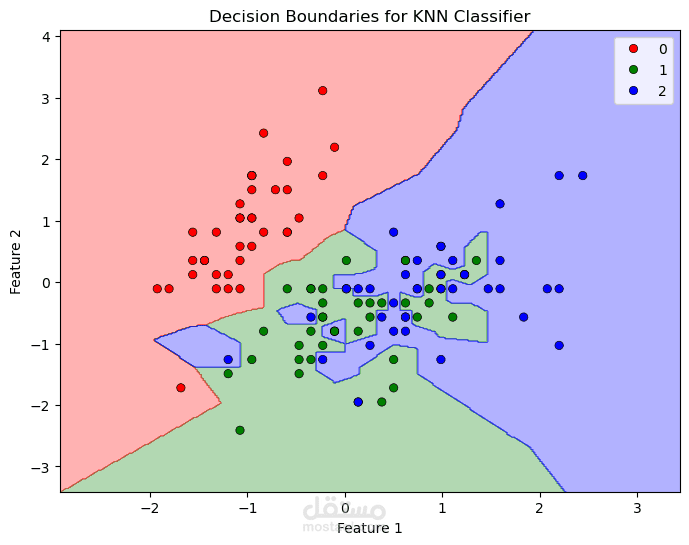
رسم حدود القرار (Decision Boundaries) لتمثيل كيفية تصنيف النموذج للبيانات الجديدة.
مخطط دقة التصنيف مقابل عدد الجيران (K) لمقارنة تأثير عدد الجيران على أداء النموذج.
إمكانيات التوسع:
يمكن استخدام هذه المنهجية كأساس لتطوير أنظمة تصنيف أخرى في مجالات متعددة، مثل تصنيف المنتجات، تحليل الصور الطبية، والتعرف على الأنماط، مما يجعل المشروع قابلاً للتخصيص والتطوير وفقًا لمتطلبات الأعمال المختلفة.
يقدم المشروع نموذجًا احترافيًا يجمع بين الدقة، الكفاءة، والتحليل المتقدم، مما يجعله أداة قيمة في مجال تصنيف البيانات.