مشروع التنبؤ بأسعار السيارات باستخدام التعلم الآلي
تفاصيل العمل

نظرة عامة على المشروع:
يهدف هذا المشروع إلى التنبؤ بأسعار السيارات بناءً على مجموعة من العوامل مثل الماركة، الطراز، العام، عدد الأميال، اللون، نوع الوقود، والموقع. سيتم استخدام نماذج التعلم الآلي لتحليل البيانات والتوصل إلى أفضل نموذج يمكنه التنبؤ بأسعار السيارات بدقة.
مميزات المشروع:
التنبؤ بسعر السيارة بناءً على ميزات مختلفة مثل الطراز، العام، والمسافة المقطوعة.
تحليل العوامل المؤثرة في سعر السيارة مثل النوع، العمر، والموقع الجغرافي.
تطبيق نماذج تعلم الآلة للحصول على توقعات دقيقة.
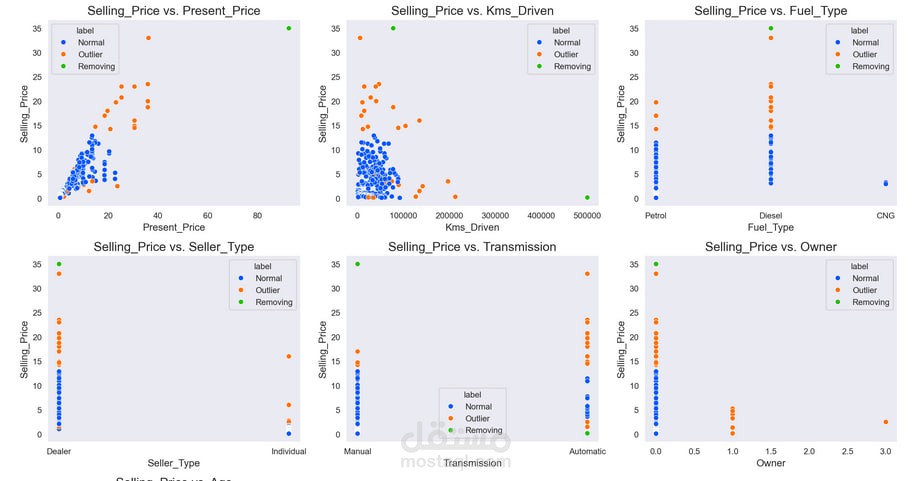
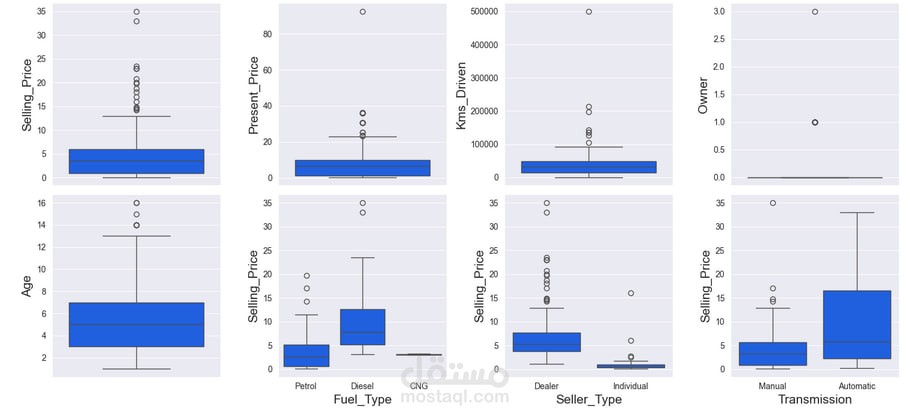
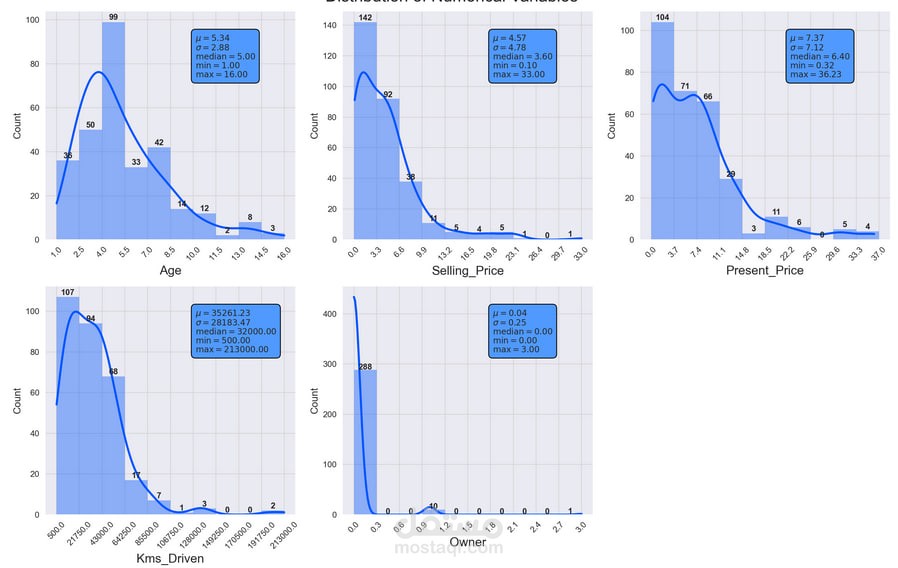
تحليل البيانات باستخدام الرسوم البيانية لفهم العلاقات بين العوامل.
نشر النموذج عبر واجهة API لتقديم التوقعات في الوقت الفعلي.
تحليل وتحسين النموذج باستخدام خوارزميات مثل الغابات العشوائية (Random Forest).
وصف مجموعة البيانات:
ستحتوي مجموعة البيانات على الأعمدة التالية:
اسم العمودالوصف
makeماركة السيارة (مثل تويوتا، فورد)
modelطراز السيارة
yearسنة الصنع
mileageالمسافة المقطوعة (بالميل)
fuel_typeنوع الوقود (بنزين، ديزل)
colorلون السيارة
locationالموقع الجغرافي
priceالسعر (المتغير الهدف)
الأدوات والتقنيات المستخدمة:
1. تحليل البيانات ومعالجتها
Pandas – لمعالجة البيانات وتنظيفها.
NumPy – لإجراء العمليات الحسابية.
Matplotlib & Seaborn – لإنشاء الرسوم البيانية وتحليل البيانات.
2. نماذج التعلم الآلي
Scikit-Learn – لتدريب النماذج.
الانحدار الخطي (Linear Regression) – لتقديم التوقعات الأساسية.
الغابات العشوائية (Random Forest) – للحصول على دقة أعلى.
XGBoost – لتحسين النموذج وتحقيق أداء أفضل.
3. نشر النموذج
Flask أو FastAPI – لتطوير واجهة API لنشر النموذج.
Streamlit – لإنشاء واجهة تفاعلية.
خطوات تنفيذ المشروع:
1. استكشاف البيانات ومعالجتها
تحميل البيانات من ملفات CSV أو مصادر بيانات أخرى.
معالجة القيم المفقودة أو البيانات الغير مكتملة.
تحويل البيانات الفئوية (مثل الماركة، نوع الوقود، اللون) إلى قيم رقمية باستخدام One-Hot Encoding.
تطبيع البيانات إذا كان ذلك ضرورياً مثل تحويل المسافة المقطوعة إلى قيم منطقية.
2. تحليل البيانات واكتشاف الأنماط
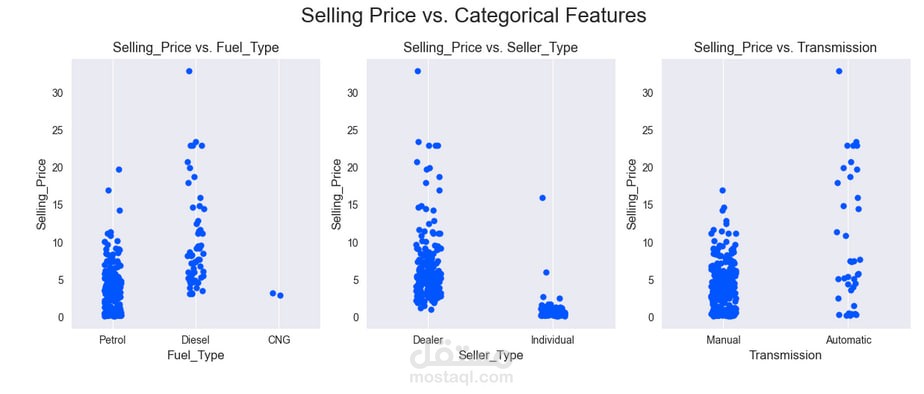
رؤية الرسوم البيانية لفهم العلاقة بين المتغيرات المختلفة مثل "الماركة" و "السعر".
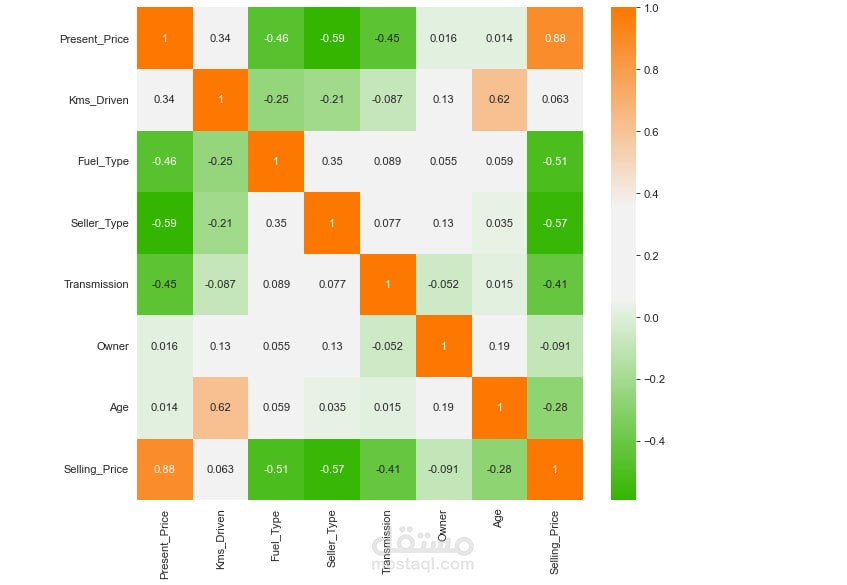
التحليل الحراري (Heatmap) لعرض الترابط بين الأعمدة المختلفة.
التحقق من التوزيع باستخدام Boxplots و Histograms.
3. تدريب النموذج
تقسيم البيانات إلى 80% للتدريب و 20% للاختبار.
تطبيق الانحدار الخطي و الغابات العشوائية.
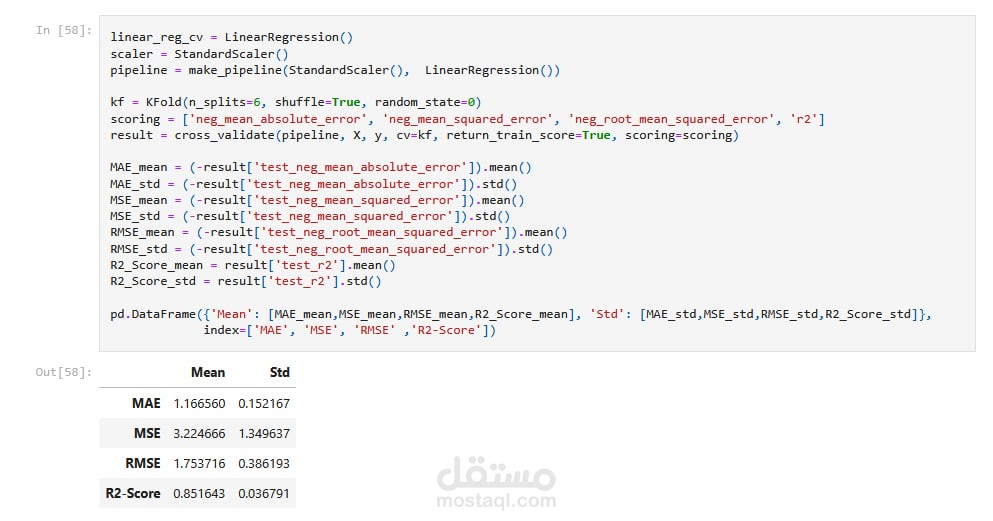
تقييم النموذج باستخدام متوسط الخطأ المطلق (MAE) و معامل التحديد (R² Score).
4. نشر النموذج للاستخدام الفعلي
حفظ النموذج المدرب باستخدام Joblib أو Pickle.
تطوير واجهة API باستخدام Flask أو FastAPI لنشر النموذج.