مشروع استخراج البيانات من موقع Jumia
تفاصيل العمل
وصف المشروع:
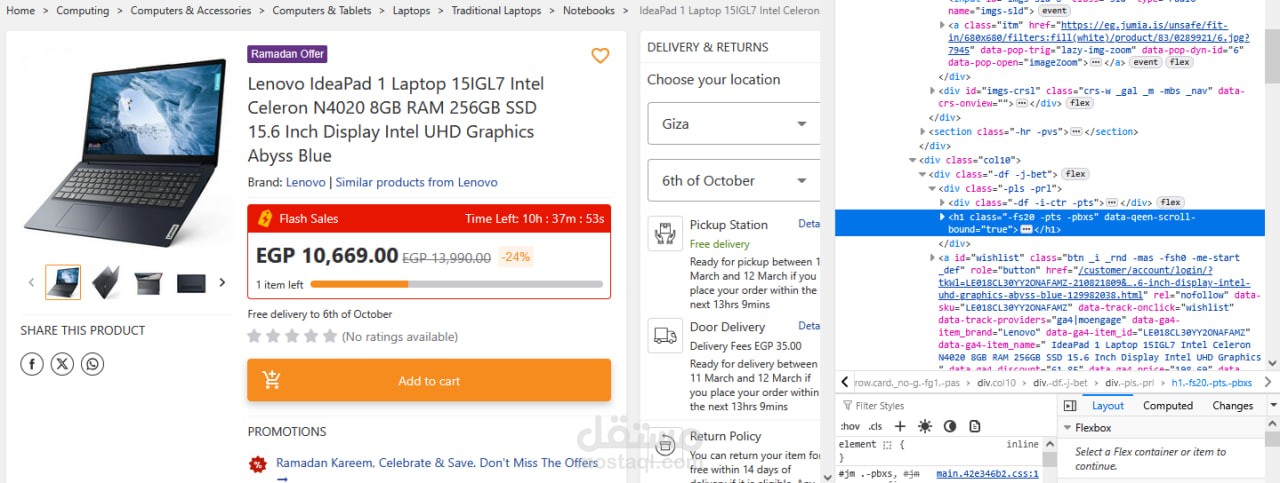
يهدف هذا المشروع إلى استخراج وتحليل بيانات المنتجات من موقع Jumia باستخدام Selenium و BeautifulSoup. يعتمد على Selenium للتعامل مع المواقع الديناميكية التي تعتمد على JavaScript، بينما يتم استخدام BeautifulSoup لتحليل واستخراج البيانات من صفحات HTML. يمكن استخدام هذه البيانات في تحليل السوق، مقارنة الأسعار، مراقبة المنافسين، وإنشاء أنظمة توصيات للمنتجات.
المميزات الأساسية للمشروع:
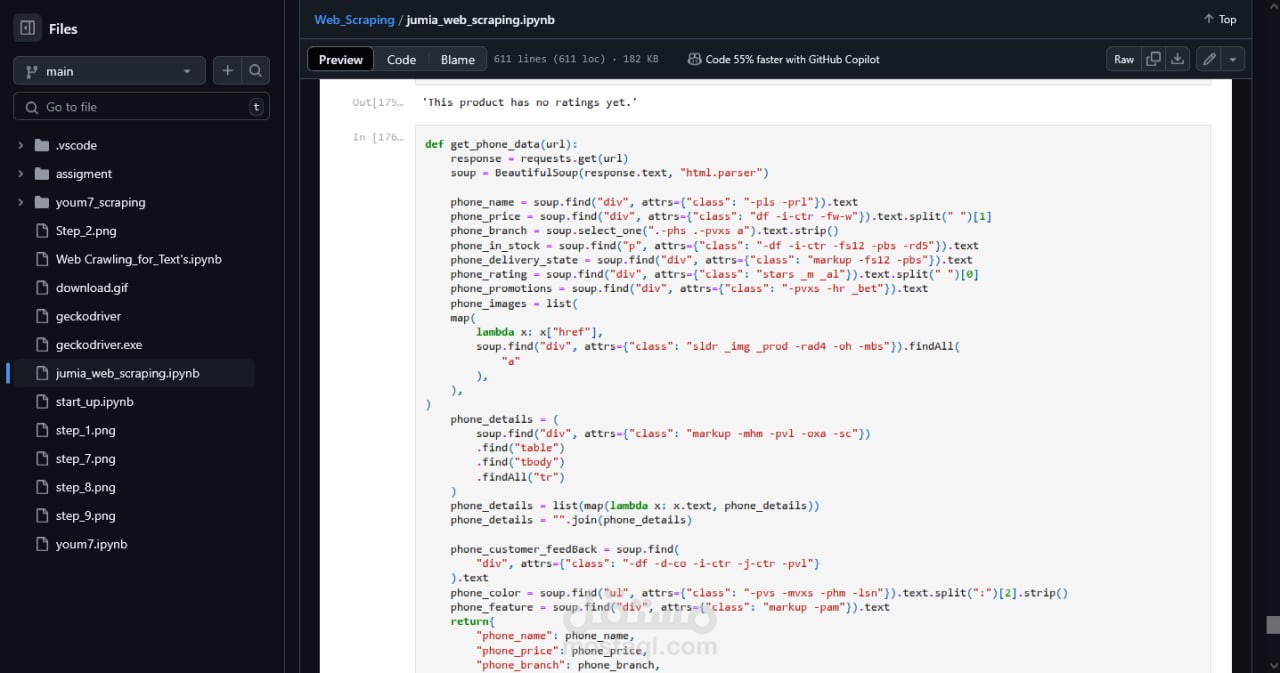
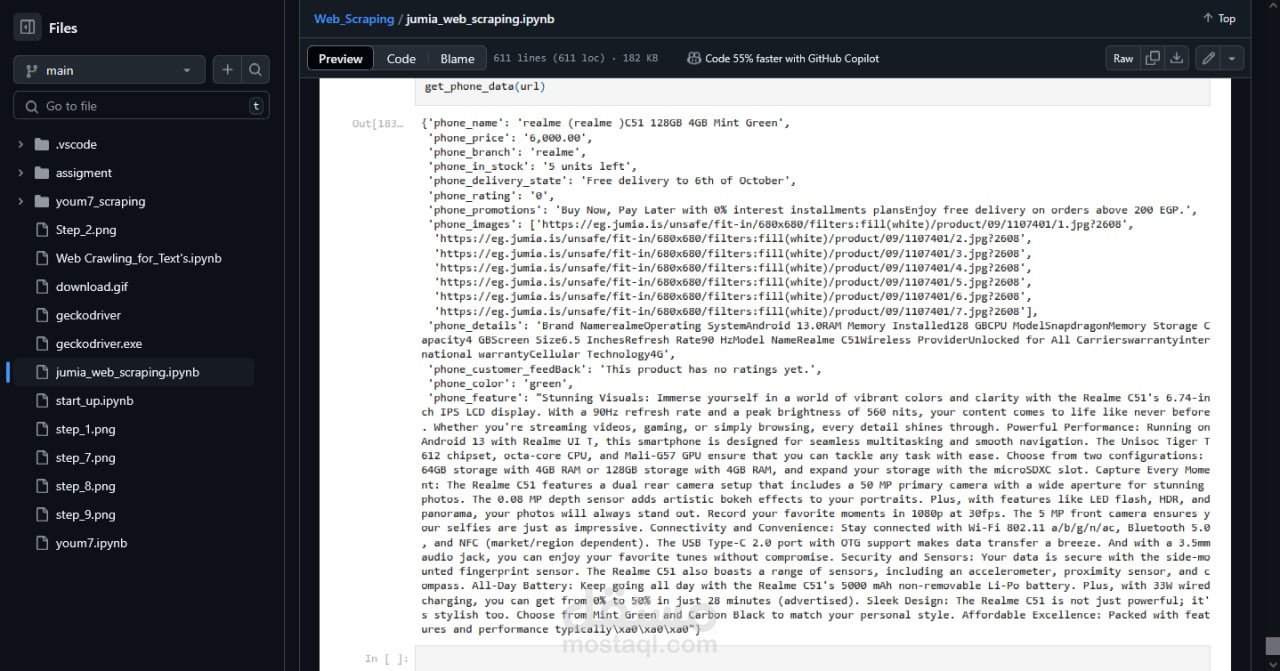
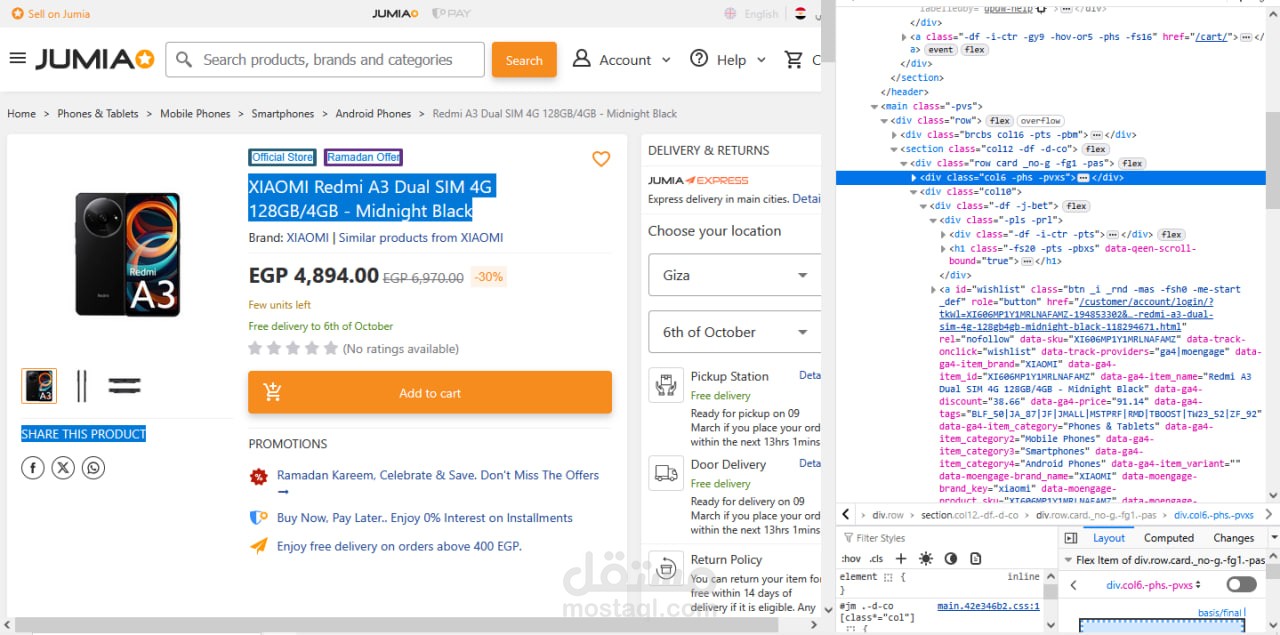
استخراج بيانات المنتجات تلقائيًا: الاسم، السعر، الوصف، التقييمات، عدد المراجعات، وتوافر المنتج.
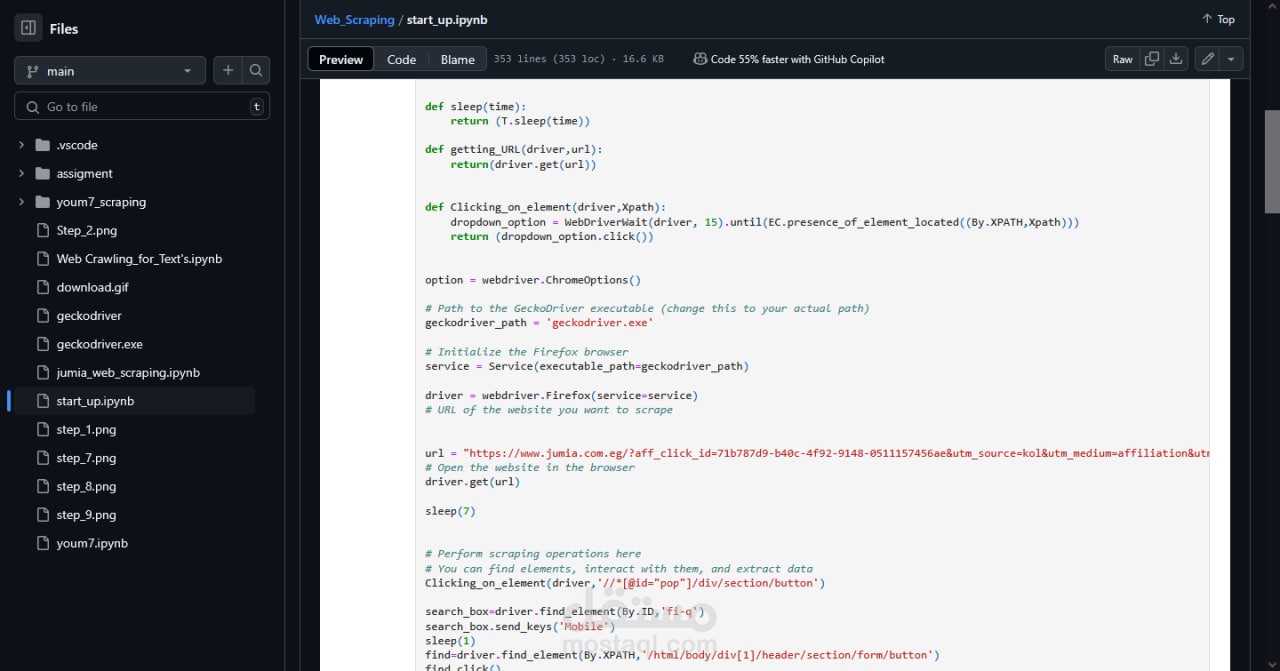
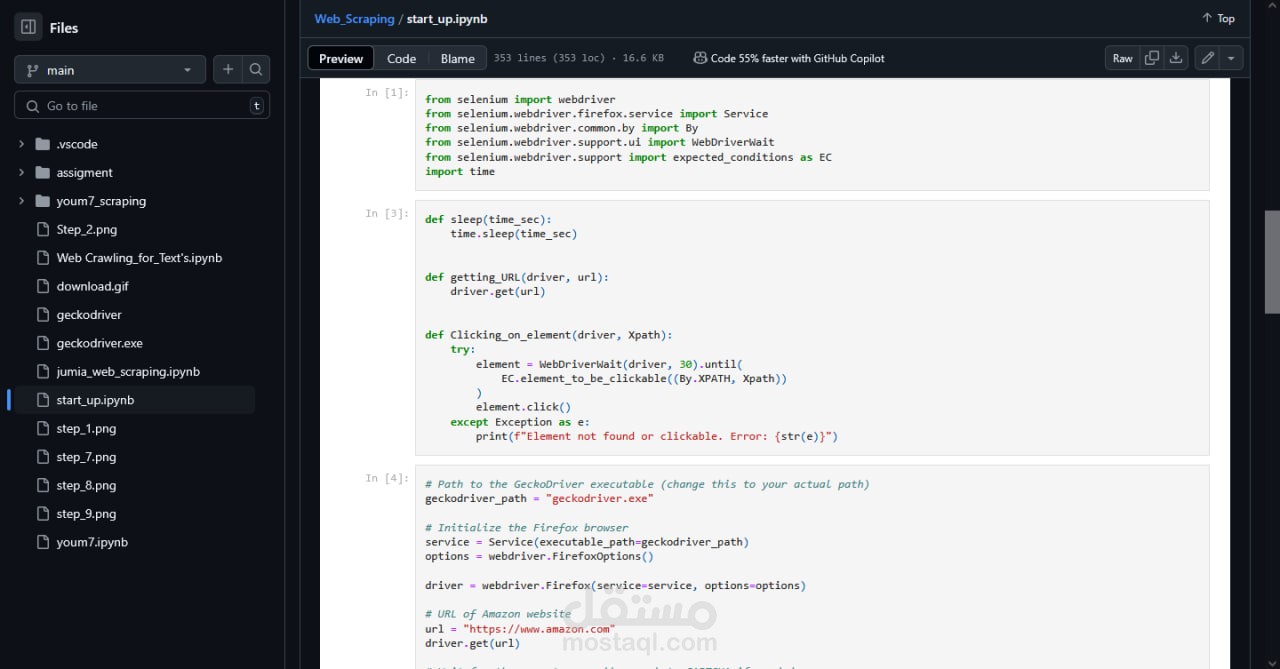
التعامل مع المواقع الديناميكية: باستخدام Selenium لتحميل الصفحات التي تعتمد على JavaScript.
استخدام BeautifulSoup لتحليل HTML واستخراج البيانات بسرعة وكفاءة.
التنقل بين صفحات المنتجات تلقائيًا لجمع البيانات من عدة صفحات.
تخزين البيانات في CSV أو قاعدة بيانات (MongoDB / MySQL) لاستخدامها في التحليل.
تحليل الأسعار والتقييمات لمعرفة المنتجات الأكثر شيوعًا والأفضل مبيعًا.
دعم اللغة العربية لاستخراج وتحليل البيانات بلغتين (العربية والإنجليزية).
إنشاء واجهة برمجية (API) أو لوحة تحكم لعرض البيانات بطريقة مرئية.
الأدوات والتقنيات المستخدمة:
1. استخراج البيانات من Jumia
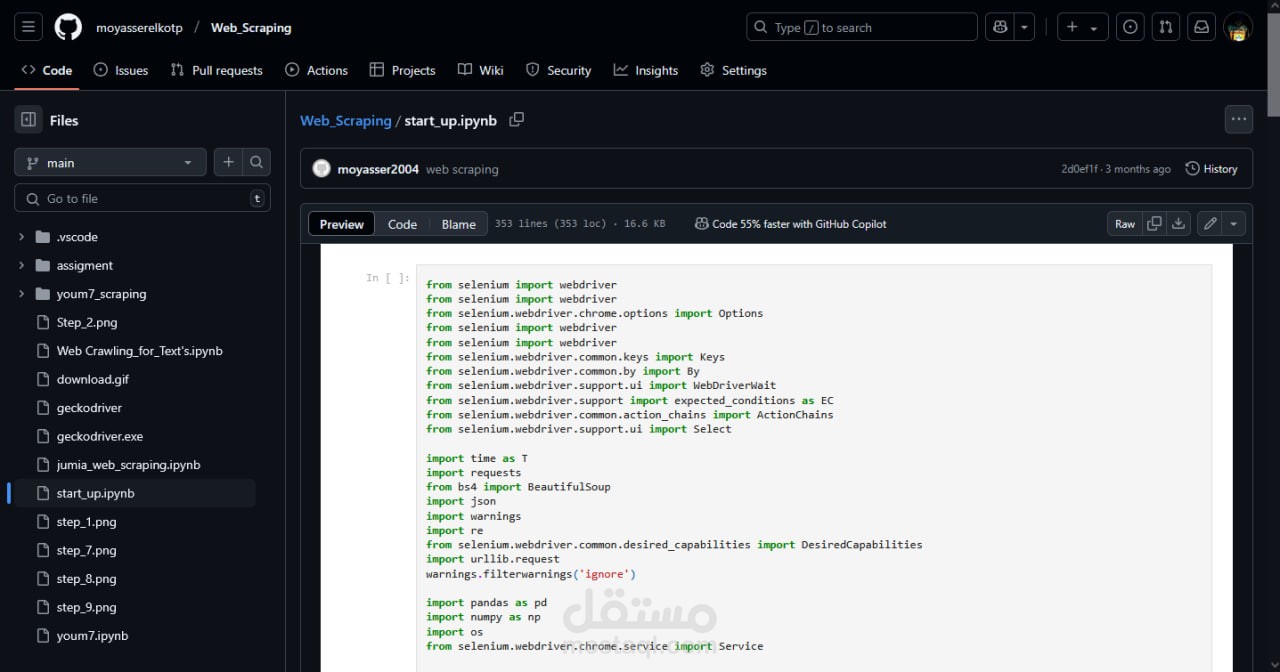
Selenium – لمحاكاة تصفح الموقع وتحميل الصفحات الديناميكية.
BeautifulSoup – لتحليل HTML واستخراج البيانات بسهولة.
webdriver_manager – لإدارة WebDriver تلقائيًا بدون تنزيل يدوي.
Requests – لجلب الصفحات الثابتة من الموقع.
2. معالجة وتحليل البيانات
Pandas – لتنظيف البيانات وتحليلها.
NumPy – للعمليات الحسابية والإحصائية.
Matplotlib و Seaborn – لإنشاء تصورات بيانية.
3. تخزين البيانات
CSV / JSON – لتخزين البيانات بشكل محمول.
MongoDB / MySQL – لحفظ البيانات الضخمة بطريقة منظمة.