Document Classification
تفاصيل العمل

يحتوي هذا المستودع على خط أنابيب لأداء تصنيف النص باستخدام نموذج قائم على Transformer، مدعوم بمكتبة المحولات الخاصة بـ Hugging Face وPyTorch.
يتضمن خط الأنابيب:
- معالجة مسبقة للبيانات
- إعداد مجموعة البيانات
- تدريب النموذج والتقييم
- أدوات التصور
- حفظ البيانات في MongoDB
- نظرة عامة على النماذج
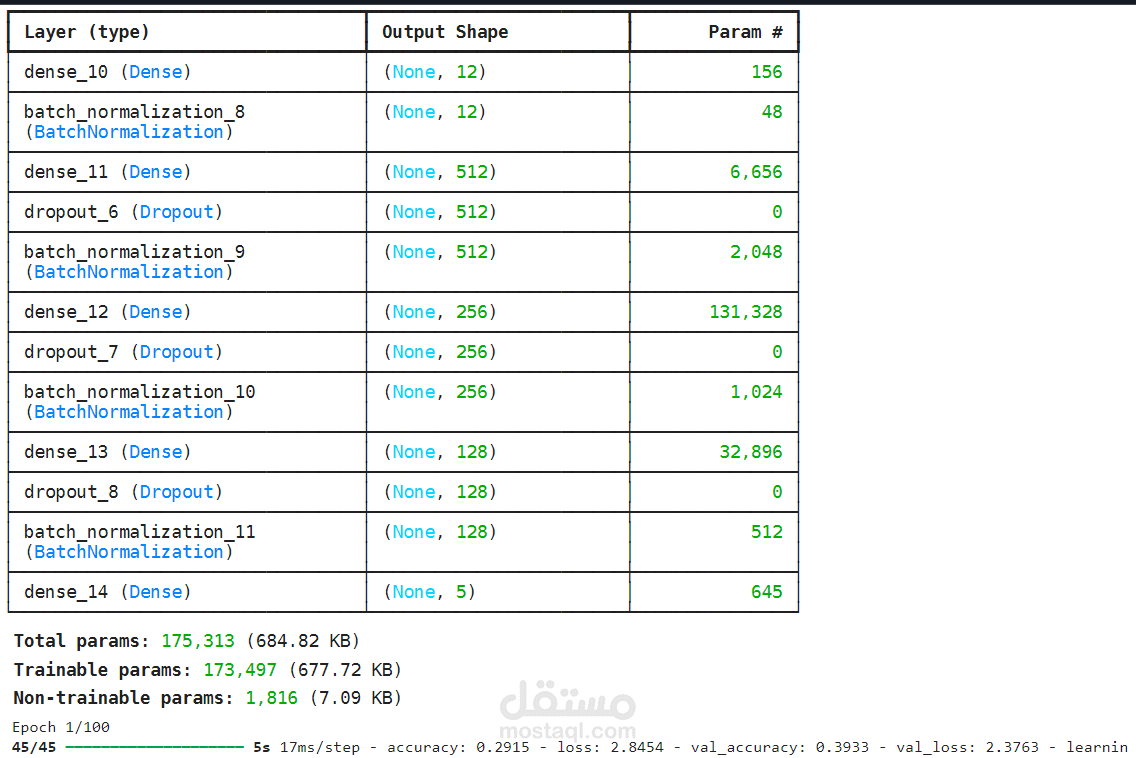
نموذج FCNN
شبكة عصبية تلافيفية تغذية أمامية (FCNN) تتكون من طبقات متصلة بالكامل (Dense Layers). يركز النموذج على تعلم التمثيلات المعقدة دون استخدام العمليات التلافيفية أو التجميع.
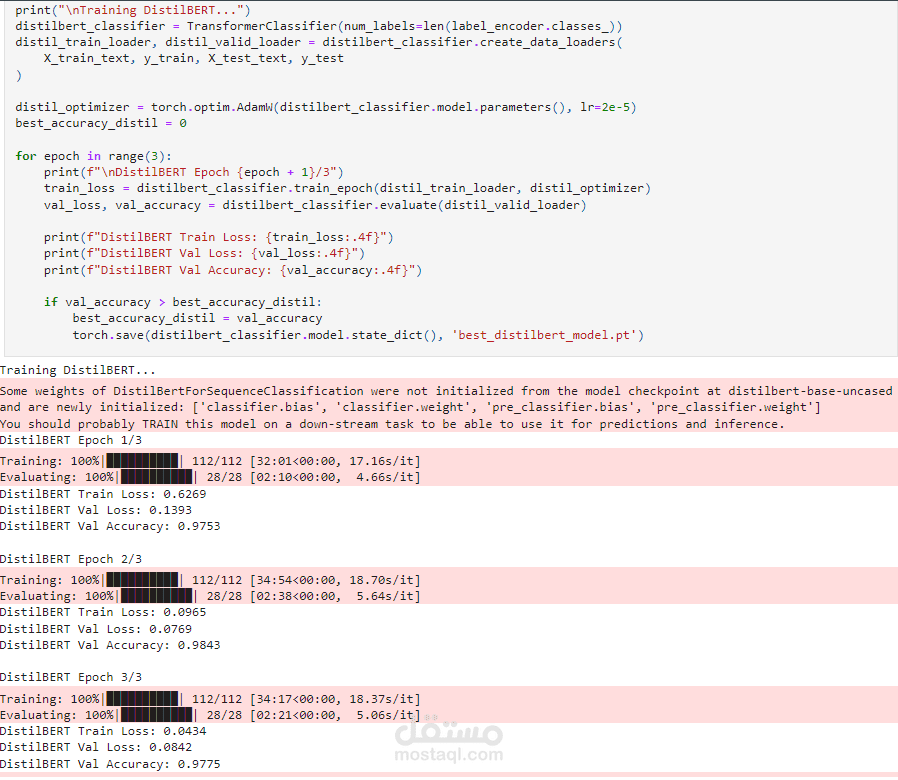
نموذج DistilBERT
DistilBERT هو إصدار أصغر وأكثر كفاءة من BERT، حيث:
يستخدم بنية المحول مع آليات الانتباه الذاتي.
يقلل حجم النموذج بنسبة 50% مع الاحتفاظ بـ 97% من قدراته.
محسّن للسرعة وكفاءة الذاكرة.
نموذج RoBERTa
RoBERTa هو إصدار محسن من BERT، يتميز بـ:
استخدام الإخفاء الديناميكي وزيادة حجم بيانات التدريب.
تحسينات في الدفعات الصغيرة وعدد خطوات التدريب.
أداء أقوى في معالجة اللغة الطبيعية.
حفظ البيانات في MongoDB
يتم تخزين بيانات نتائج التدريب والتقييم في قاعدة بيانات MongoDB لتسهيل الاسترجاع والتحليل لاحقًا. يشمل ذلك:
حفظ بيانات الإدخال والنواتج لكل نموذج.
تخزين نتائج التقييم مثل الدقة (Accuracy) والمقاييس الأخرى.
إمكانية استرجاع البيانات بسهولة لتحليل الأداء ومقارنته بين النماذج.
يمكن استخدام مكتبة PyMongo أو MongoEngine للتعامل مع MongoDB بسلاسة داخل بيئة Python.
هذا المشروع يوفر حلاً متكاملاً لتصنيف النصوص باستخدام نماذج متقدمة مع إمكانية تخزين وتحليل النتائج بشكل فعال.