Data analysis for imdb top 2000 movies
تفاصيل العمل
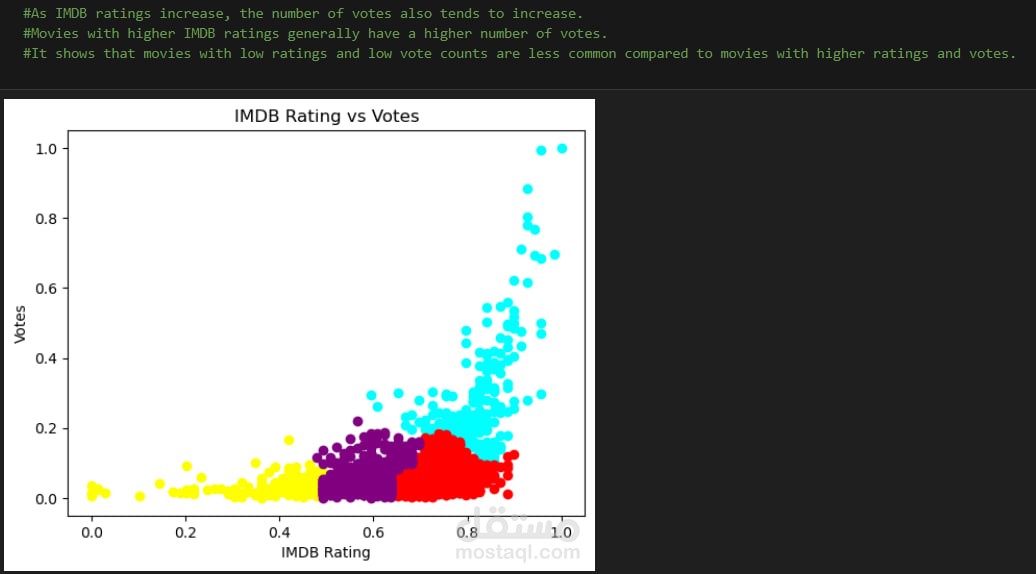
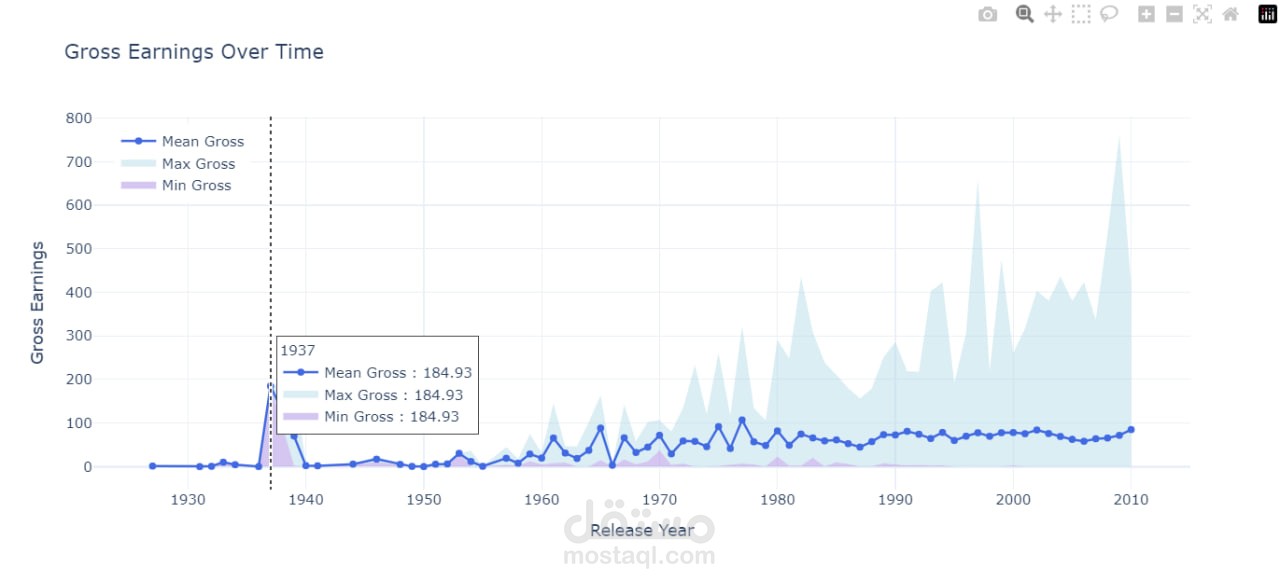
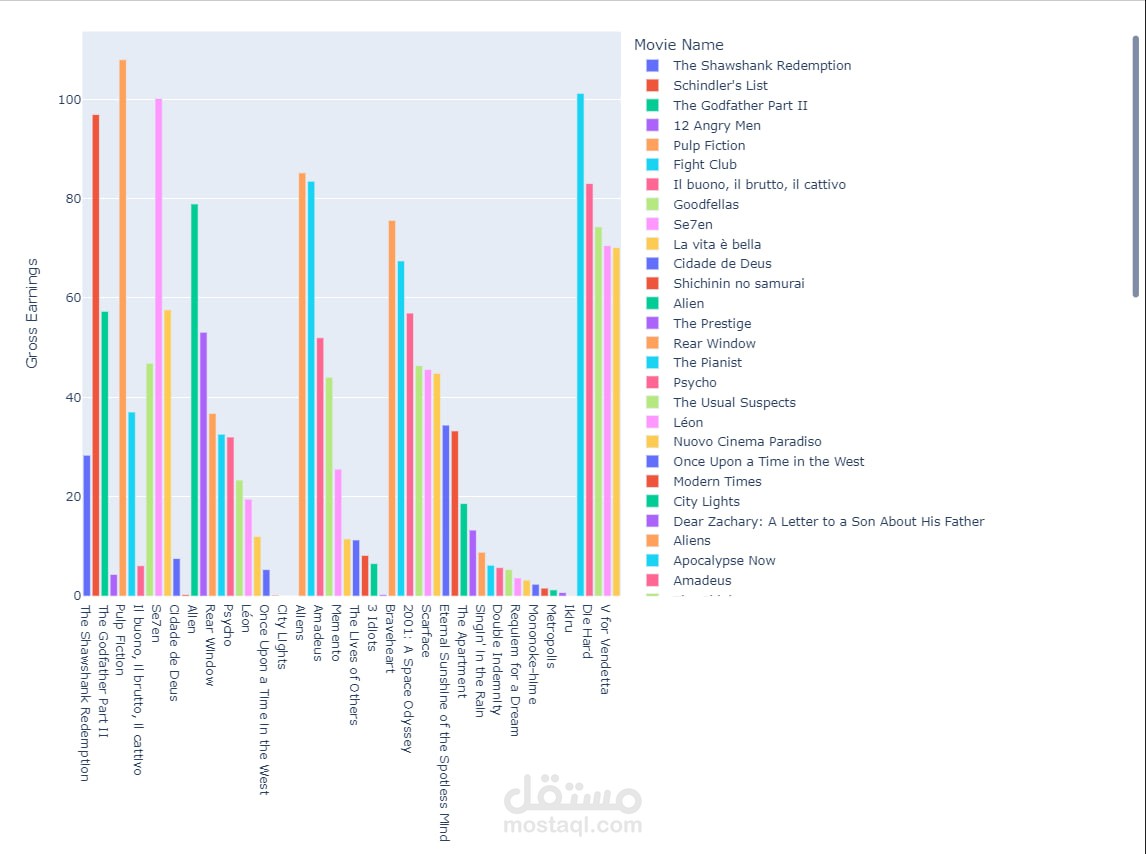
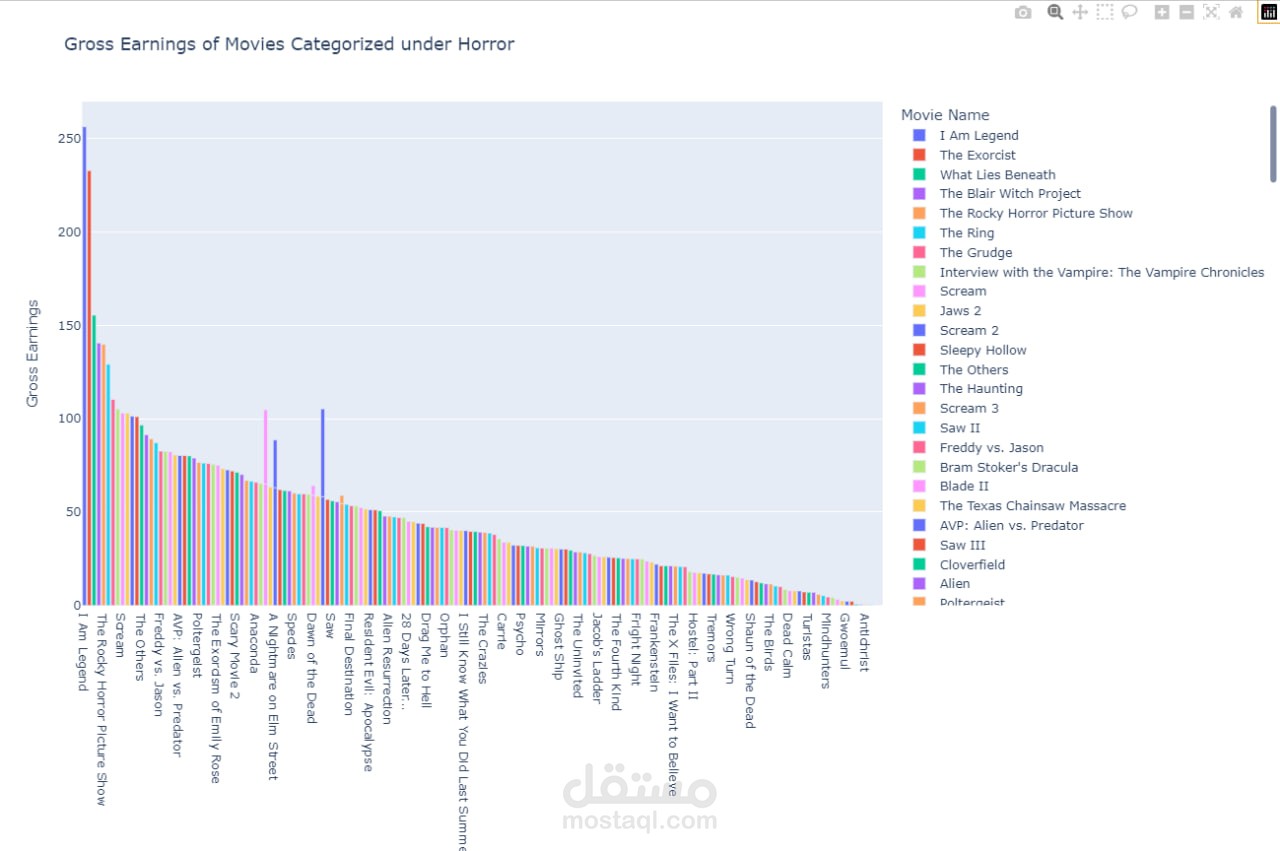
الهدف من المشروع:
يهدف المشروع إلى تحليل بيانات أفضل 2000 فيلم على منصة IMDB باستخدام بايثون، للكشف عن الأنماط والاتجاهات السينمائية من خلال تقنيات التحليل والاستكشاف.
ما الذي يتضمنه التحليل؟
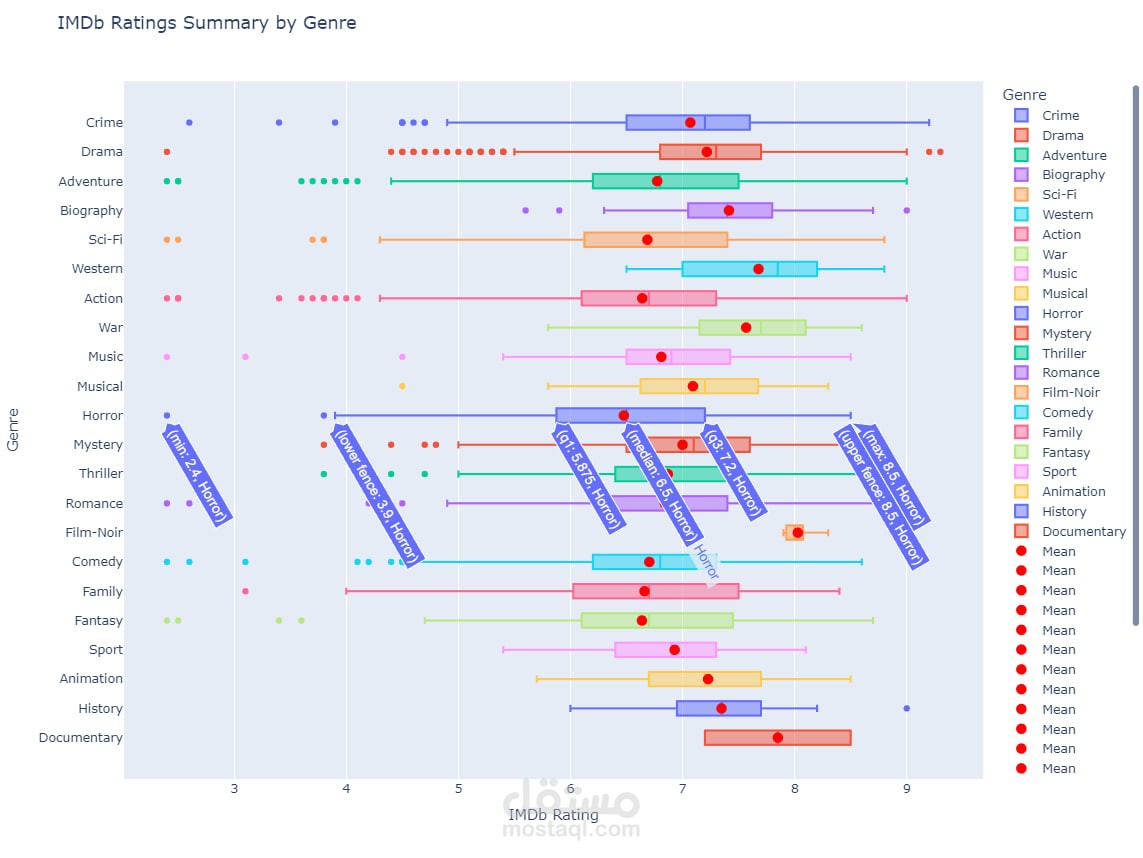
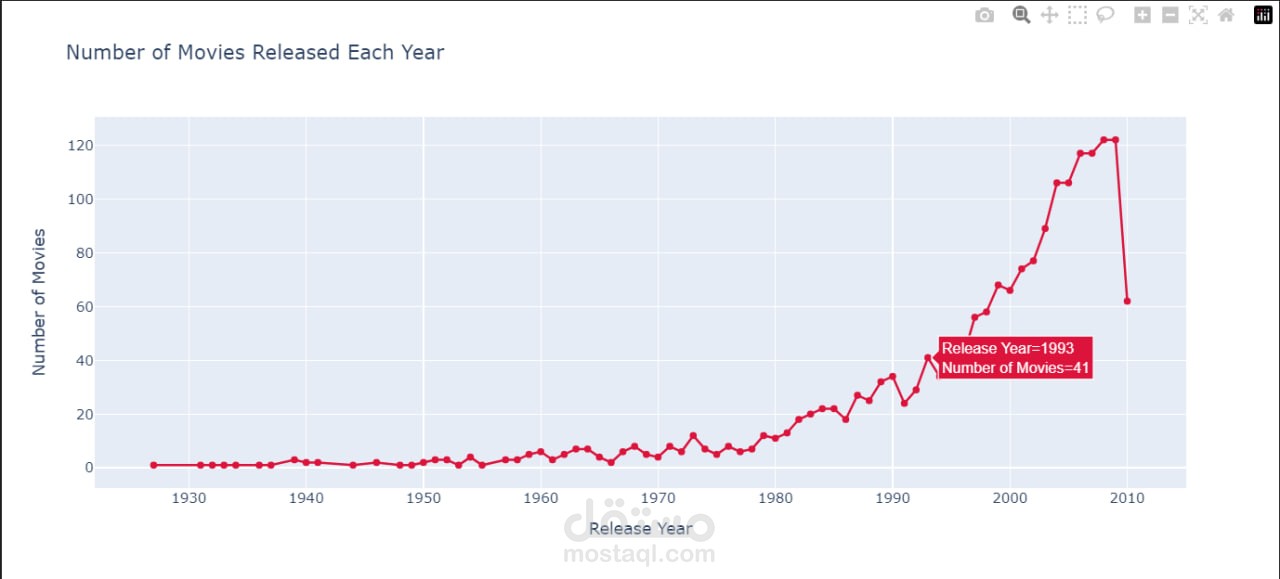
استكشاف البيانات وتحليلها
(Data Exploration, Descriptive Analysis, Pandas, NumPy)
تنظيف البيانات ومعالجتها
(Data Cleaning, Data Preprocessing, Missing Values Handling)
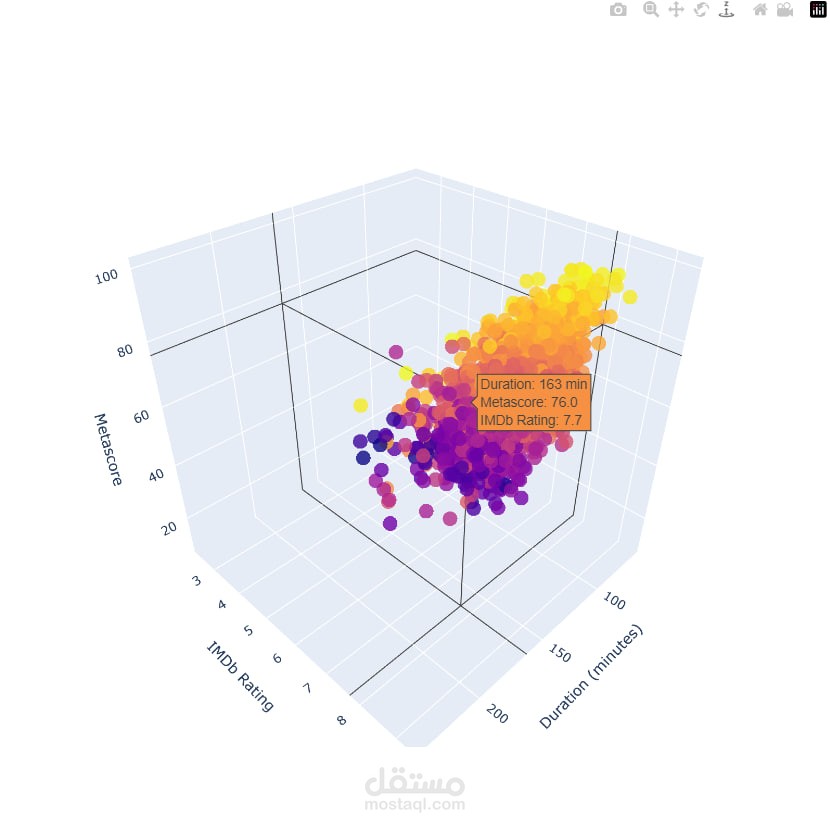
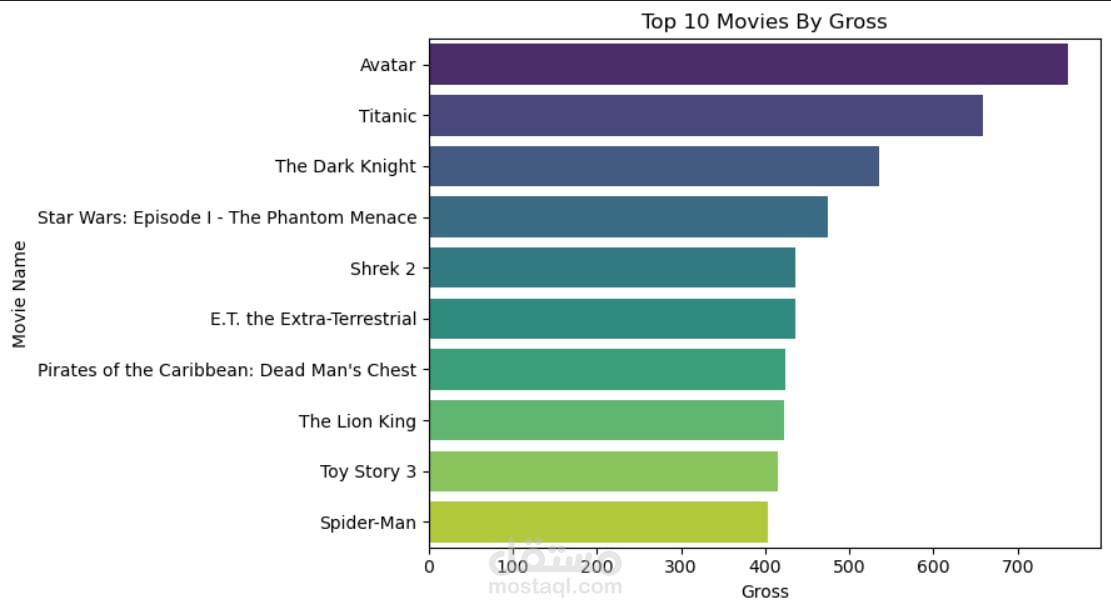
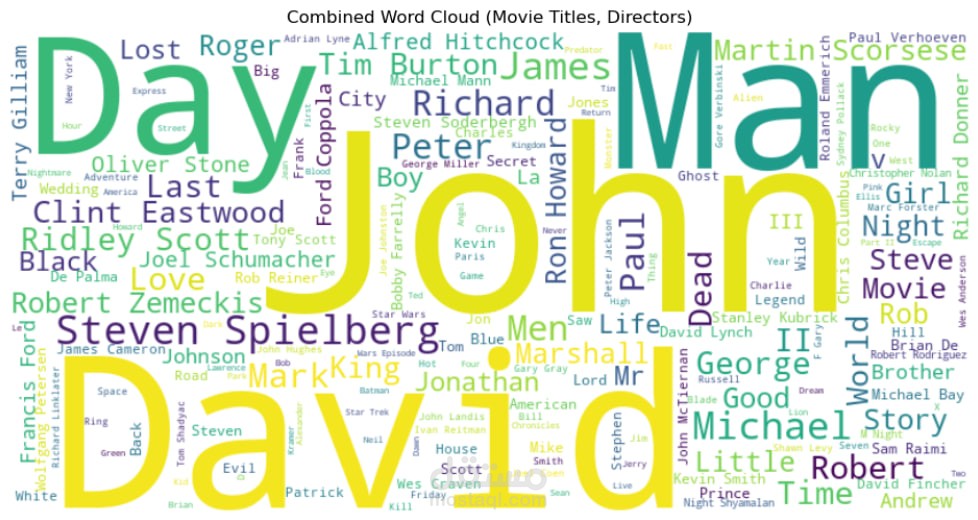
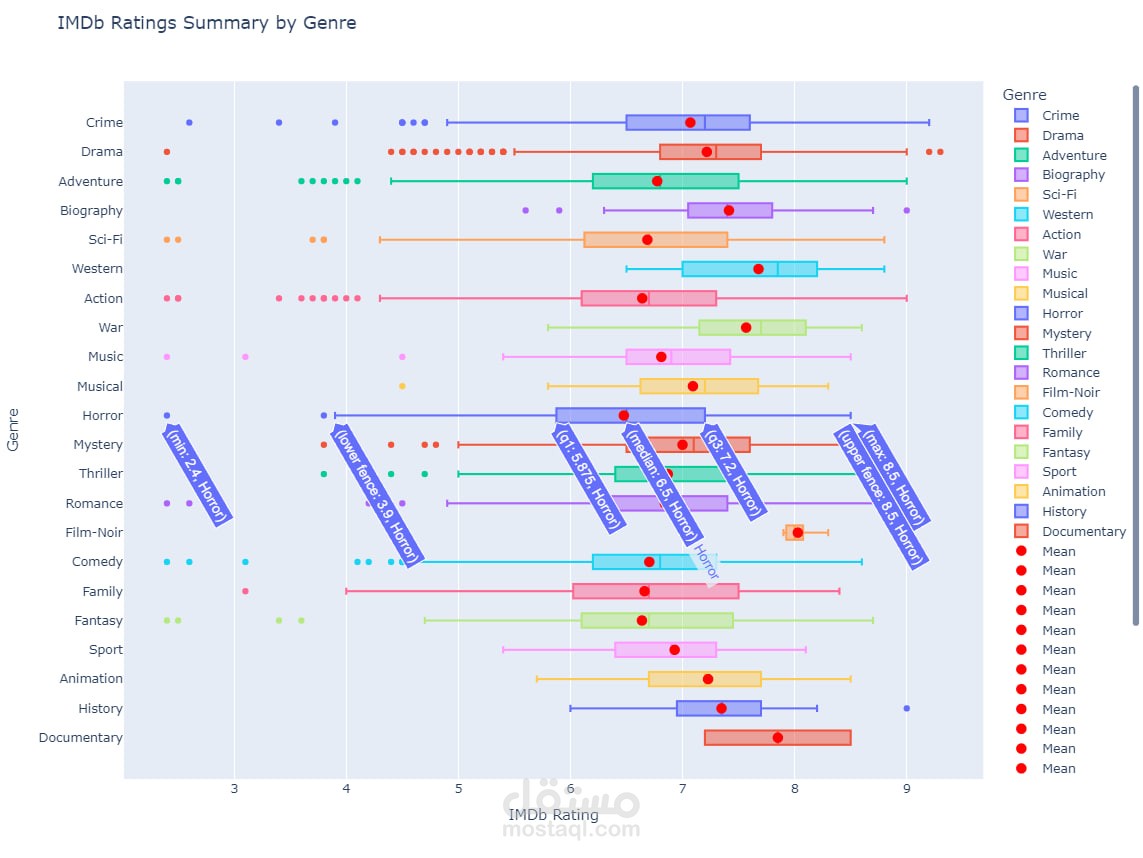
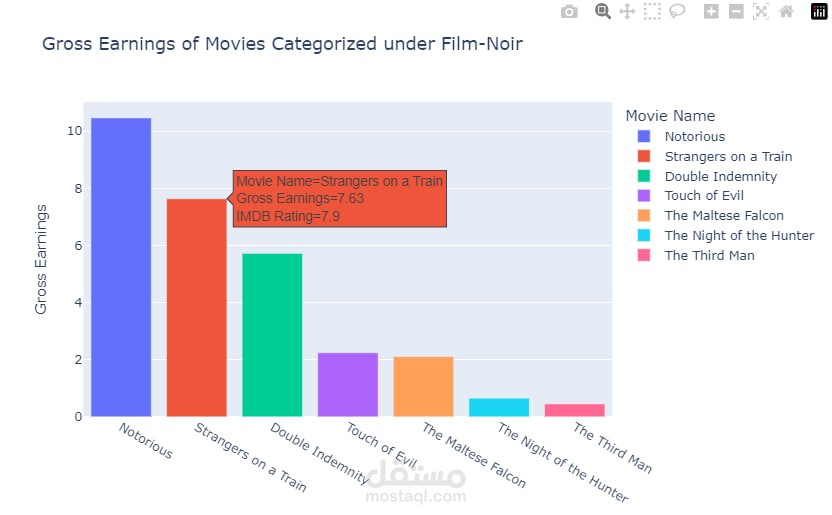
تصوير البيانات بشكل تفاعلي
(Matplotlib, Seaborn, Plotly, Interactive Visualizations)
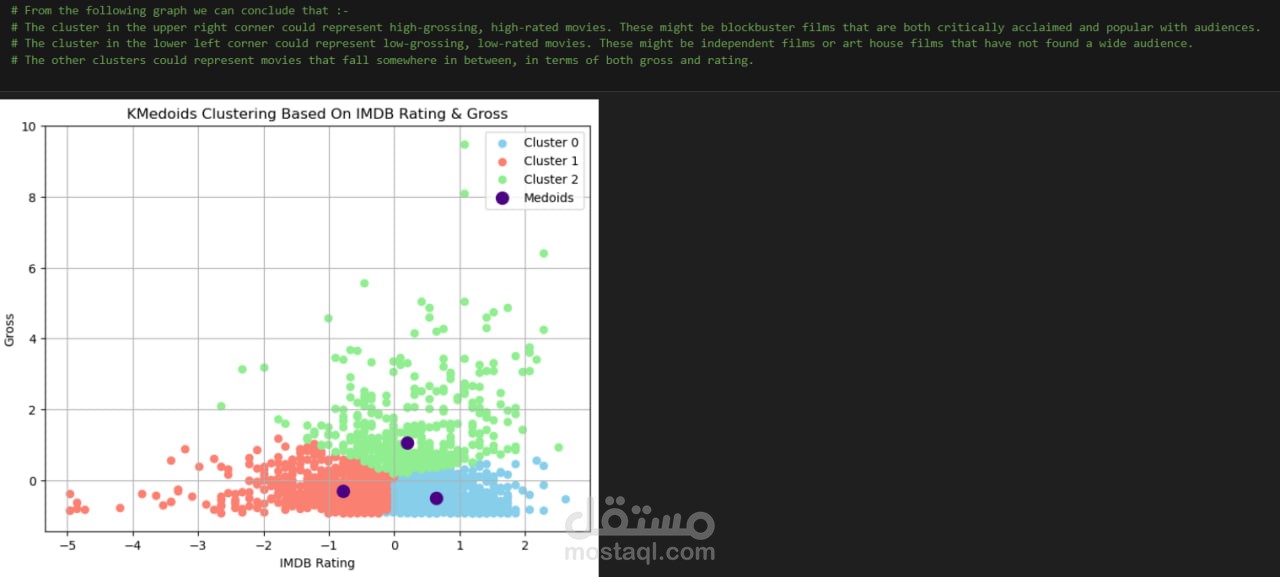
تنقيب البيانات واكتشاف الأنماط
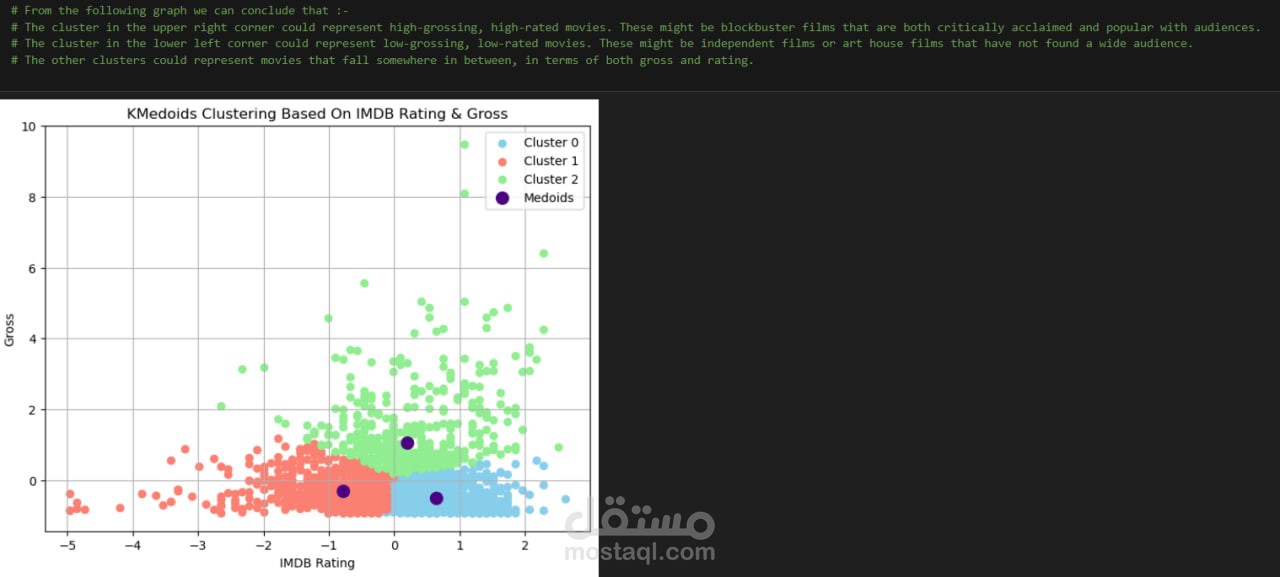
(Hierarchical Clustering, K-Medoids Clustering, Scikit-Learn)
آلية العمل:
استكشاف البيانات – تحليل السمات الأساسية وفهم هيكل البيانات.
التحليل الوصفي – تقديم إحصاءات وصفية لفهم توزيع البيانات واتجاهاتها.
تنظيف البيانات ومعالجتها – إزالة القيم المفقودة وتصحيح البيانات لضمان دقتها.
تصوير البيانات تفاعليًا – إنشاء رسوم بيانية ديناميكية تتيح استكشاف الأنماط بسهولة.
تنقيب البيانات وتقسيمها إلى مجموعات – استخدام خوارزميات التجميع مثل التجميع الهرمي (Hierarchical Clustering) وK-Medoids للكشف عن مجموعات الأفلام المتشابهة.
نتيجة المشروع:
يوفر هذا التحليل نظرة عميقة على خصائص وتصنيفات الأفلام في IMDB، مع تقديم رؤى بصرية تفاعلية تسهّل فهم الأنماط السينمائية وتفضيلات الجمهور.