E-Commerce Data Pipeline & Analysis
تفاصيل العمل
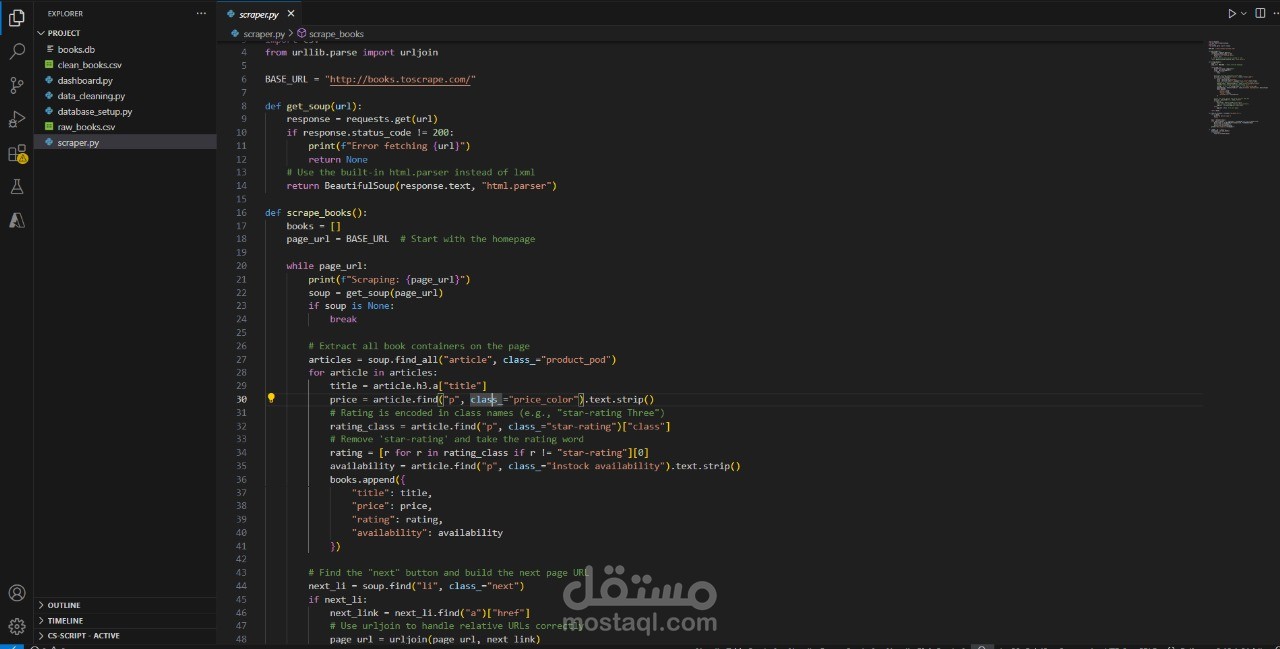
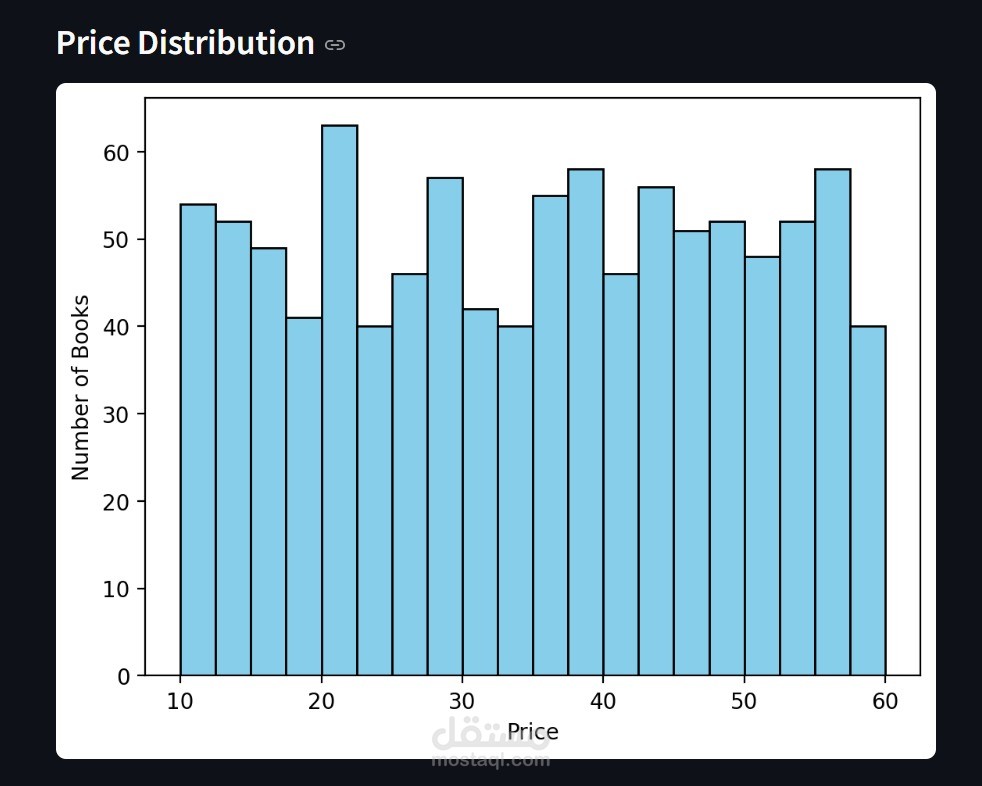
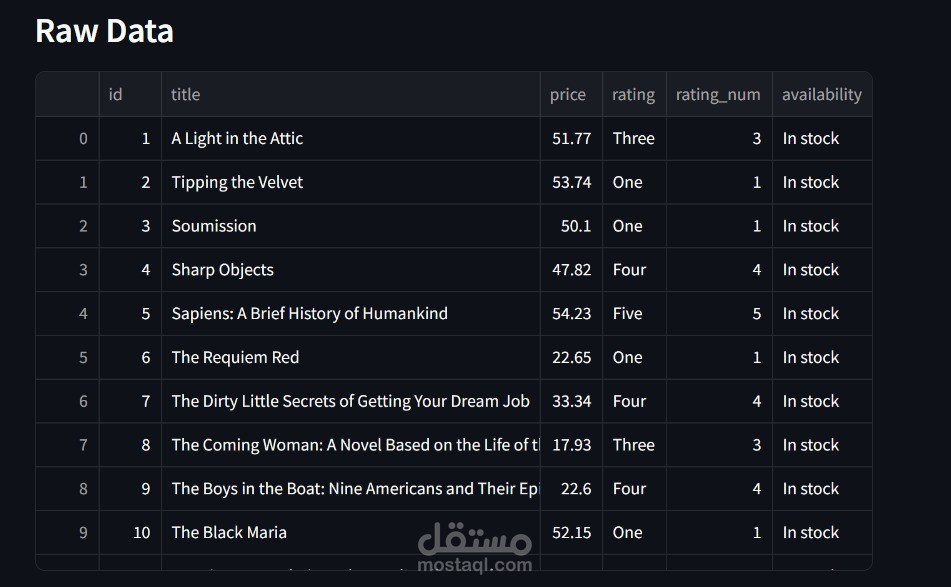
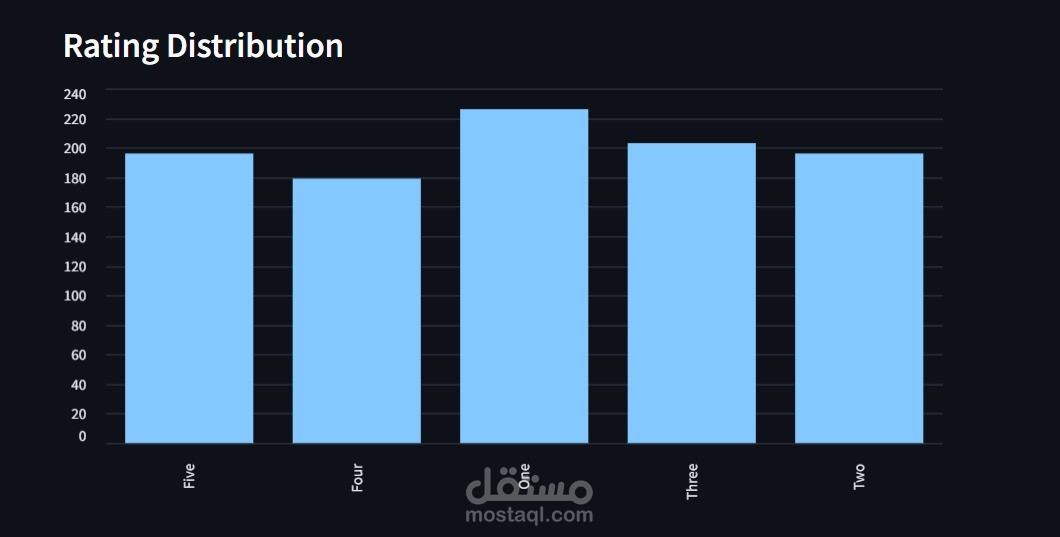
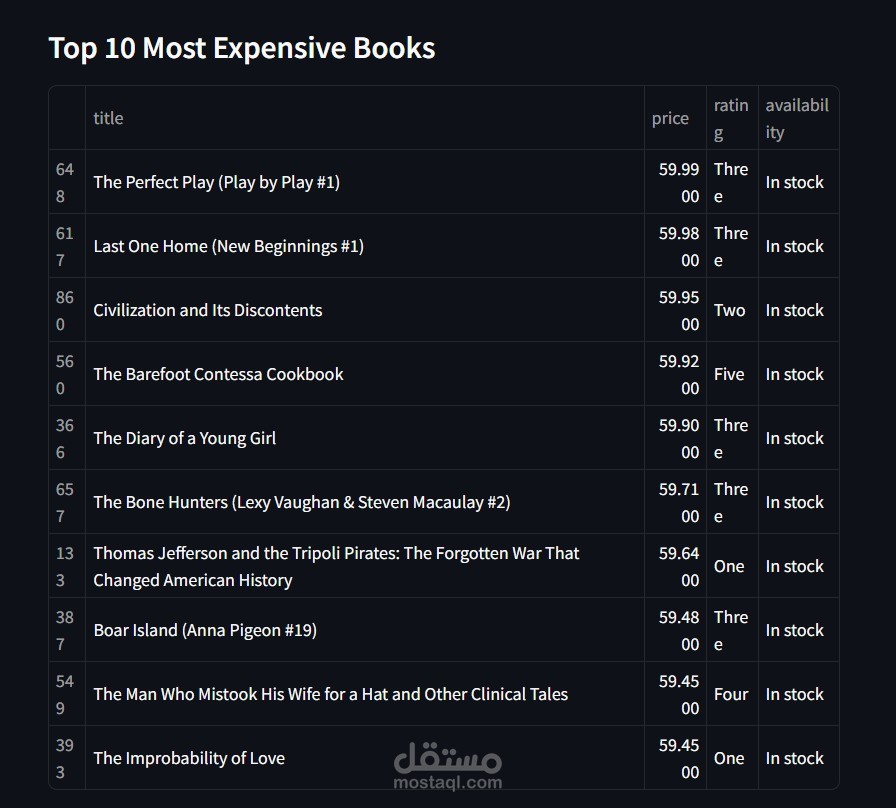
مشروع Data Pipeline متكامل: من الـ Scraping إلى الـ Visualization
يقدم هذا المشروع نموذجًا عمليًا لخطوات معالجة البيانات، بدءًا من استخراج البيانات وحتى عرضها في لوحة تحكم تفاعلية. يعتمد المشروع على بيانات الكتب من موقع Books to Scrape ويشمل المراحل التالية:
استخراج البيانات باستخدام Python و BeautifulSoup.
تنظيف البيانات ومعالجتها باستخدام Pandas.
تخزين البيانات في قاعدة SQLite باستخدام SQLAlchemy.
عرض البيانات من خلال واجهة تفاعلية باستخدام Streamlit.
هذا المشروع يعكس مهاراتي في تحليل البيانات، إدارة قواعد البيانات، وإنشاء واجهات بصرية تفاعلية، وهو مناسب كنموذج عملي لتطبيقات تحليل البيانات في التجارة الإلكترونية.