spotify analysis
تفاصيل العمل
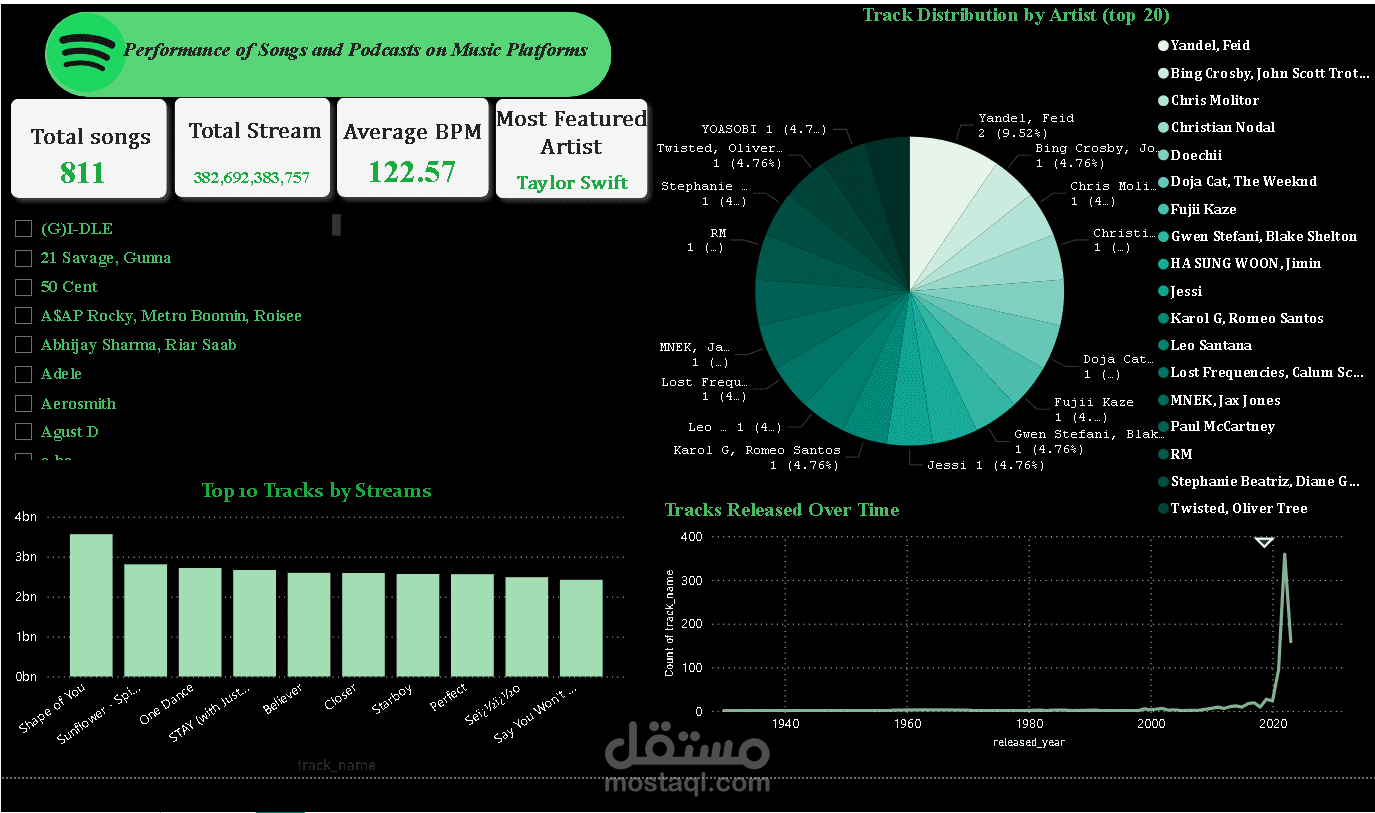
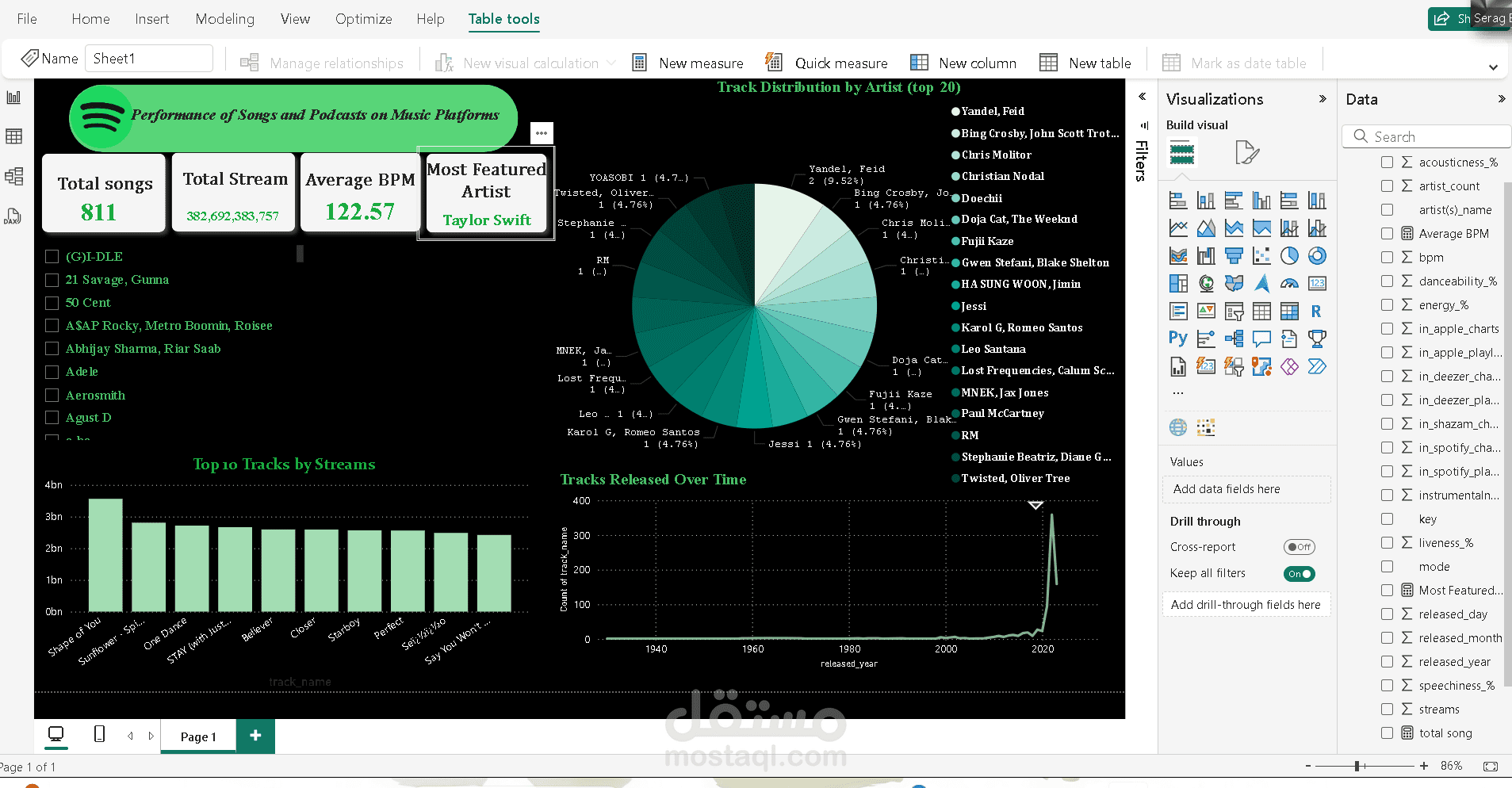
مشروع تحليل بيانات Spotify يهدف إلى فهم سلوك المستخدمين وتفضيلاتهم الموسيقية لتحسين تجربة المستخدم وتعزيز استراتيجية الأعمال. يتميز المشروع بالخطوات التالية:
1. جمع البيانات:
الحصول على البيانات من واجهات برمجة التطبيقات (APIs) مثل Spotify API.
استخدام مجموعات بيانات عامة تحتوي على تفاصيل المسارات الموسيقية، الفنانين، القوائم الموسيقية، وسلوك المستخدمين.
2. تنظيف البيانات:
إزالة القيم الفارغة أو غير المنطقية.
معالجة البيانات المكررة والتأكد من جودة البيانات.
3. تحليل البيانات الاستكشافي (EDA):
فهم التوزيع العام للمسارات الموسيقية من حيث الشعبية، النوع الموسيقي، والمزاج.
تحليل سلوك المستخدمين من حيث التكرار الزمني للاستماع، تفضيل الأنواع، والأنشطة الموسيقية المختلفة.
4. تطبيق خوارزميات التوصية:
تصفية المستخدمين (User-based Filtering): اقتراح مسارات موسيقية بناءً على سلوك مستخدمين مشابهين.
تصفية المحتوى (Content-based Filtering): اقتراح مسارات موسيقية بناءً على خصائص المسارات المفضلة.
التصفية التعاونية (Collaborative Filtering): الجمع بين الطريقتين السابقتين لتقديم توصيات أكثر دقة.
5. تحليل المشاعر (Sentiment Analysis):
تحليل كلمات الأغاني لتحديد المزاج العام للمسارات الموسيقية.
استخدام مكتبات مثل NLTK وTextBlob لتحليل النصوص.
6. تصور البيانات:
استخدام Power BI أو Tableau لإنشاء لوحات تحكم تفاعلية تعرض النتائج والتوصيات.
رسم المخططات البيانية لتحليل التوزيعات والاتجاهات الموسيقية.
7. تحليل الأداء:
تقييم خوارزميات التوصية باستخدام مقاييس مثل Precision, Recall، وF1-Score.
تحسين النموذج بناءً على النتائج وتغذية النموذج ببيانات جديدة بشكل دوري.
8. نتائج وتوصيات:
تقديم توصيات لتحسين تجربة المستخدم من خلال تخصيص قوائم التشغيل واقتراح المسارات الموسيقية.
توفير رؤى تسويقية لاستهداف الجمهور بفعالية وتحقيق زيادة في الاشتراكات.
التقنيات المستخدمة:
Python (Pandas, NumPy, Scikit-Learn)
Power BI/Tableau للتصور
Spotify API لجمع البيانات
NLTK, TextBlob لتحليل النصوص
مشروع Spotify Data Analysis يعد مثالاً عمليًا على كيفية استخدام تحليل البيانات والتعلم الآلي لتحسين الخدمات الرقمية وتقديم تجربة مستخدم مخصصة.