news classification nlp
تفاصيل العمل

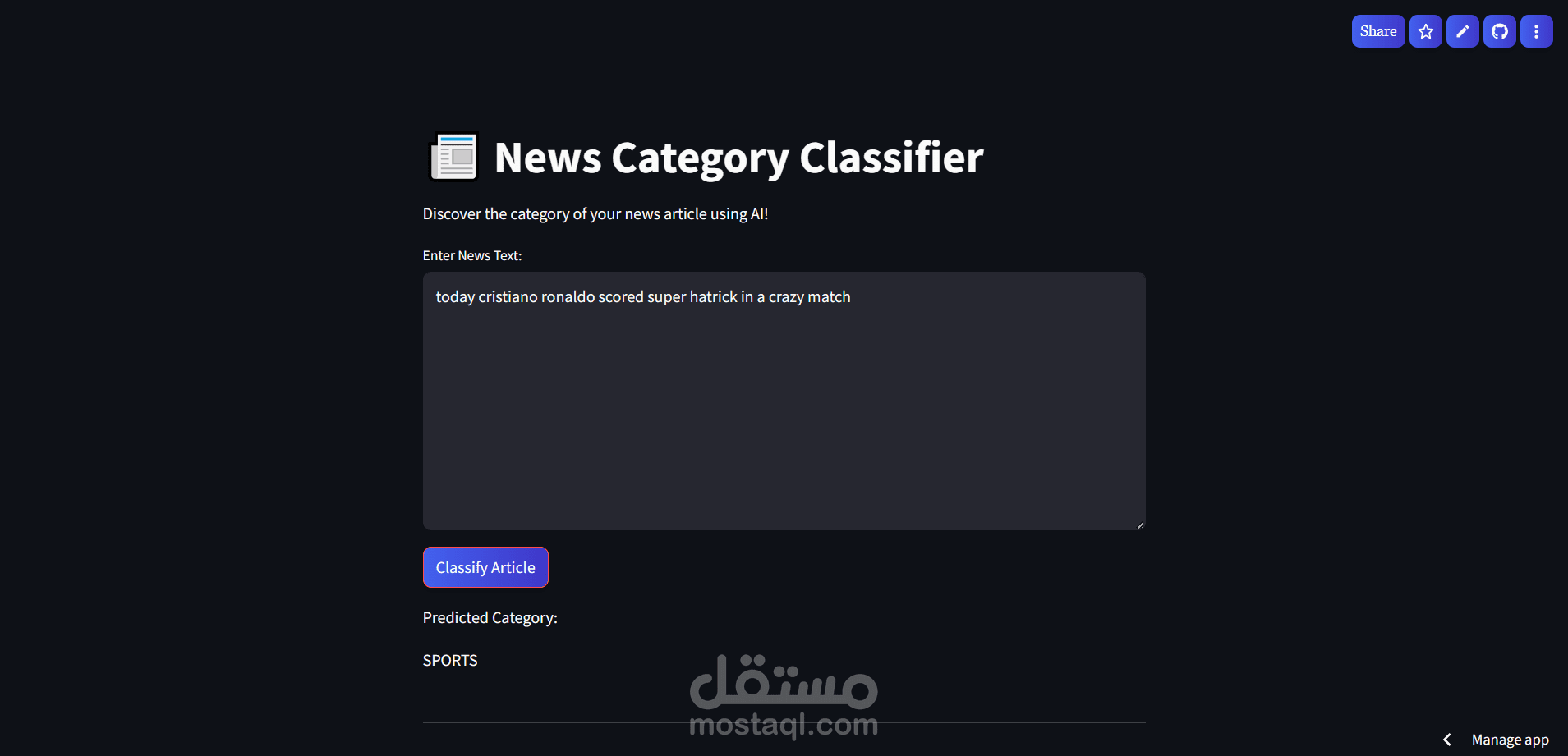

Overview
Built an NLP classifier that categorizes news articles into 31 distinct categories using logistic regression with CountVectorizer.
Data Processing
- Dataset: Sourced from Kaggle (news headlines with categories)
- Preprocessing Pipeline:
- Text cleaning (special characters, lowercase)
- Stopword removal (English)
- Lemmatization (WordNet)
- Label encoding (31 categories)
Model Architecture
- Vectorization: CountVectorizer (unigrams)
- Classifier: Logistic Regression
- L2 regularization (C=5.0)
- lbfgs solver
- 5000 max iterations
Performance
Achieved classification through:
- Stratified train-test split (80-20)
- Comprehensive text preprocessing
- Hyperparameter tuning
Deployment
Built a Streamlit web app featuring:
- Clean, responsive UI with custom CSS
- Real-time category prediction
- Error handling and loading states
- Category mapping system
Technical Stack
- Python (Pandas, NLTK, Scikit-learn)
- Streamlit for web interface
- Joblib for model persistence
The project demonstrates end-to-end NLP pipeline development from preprocessing to deployment.
This version is:
1. Professional and technical
2. Concise (easy to read on LinkedIn)
3. Highlights key achievements
4. Structured for readability
5. Focused on measurable outcomes