AI classification model analysis
تفاصيل العمل


**تصنيف زهور السوسن باستخدام خوارزمية KNN في تعلم الآلة**
يهدف هذا المشروع إلى تصنيف زهور السوسن إلى ثلاث فئات رئيسية باستخدام خوارزمية **أقرب الجيران (K-Nearest Neighbors - KNN)**، وهي إحدى خوارزميات **تعلم الآلة (Machine Learning)** الفعالة في التصنيف. يعتمد النموذج على **مجموعة بيانات Iris الشهيرة**، والتي تحتوي على **150 عينة** موزعة بالتساوي بين الفئات الثلاث:
- **Iris Setosa**
- **Iris Versicolor**
- **Iris Virginica**
### **تحليل البيانات ومعالجتها**
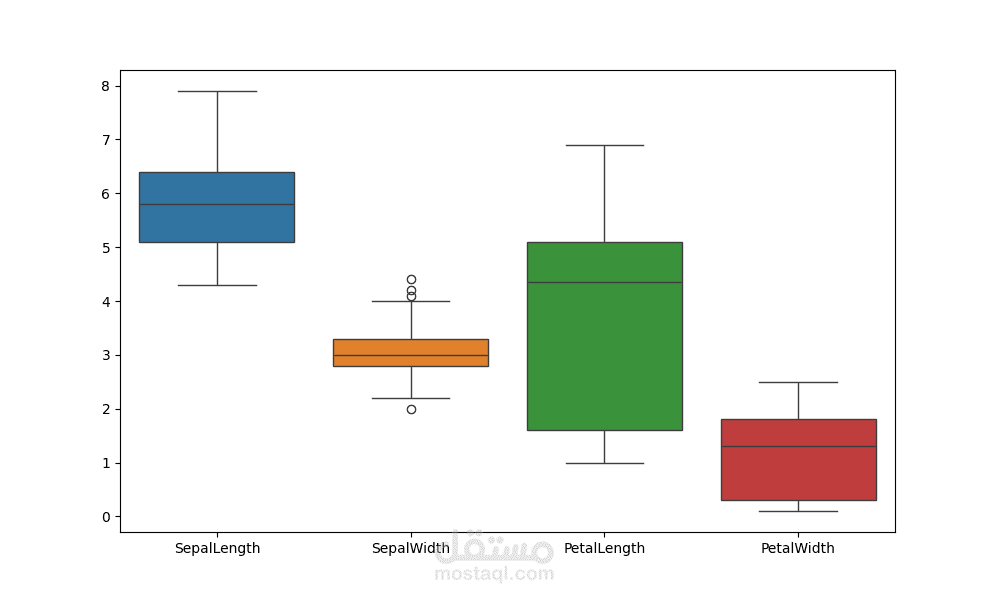
تمثل كل عينة زهرة في مجموعة البيانات بأربعة ميزات أساسية تُستخدم للتصنيف:
- طول الكأس
- عرض الكأس
- طول البتلة
- عرض البتلة
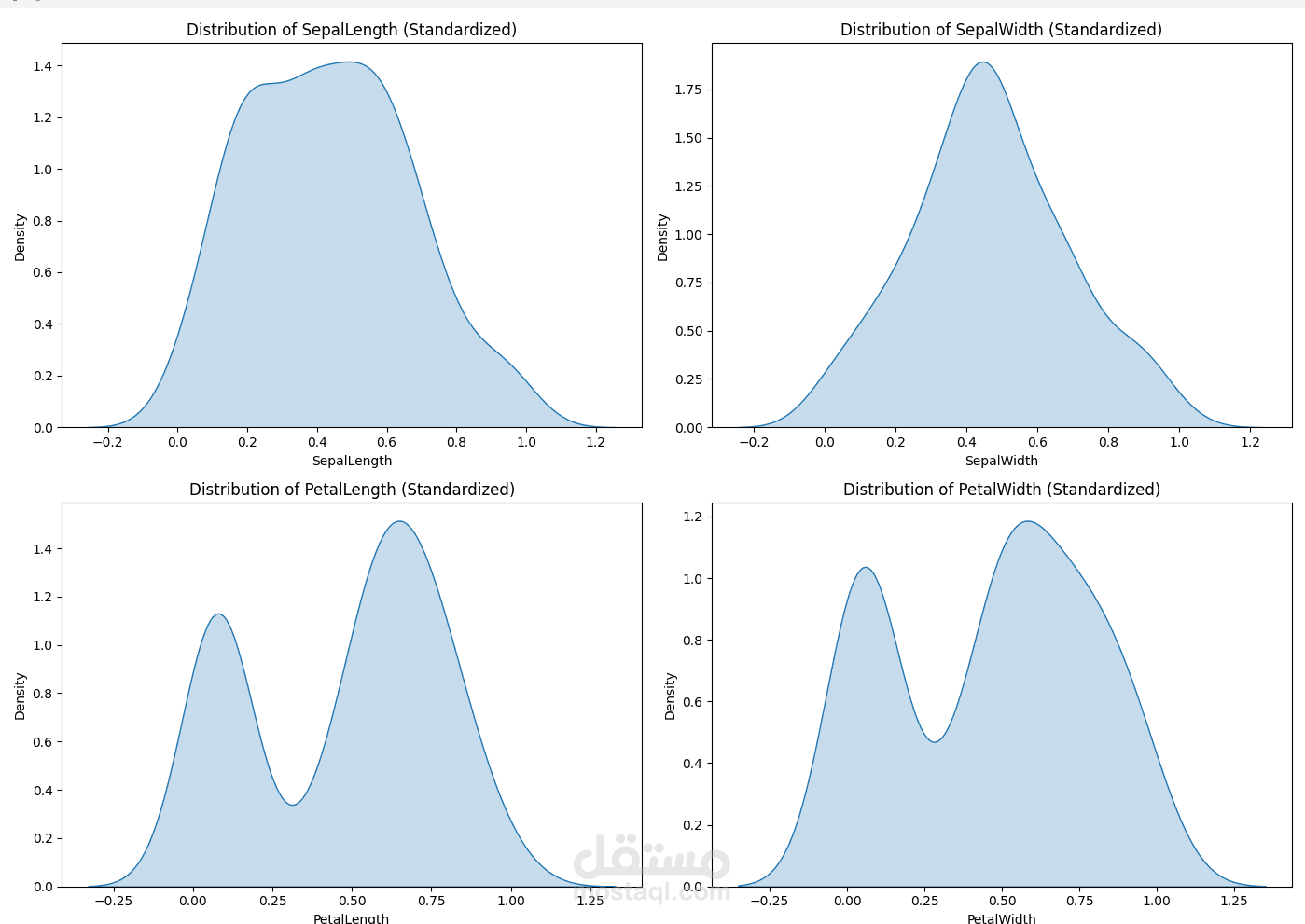
قبل تدريب النموذج، خضعت البيانات إلى **عملية تنظيف ومعالجة** لضمان تحقيق أعلى دقة ممكنة. شملت هذه العملية:
**اكتشاف القيم الشاذة ومعالجتها** لضمان أن البيانات لا تحتوي على عناصر قد تؤثر سلبًا على دقة النموذج.
**تطبيع القيم (Normalization)** لضبط نطاق القيم ومنع الميزات ذات القيم العالية من التأثير بشكل غير متناسب على حساب المسافات في الخوارزمية.
### **تدريب النموذج والتقييم**
تم تقسيم البيانات إلى **مجموعة تدريب واختبار** لضمان تقييم دقيق لقدرة النموذج على تعميم النتائج. تم استخدام **مسافة الإقليدس** كمعيار لحساب القرب بين العينات، مع اختيار عدد الجيران الأمثل (**قيمة K**) بناءً على **تحليل الأداء عبر التحقق المتقاطع (Cross Validation).**
بعد تدريب النموذج، تم تقييم أدائه باستخدام **مصفوفة الارتباك (Confusion Matrix)** ومقاييس أخرى مثل **الدقة (Accuracy) والاسترجاع (Recall) والتقييم العام (F1-Score)**، مما أظهر قدرة النموذج على تصنيف الزهور بشكل دقيق بناءً على التشابه بينها.
**القيمة العملية للمشروع**
يعكس هذا المشروع مهاراتي في **تحليل البيانات وتطبيق تقنيات تعلم الآلة** لإنشاء نموذج دقيق وفعال. كما يُظهر قدرتي على **معالجة البيانات، اختيار الميزات المهمة، وتحسين أداء النماذج** لتحقيق نتائج موثوقة. يمكن تطبيق هذه المهارات على مشاريع تصنيف بيانات أخرى، مما يجعلني خيارًا قويًا لتطوير حلول ذكية تعتمد على الذكاء الاصطناعي والتعلم الآلي.