نظام تصحيح الإملاء
تفاصيل العمل
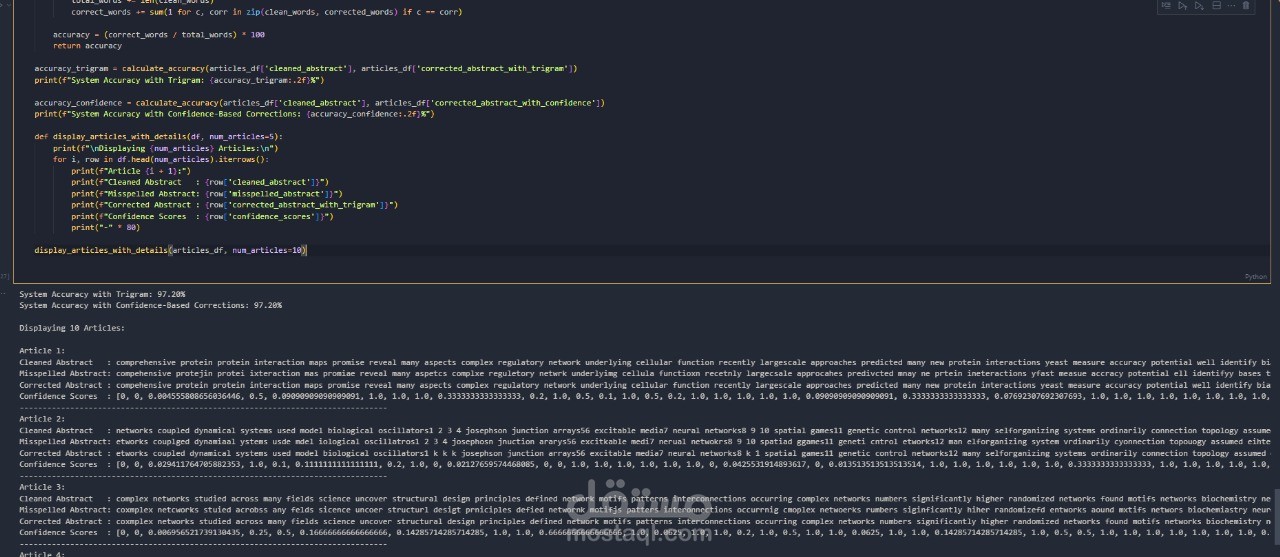
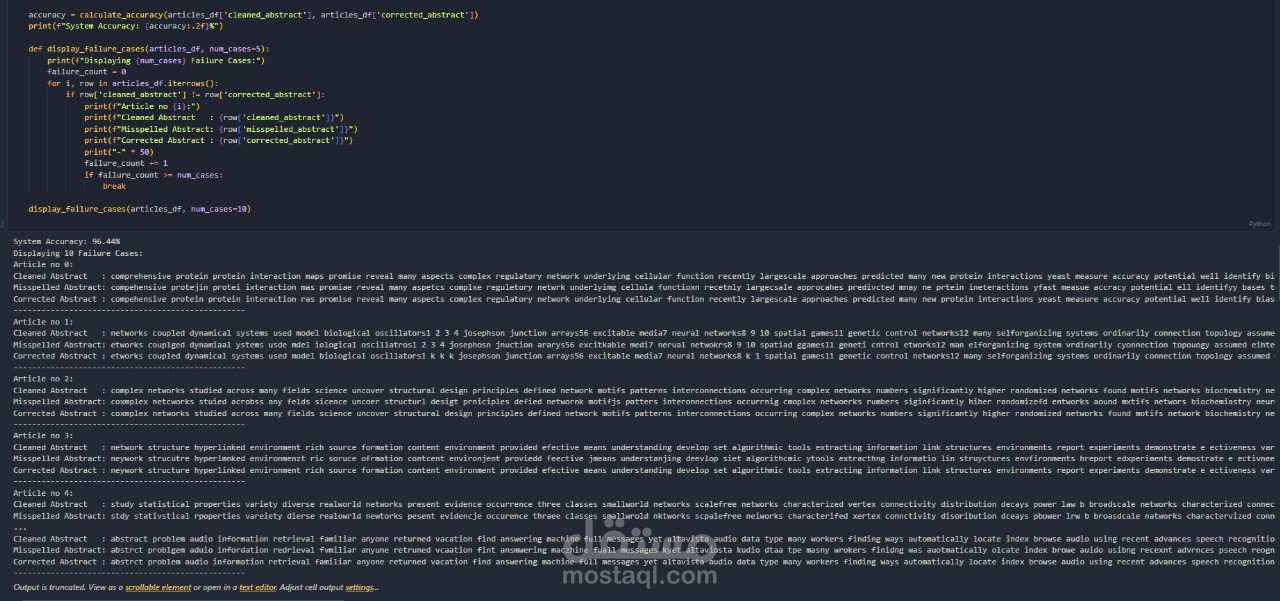
قمت بتصميم نظام مخصص لتصحيح الأخطاء الإملائية، يهدف إلى التعرف على الكلمات المكتوبة بشكل خاطئ وتصحيحها بدقة. تم استخدام ملخصات المقالات كبيانات تدريبية، مع تطبيق مجموعة متنوعة من الأخطاء الإملائية مثل الحذف، والإدراج، والتبديل، والاستبدال لمحاكاة الأخطاء الشائعة.
تم تنفيذ تقنيات معالجة النصوص المسبقة، بما في ذلك إزالة الكلمات الشائعة (Stopwords)، وتنظيف علامات الترقيم، وتقسيم النصوص إلى كلمات (Tokenization) لضمان دقة التصحيح.
كما تم تطوير نهج يعتمد على القواعد (Rule-based) لاكتشاف وتصحيح الأخطاء دون الحاجة إلى نماذج جاهزة أو وظائف تصحيح إملائي مدمجة.
تم تقييم أداء النظام من خلال قياس نسبة الدقة، مما يضمن فعالية التصحيح الإملائي ومدى تحسين جودة النصوص المعالجة.