تحليل المشاعر على تويتر باستخدام الشبكات العصبية ذات الذاكرة طويلة المدى (LSTM)
تفاصيل العمل
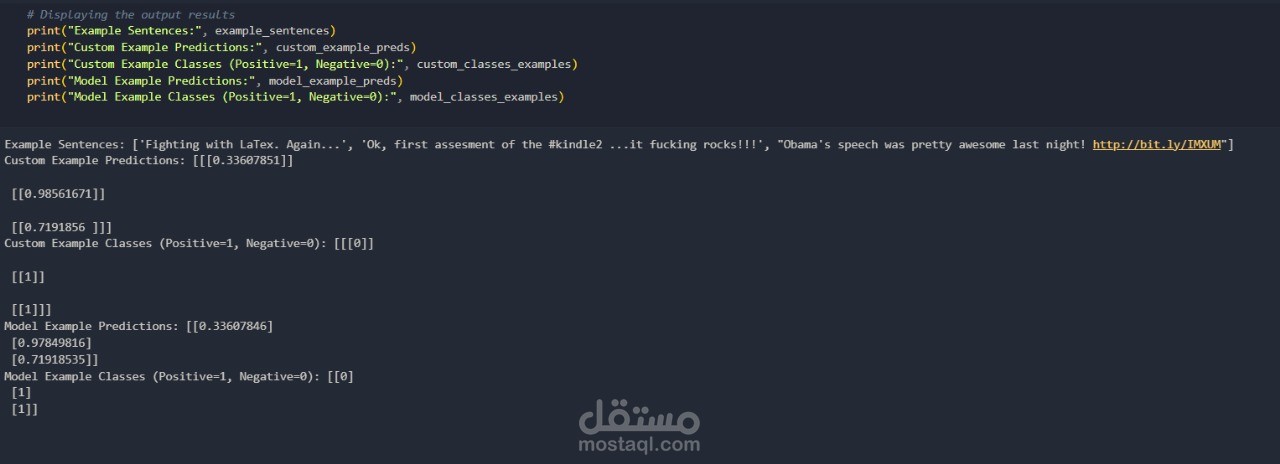
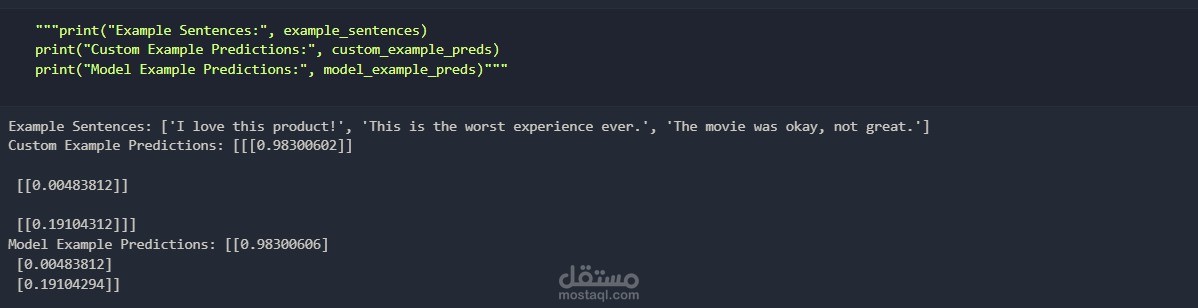
باستخدام تقنيات معالجة اللغة الطبيعية (NLP) والتعلم العميق، يهدف هذا المشروع إلى تصنيف مشاعر التغريدات على تويتر إلى إيجابية أو سلبية باستخدام مجموعة البيانات Sentiment140. تم استكشاف نموذجين يعتمدان على الشبكات العصبية ذات الذاكرة طويلة المدى (LSTM)، وهما:
تضمينات كلمات قابلة للتدريب (Trainable Embeddings).
تضمينات Word2Vec مُدرَّبة مسبقًا (Pre-trained Word2Vec).
أبرز المميزات:
تطوير نموذج تصنيف يعتمد على LSTM باستخدام بيانات Sentiment140.
تنفيذ تضمينات الكلمات القابلة للتدريب ودمج نماذج Word2Vec المُدرَّبة مسبقًا.
تصميم وظائف انتشار أمامي (Forward Propagation) مخصصة لتحسين التنبؤات.
تحقيق دقة تزيد عن 75% عبر تحسين النموذج وتقليل التكلفة.
تطبيق تقنيات NLP مثل: تنقية النصوص، إزالة الضوضاء، وتجزئة الكلمات (Tokenization).