iris flowers classification
تفاصيل العمل

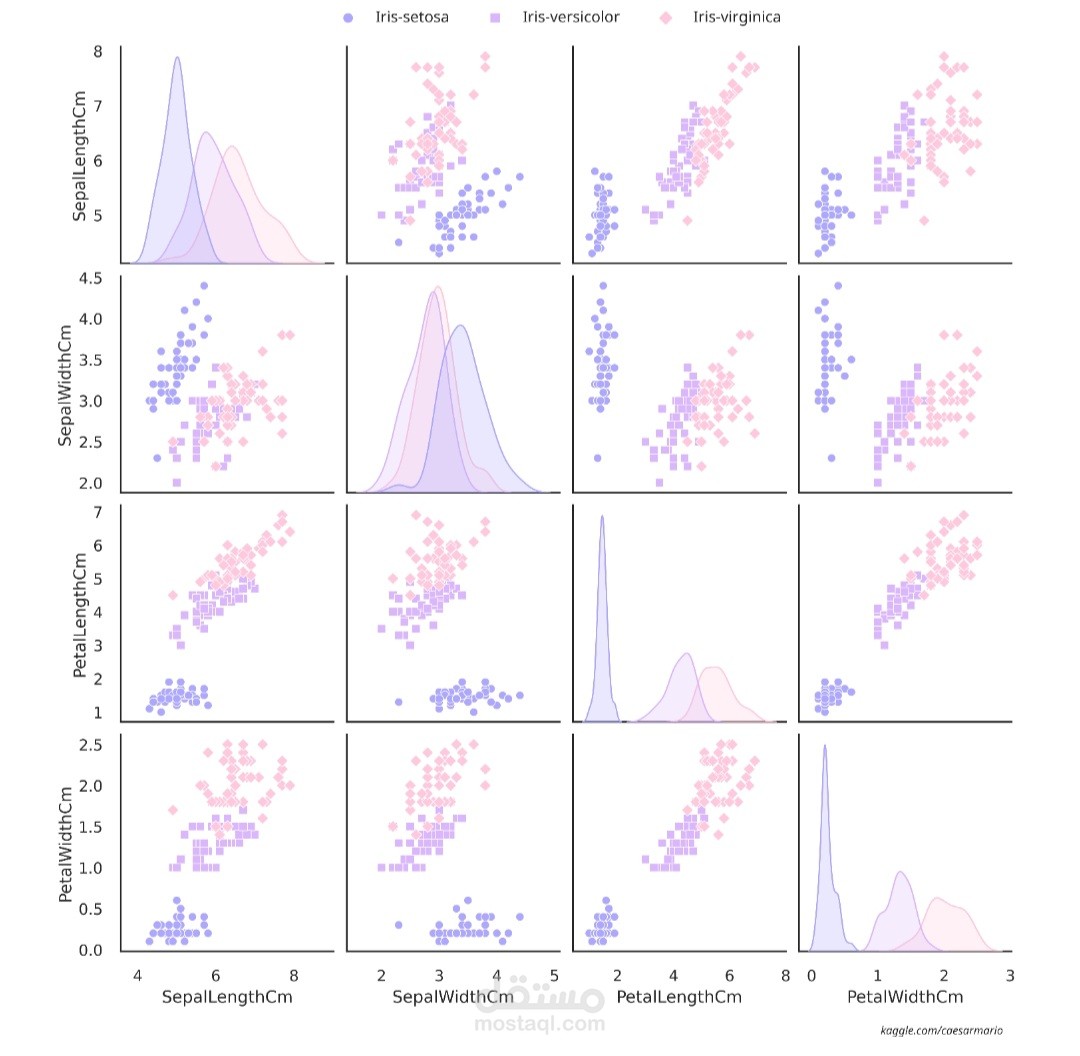
مشروع تصنيف أزهار إيريس هو أحد المشاريع الشهيرة في مجال تعلم الآلة (Machine Learning) والذي يهدف إلى تصنيف نوع الأزهار من نوع Iris باستخدام مجموعة من الخصائص الفيزيائية لها مثل طول و عرض الأوراق (sepal) و طول و عرض البتلات (petal). يتم استخدام خوارزميات التعلم الآلي مثل خوارزمية الجيران الأقرب (K-Nearest Neighbors)، الانحدار اللوجستي، و شجرة القرار لتدريب النموذج على هذه البيانات ثم تصنيف الأزهار إلى ثلاثة أنواع رئيسية: Iris-setosa، Iris-versicolor، و Iris-virginica.
الخطوات الرئيسية في المشروع:
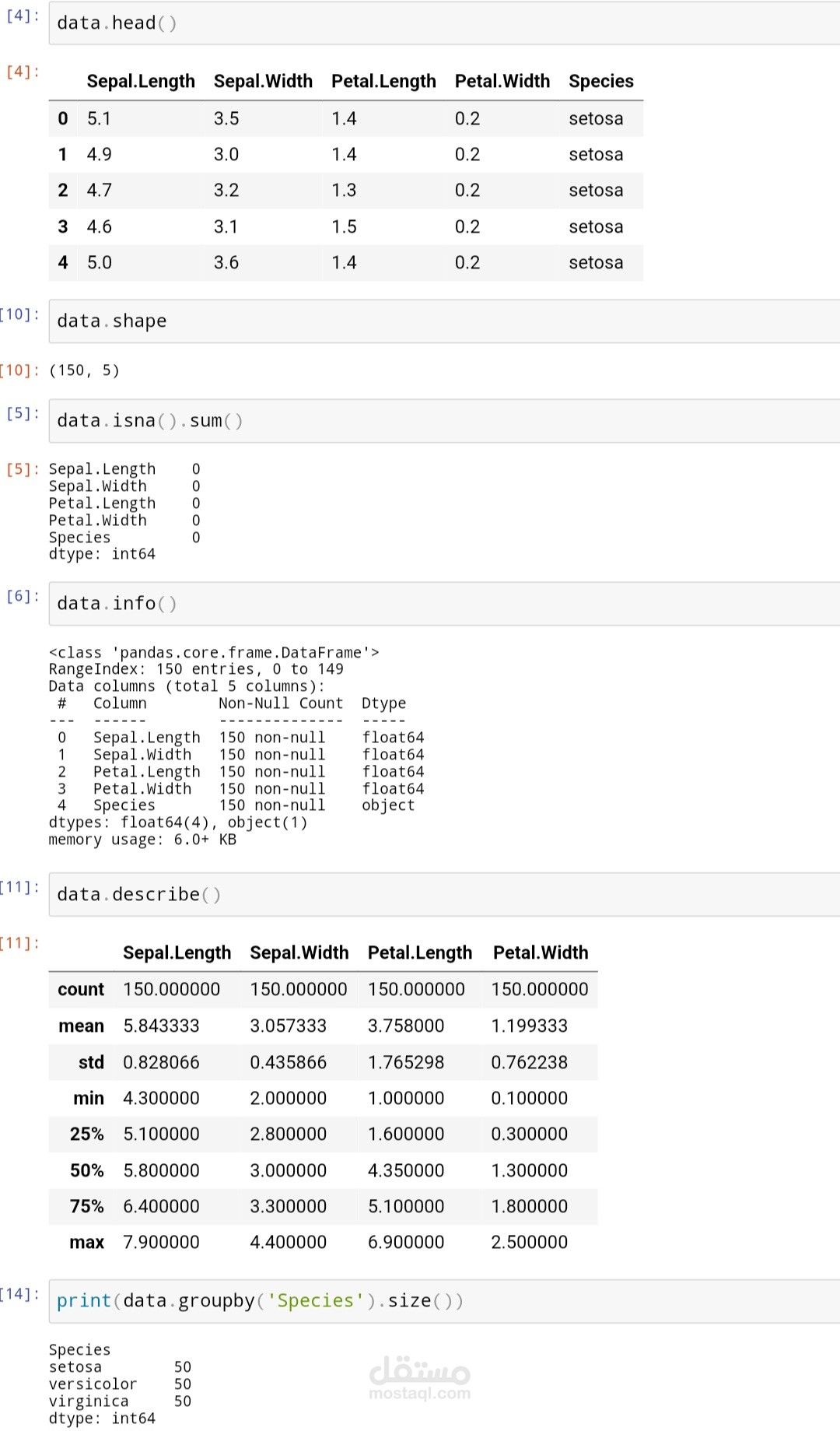
1. جمع البيانات: يتم استخدام مجموعة بيانات مشهورة تدعى Iris Dataset التي تحتوي على 150 سجل لزهور إيريس مع الخصائص المقاسة لكل نوع.
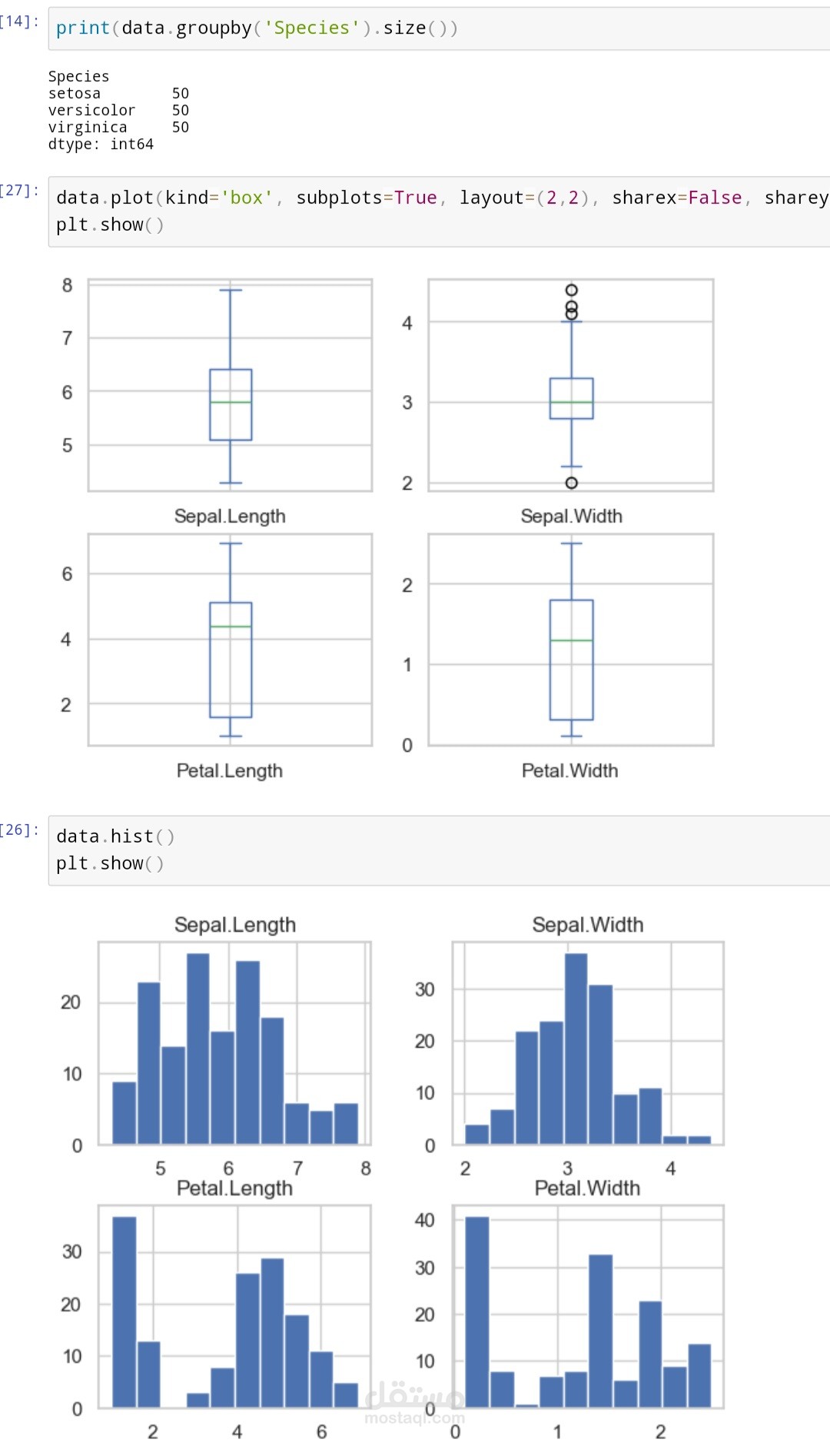
2. تحليل البيانات: يتم تحليل البيانات لفهم توزيع الأزهار عبر الأنواع المختلفة واكتشاف الأنماط والتشابهات بين الخصائص.
3. تنظيف البيانات: ضمان خلو البيانات من القيم المفقودة أو الشاذة وضبط البيانات لتكون جاهزة للاستخدام في التدريب.
4. بناء نموذج التعلم الآلي: يتم استخدام خوارزميات مثل KNN، دعم الآلات الشعاعية (SVM)، و شجرة القرار لبناء نموذج قادر على تصنيف الأزهار بناءً على الخصائص الفيزيائية.
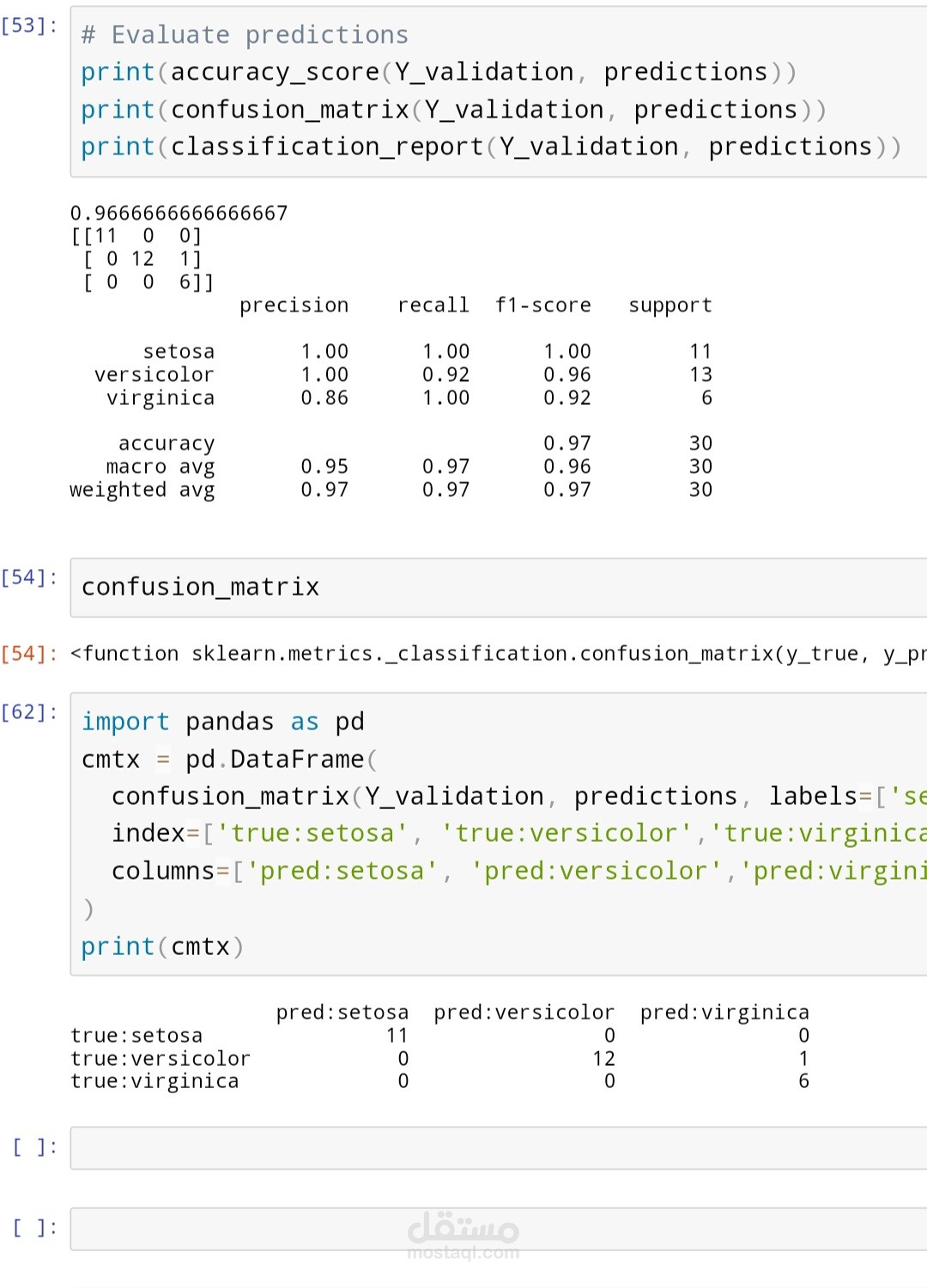
5. تقييم النموذج: يتم تقييم أداء النموذج باستخدام معايير مثل الدقة، الاسترجاع، و الـ F1-score لتحديد مدى فعاليته في تصنيف الأنواع المختلفة.
6. تحسين النموذج: يتم تحسين النموذج باستخدام تقنيات مثل التكرار المتقاطع (Cross-validation) و ضبط المعاملات للحصول على أفضل أداء.
الأدوات والتقنيات المستخدمة:
Python (مكتبات مثل Pandas، NumPy، Matplotlib)
Scikit-learn لتطبيق خوارزميات التعلم الآلي
Jupyter Notebook لتنفيذ التحليلات وعرض النتائج
الهدف من المشروع: تهدف هذه الدراسة إلى تطبيق تقنيات التعلم الآلي على بيانات حقيقية لتصنيف أنواع أزهار إيريس بشكل دقيق. يمكن توسيع هذا المشروع ليشمل تطبيقات أخرى في مجالات تصنيف النباتات أو الحيوانات بناءً على الخصائص الفيزيائية.