كشف إشارات المرور باستخدام الذكاء الاصطناعي
تفاصيل العمل

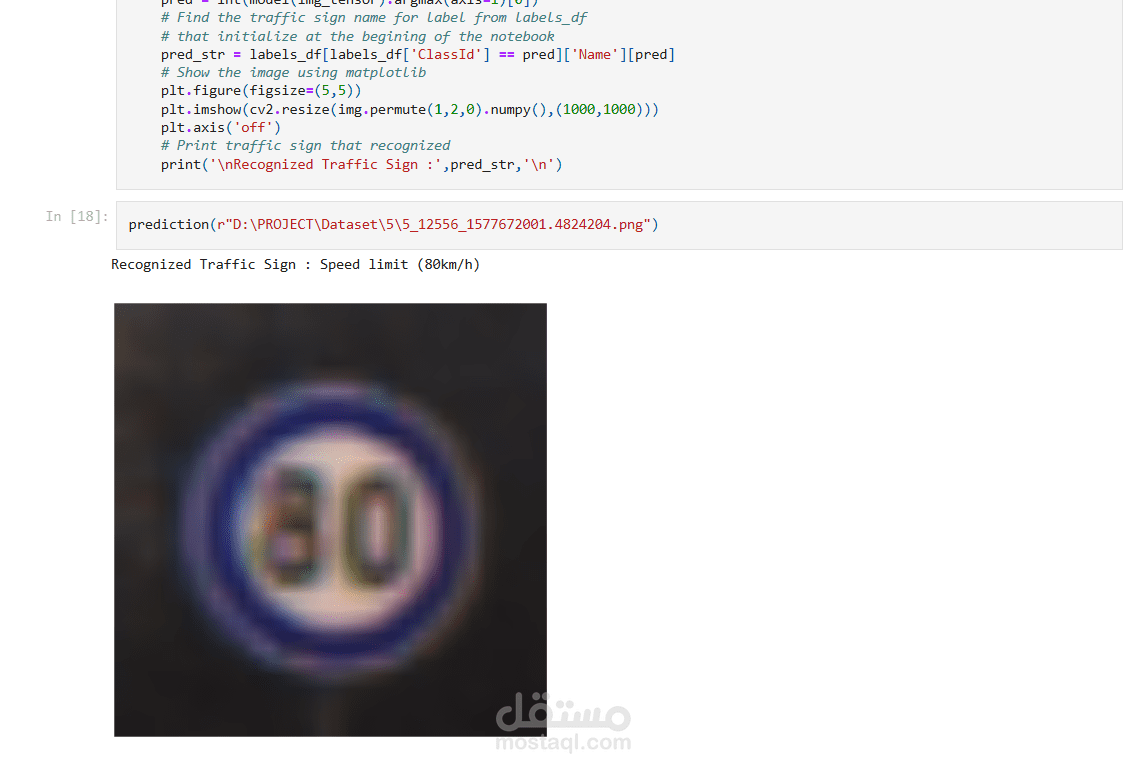
يهدف هذا المشروع إلى اكتشاف وتصنيف إشارات المرور في الصور باستخدام تقنيات الرؤية الحاسوبية (Computer Vision) والتعلم العميق (Deep Learning). يتم ذلك عبر تدريب نموذج ذكاء اصطناعي قادر على التعرف على أنواع إشارات المرور المختلفة، مما يجعله مفيدًا في أنظمة القيادة الذاتية، وتحليل الطرق، وتطبيقات السلامة المرورية.
معالجة البيانات وتحضيرها (Data Preprocessing)
استخدام مجموعة بيانات إشارات المرور، مثل GTSRB (German Traffic Sign Recognition Benchmark) أو أي مجموعة بيانات مخصصة.
تنظيف البيانات وتحسينها عبر تقنيات مثل تحجيم الصور، والتطبيع (Normalization)، وتوسيع البيانات (Data Augmentation).
تقسيم البيانات إلى مجموعة تدريب واختبار لضمان دقة النموذج.
بناء نموذج التعلم العميق (Deep Learning Model)
تطوير نموذج باستخدام شبكات CNN (Convolutional Neural Networks)، نظرًا لقدرتها الفائقة على التعامل مع الصور والتعرف على الأنماط.
التقنيات المستخدمة:
TensorFlow وKeras لإنشاء النموذج العميق.
طبقات CNN مثل Convolutional Layers وPooling Layers وFully Connected Layers لتحليل الصور بكفاءة.
استخدام Dropout وBatch Normalization لتحسين الأداء ومنع زيادة التعلم الزائد (Overfitting).
تدريب النموذج وتحسينه (Model Training & Optimization) :
استخدام تقنية Adam Optimizer لتسريع عملية التعلم.
تقليل معدل الخطأ (Loss Function مثل Categorical Crossentropy).
ضبط المعاملات (Hyperparameter Tuning) باستخدام Grid Search أو Random Search للحصول على أفضل النتائج.
تقييم النموذج وقياس الأداء (Model Evaluation & Performance Metrics)
قياس دقة النموذج باستخدام:
دقة التصنيف (Accuracy Score)
مصفوفة الارتباك (Confusion Matrix) لتحليل أخطاء التصنيف
رسم منحنى ROC-AUC لمعرفة مدى كفاءة النموذج في التمييز بين الفئات المختلفة.
نشر النموذج واستخدامه (Deployment & Real-Time Detection)
يمكن تحويل النموذج إلى تطبيق عملي باستخدام OpenCV لمعالجة الفيديوهات في الوقت الفعلي.
إمكانية دمج النموذج في أنظمة القيادة الذاتية أو تطبيقات الهاتف الذكي.