معالجة وتحليل البيانات (preprocessing )
تفاصيل العمل

لدي خبرة قوية في تنظيف البيانات ومعالجتها (Data Preprocessing)، بما يشمل التعامل مع البيانات المفقودة، حذف أو تصحيح القيم الشاذة، تحويل الأنواع، ترميز البيانات النصية، وتوحيد المقياس. أضمن تجهيز البيانات بشكل مثالي لجعل النماذج التحليلية أو التنبؤية أكثر دقة وكفاءة.
أمثلة على المهام التي يمكن ذكرها:
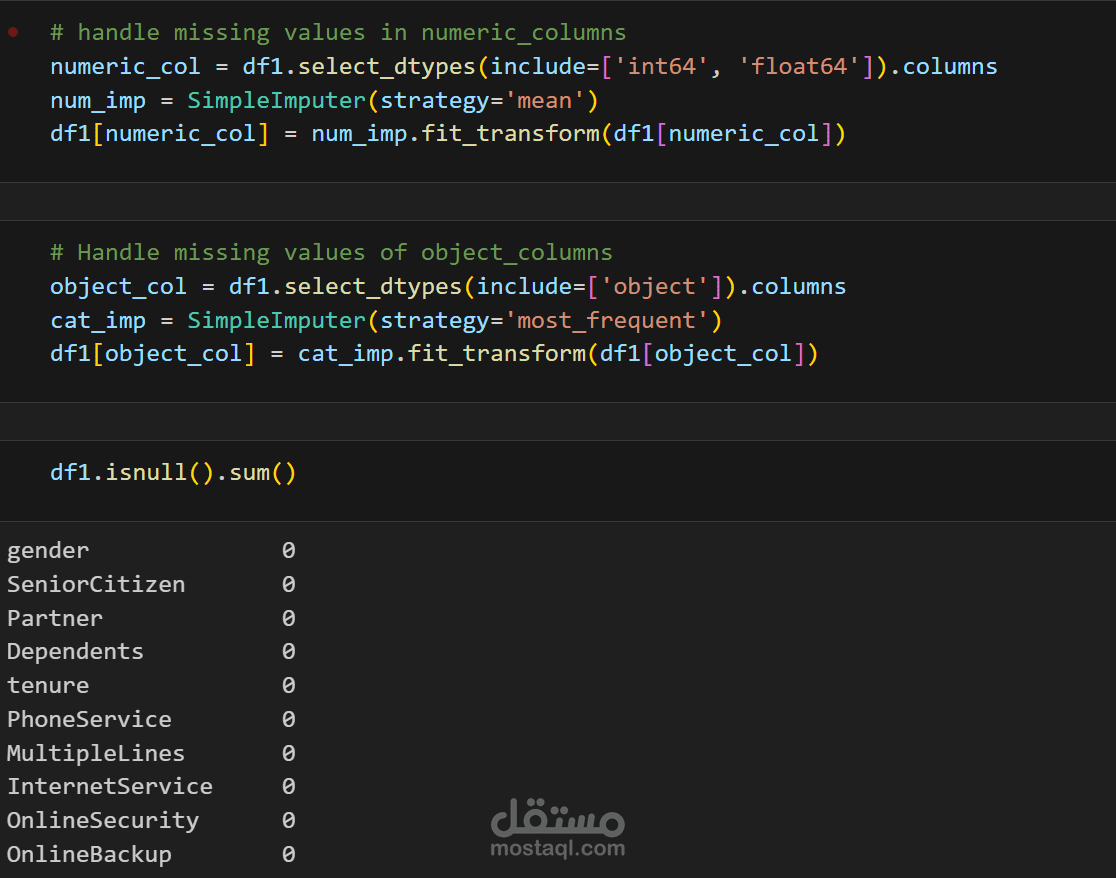
التعامل مع القيم المفقودة (Missing Values) باستخدام تقنيات مثل التعديل، الحذف، أو التقدير الإحصائي.
تحويل البيانات إلى تنسيق مناسب للتحليل (Data Formatting & Transformation).
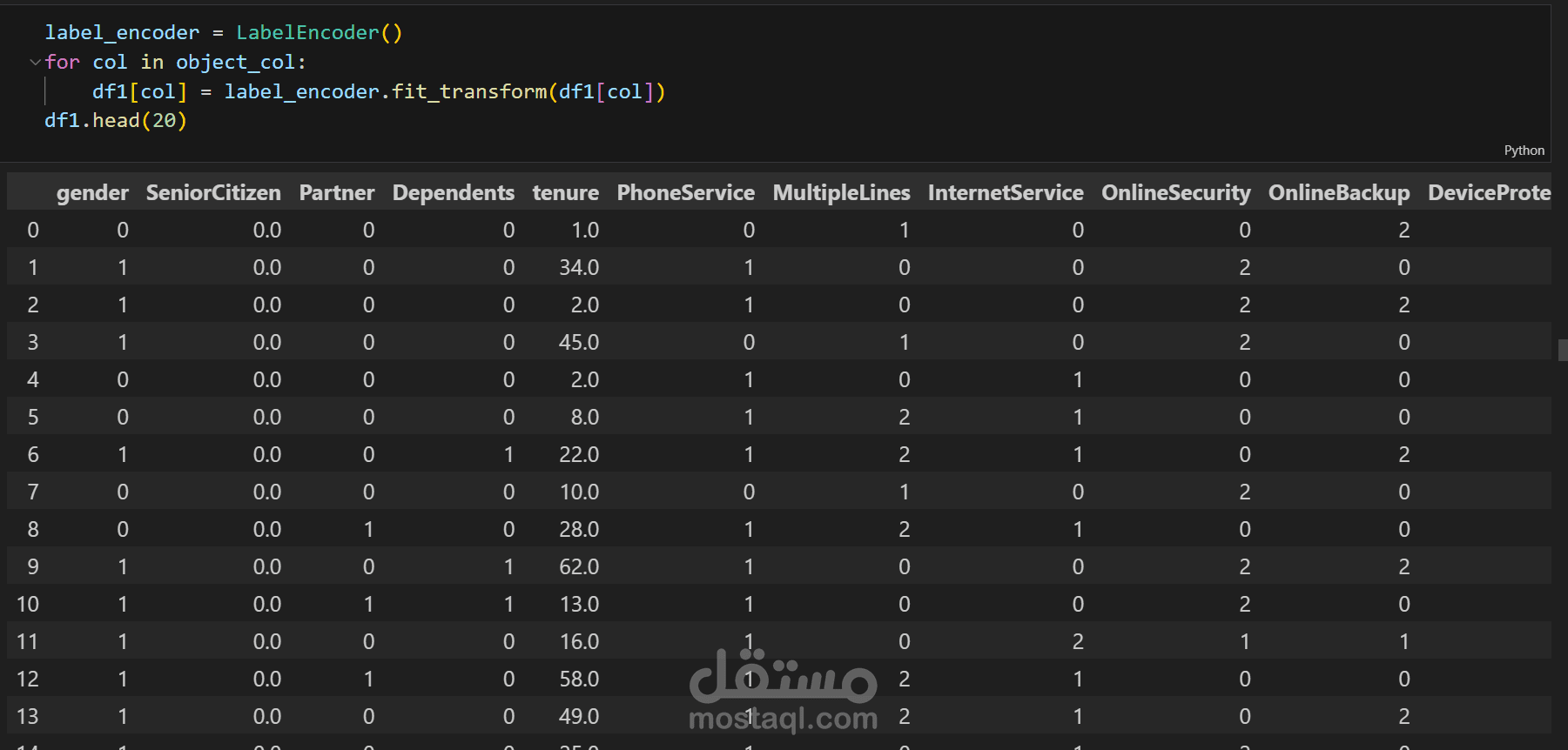
ترميز المتغيرات النوعية باستخدام Label Encoding أو One-Hot Encoding.
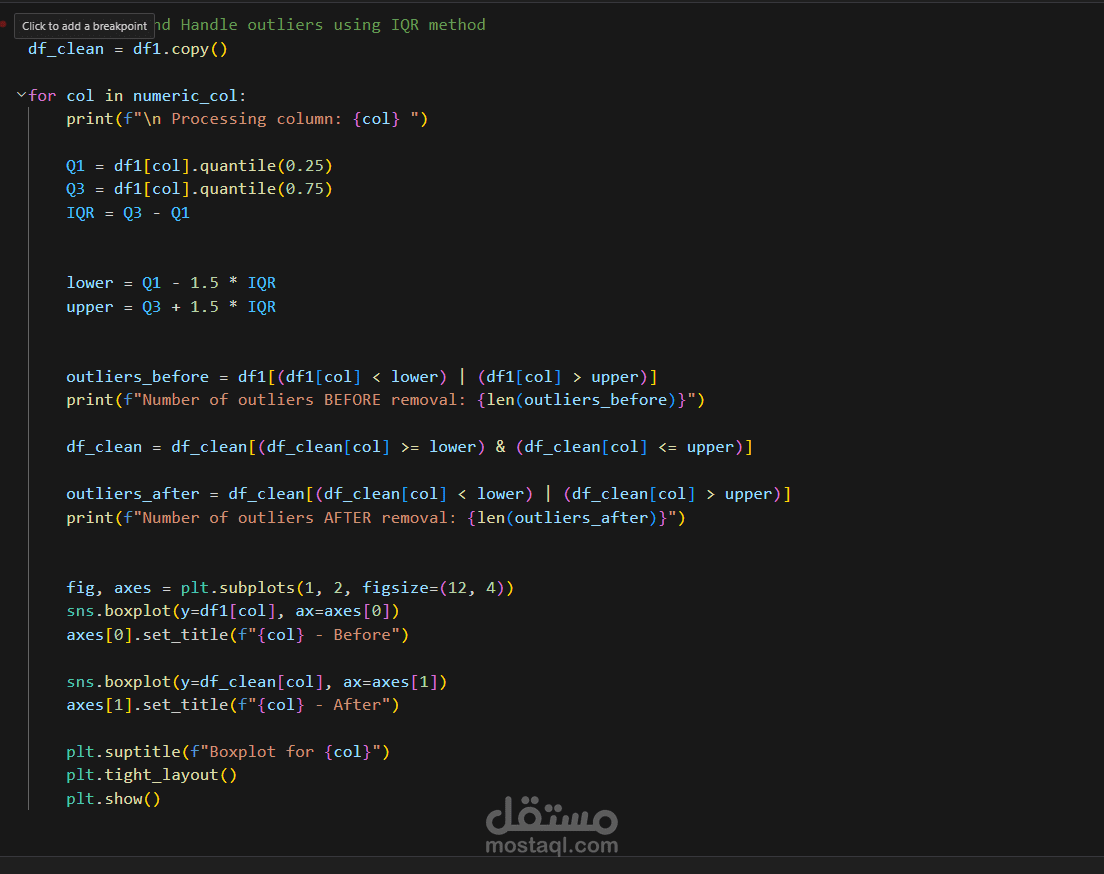
اكتشاف القيم الشاذة (Outliers) باستخدام طرق مثل IQR أو Z-score ومعالجتها.
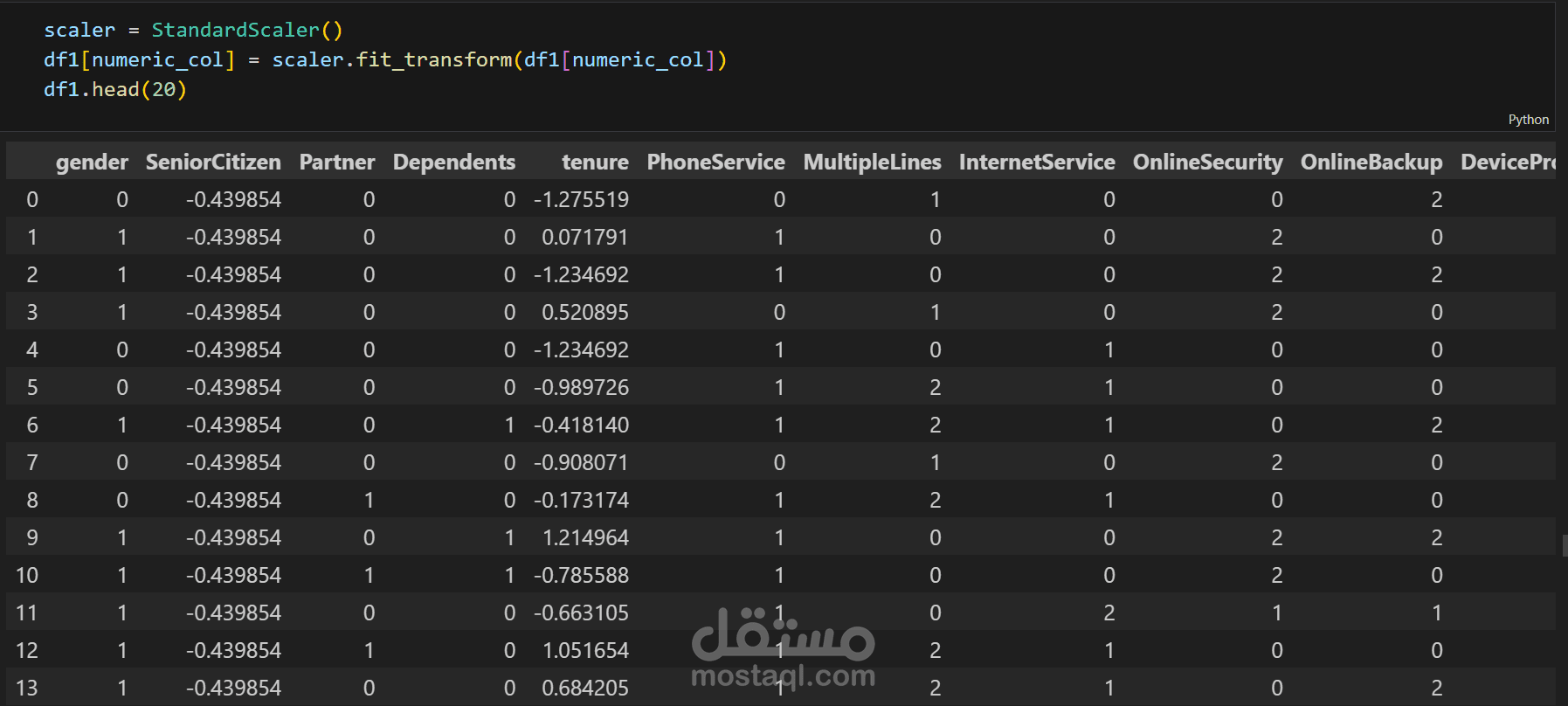
توحيد المقياس (Feature Scaling) باستخدام Standardization أو MinMax Scaling.
تنظيف النصوص في مشاريع NLP، مثل إزالة التكرار، علامات الترقيم، أو الكلمات الشائعة (stopwords).
استخدام أدوات مثل Pandas و NumPy و Scikit-learn بكفاءة عالية.