استخراج النصوص من بطاقة الهوية والتعرف على البيانات المزيفة
تفاصيل العمل

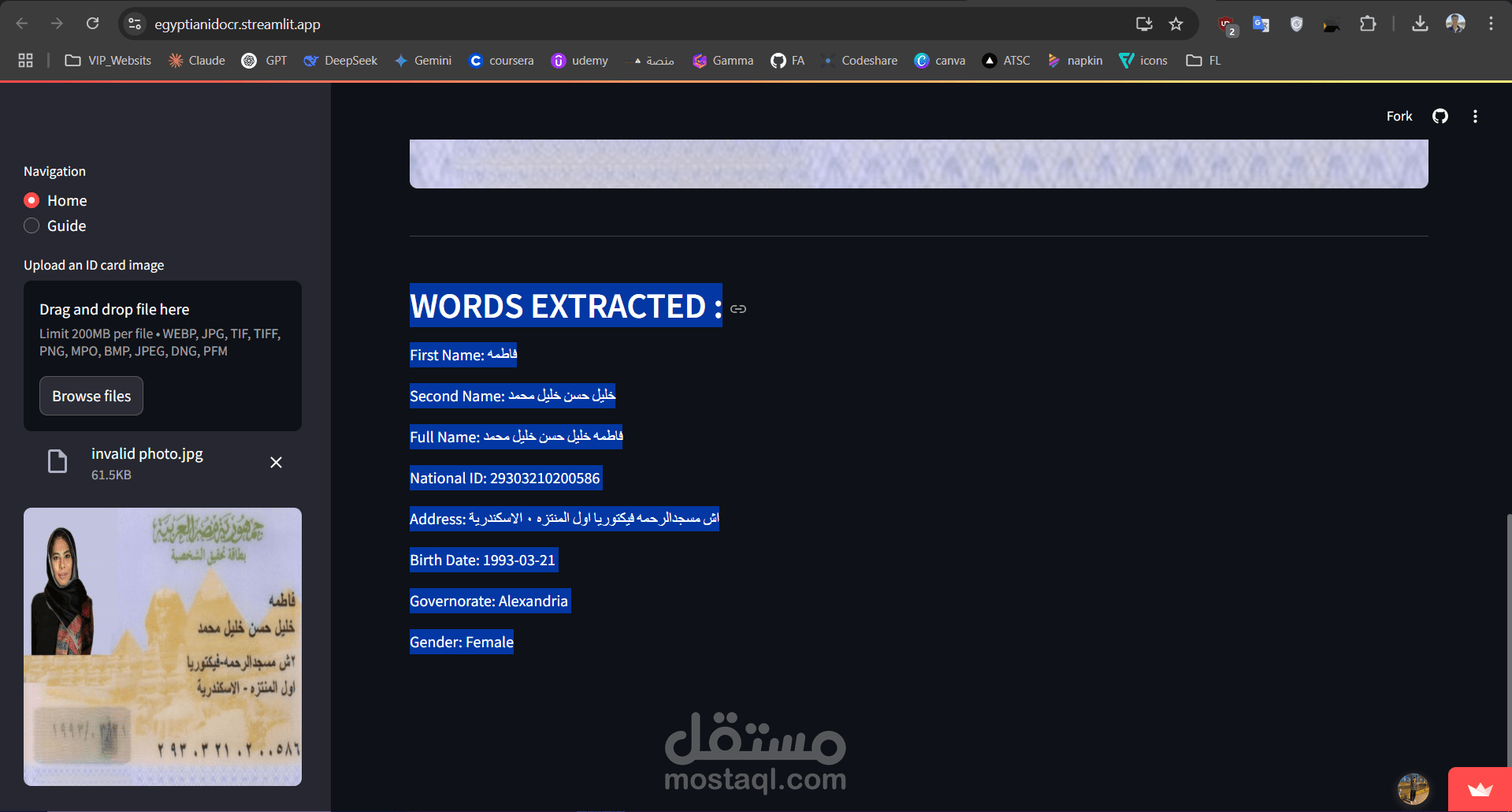
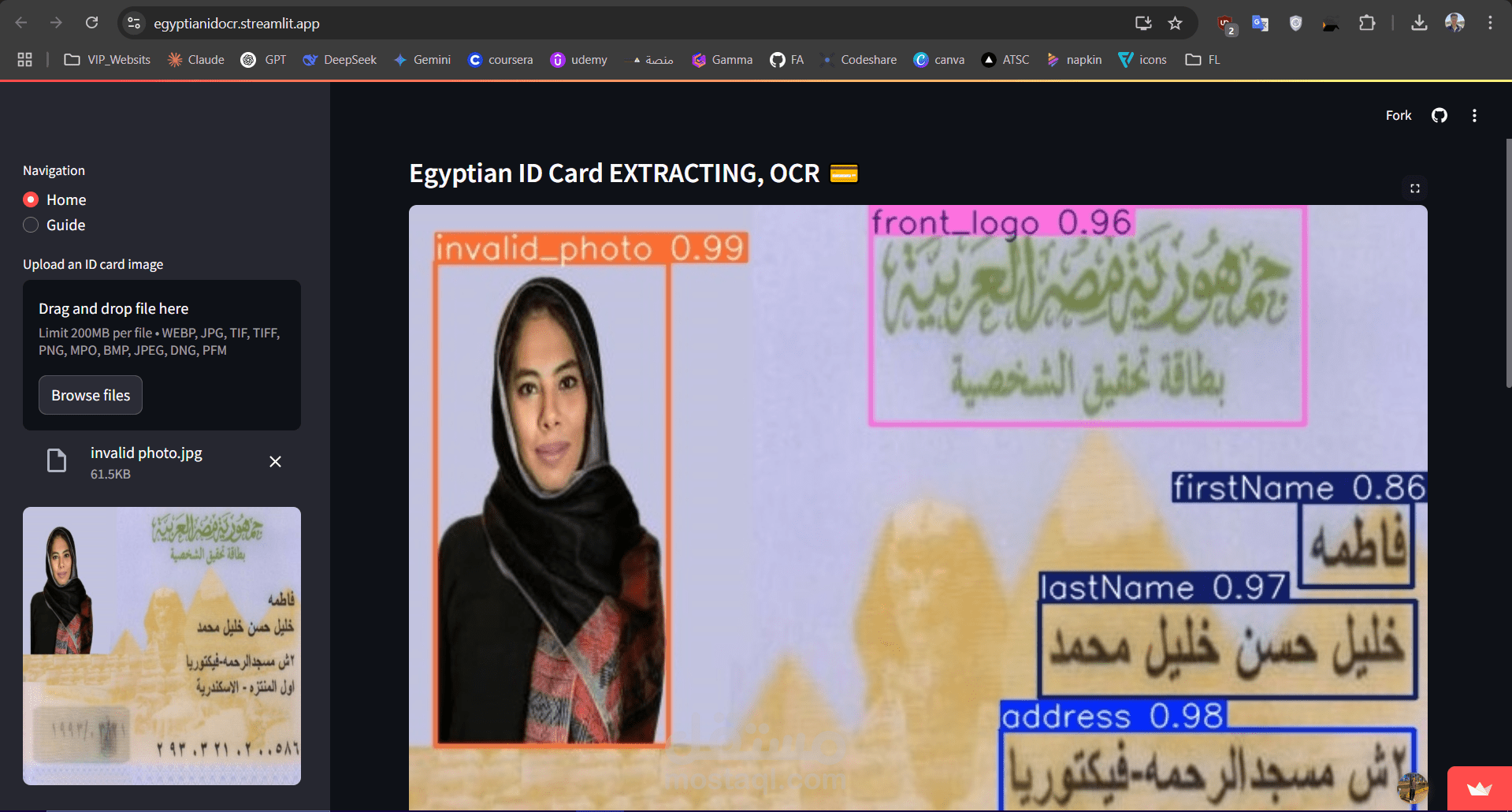
نظام لاستخراج النصوص من بطاقة الرقم القومي المصري باستخدام تقنيات التعرف الضوئي على الحروف (OCR). الهدف من المشروع كان تحسين طريقة استخراج البيانات من بطاقات الهوية بشكل دقيق وسريع باستخدام الذكاء الاصطناعي.
في هذا المشروع، استخدمت تقنيات OCR مثل Tesseract أو EasyOCR لاستخراج النصوص من صورة البطاقة. بعد استخراج النصوص، كان من المهم التأكد من صحتها، فعملت على إضافة آلية للتحقق من تطابق المعلومات مثل الأرقام والأسماء مع القوالب الخاصة بالبطاقات.
قمت أيضاً بتحسين جودة الصورة قبل استخراج النصوص، مثل تعديل التباين أو إزالة الضوضاء، مما ساعد على زيادة دقة عملية التعرف على النص. بالإضافة إلى ذلك، كان المشروع يعتمد على بعض تقنيات تعلم الآلة لتحسين الدقة، وفي بعض الحالات قد تم استخدام الشبكات العصبية لتصنيف النصوص المستخرجة.
من حيث واجهة المستخدم، قمت بتطوير واجهة تفاعلية باستخدام Streamlit لعرض نتائج OCR بشكل مباشر وسهل الاستخدام. الفكرة كانت أن تكون العملية سلسة للمستخدم، حيث يمكن تحميل صورة البطاقة والحصول على البيانات المستخرجة فوراً.
المشروع له العديد من التطبيقات المهمة مثل التحقق من الهوية، رقمنة الوثائق، ومكافحة التزوير. من خلال استخدام الذكاء الاصطناعي، قدمت حلاً مبتكراً لتحويل البطاقات الورقية إلى بيانات رقمية يمكن استخدامها بسهولة في الأنظمة المختلفة.