تحليل البيانات لسرطان الثدي
تفاصيل العمل
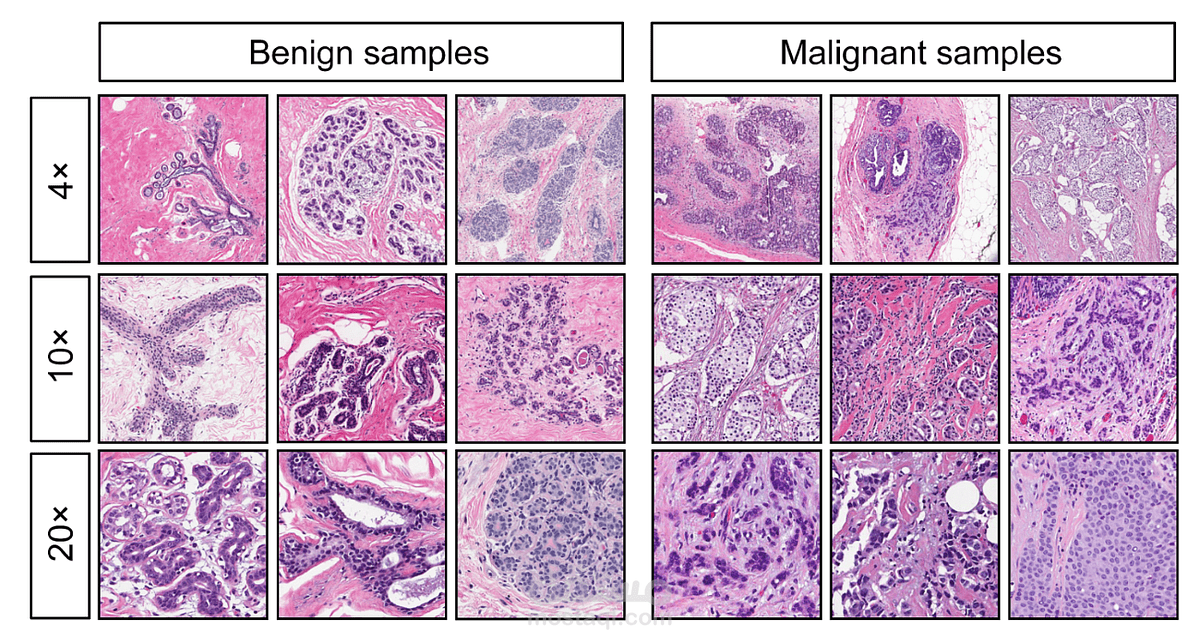
1. جمع البيانات
مصدر البيانات:
مجموعة بيانات سرطان الثدي Wisconsin (التي يمكن الحصول عليها من مكتبة Scikit-learn أو مواقع أخرى مثل Kaggle أو UCI Machine Learning Repository).
محتوى البيانات:
الميزات: قياسات مختلفة للخلايا (مثل القطر، الملمس، الشكل).
الهدف: تصنيف الأورام إلى حميدة (Benign) أو خبيثة (Malignant).
2. معالجة البيانات
التنظيف:
التحقق من القيم المفقودة أو غير الصحيحة ومعالجتها.
إزالة السمات الزائدة أو المكررة.
تحويل البيانات:
توحيد الميزات العددية باستخدام تقنيات مثل StandardScaler.
تشفير البيانات الفئوية (إذا لزم الأمر).
تقليل الأبعاد:
استخدام تقنيات مثل PCA لتقليل عدد الميزات مع الحفاظ على المعلومات الأساسية.
3. تحليل البيانات الاستكشافي (EDA)
التحليل الإحصائي:
حساب المتوسط، الوسيط، والانحراف المعياري لكل ميزة.
تحديد الميزات الأكثر ارتباطًا بالتصنيف.
التصور:
استخدام الرسوم البيانية مثل Box Plots، Scatter Plots، وCorrelation Heatmaps لفهم العلاقات بين الميزات.
استخدام الرسوم البيانية ثنائية الأبعاد أو ثلاثية الأبعاد (مثل PCA) لفهم توزيع البيانات.
4. بناء النماذج
اختيار النموذج:
النماذج الشائعة المستخدمة تشمل:
Logistic Regression.
Decision Trees وRandom Forest.
Support Vector Machines (SVM).
Neural Networks.
التدريب:
تقسيم البيانات إلى مجموعات تدريب واختبار.
تدريب النموذج على مجموعة التدريب باستخدام الميزات المختارة.
ضبط المعلمات:
استخدام Grid Search أو Random Search لاختيار أفضل معلمات للنموذج.
5. التقييم
المقاييس:
الدقة (Accuracy).
Precision وRecall.
F1-score.
ROC-AUC لتقييم الأداء العام للنموذج.
التأكد من التوازن:
معالجة مشكلة عدم توازن البيانات (إذا كانت الفئات غير متساوية) باستخدام Oversampling أو Undersampling.
6. النشر والتفسير
نشر النموذج:
بناء واجهة مستخدم (UI) أو API للسماح للأطباء أو الباحثين باستخدام النموذج.
التفسير:
استخدام تقنيات مثل SHAP أو LIME لفهم تأثير الميزات على تصنيف الأورام.
تقديم تقارير واضحة وسهلة الفهم للأطباء والمستخدمين.
7. الاعتبارات الأخلاقية
خصوصية البيانات:
ضمان حماية بيانات المرضى وامتثالها للوائح الخصوصية (مثل HIPAA).
تقليل التحيز:
ضمان أن يكون النموذج عادلًا لجميع الفئات السكانية.
8. الأدوات والمكتبات
تحليل البيانات: Pandas، NumPy.
التصور: Matplotlib، Seaborn.
التعلم الآلي: Scikit-learn، TensorFlow، PyTorch.
ضبط النماذج: GridSearchCV، Optuna.
الأهداف والنتائج
تحسين دقة التشخيص لتقليل الأخطاء الطبية.
تقديم أداة مساعدة للأطباء لاتخاذ قرارات مبنية على البيانات.
دعم أبحاث السرطان من خلال اكتشاف الأنماط المهمة في البيانات.