استخراج النصوص من الموقع إلى pdf باستخدام python
تفاصيل العمل
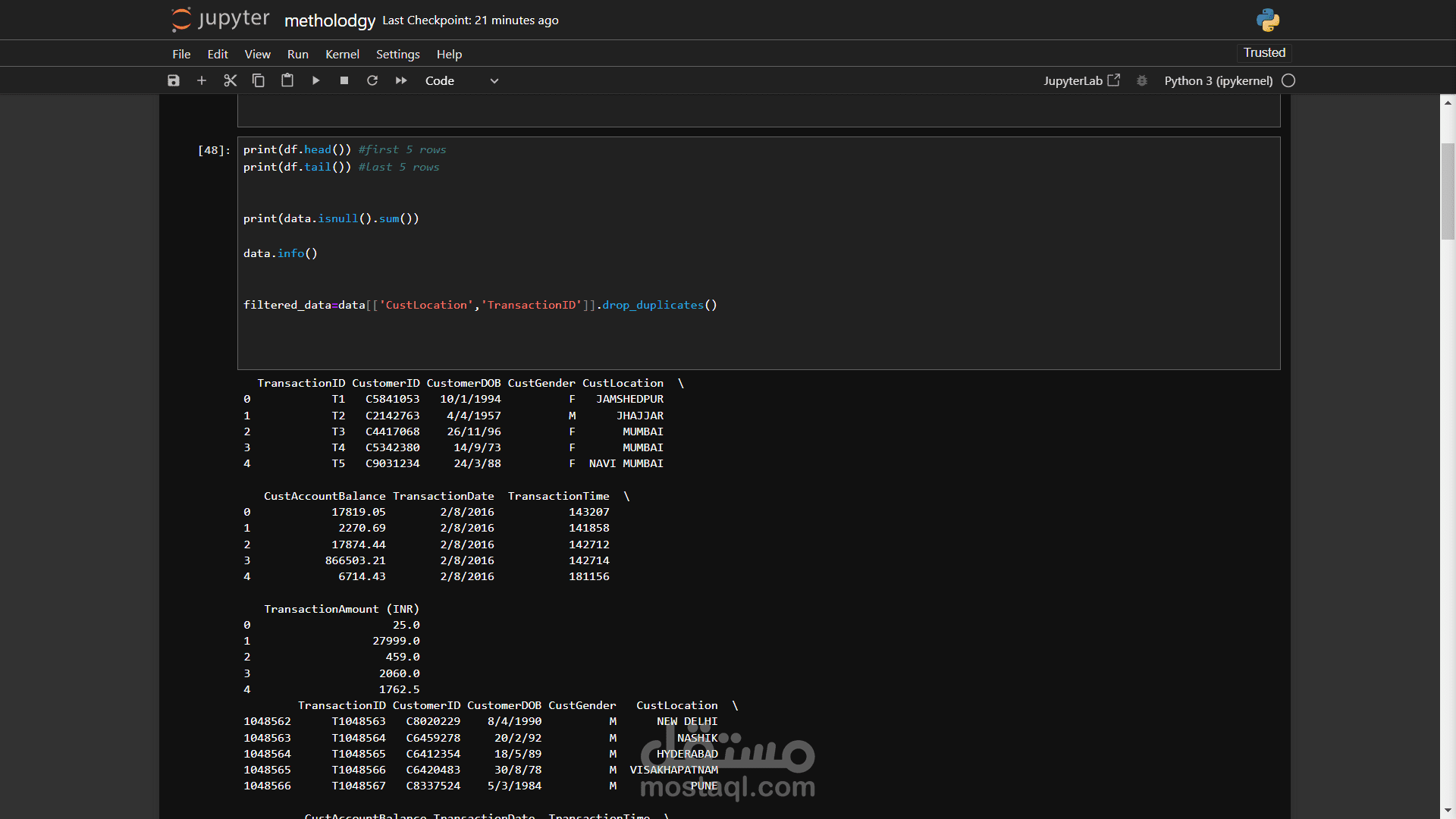
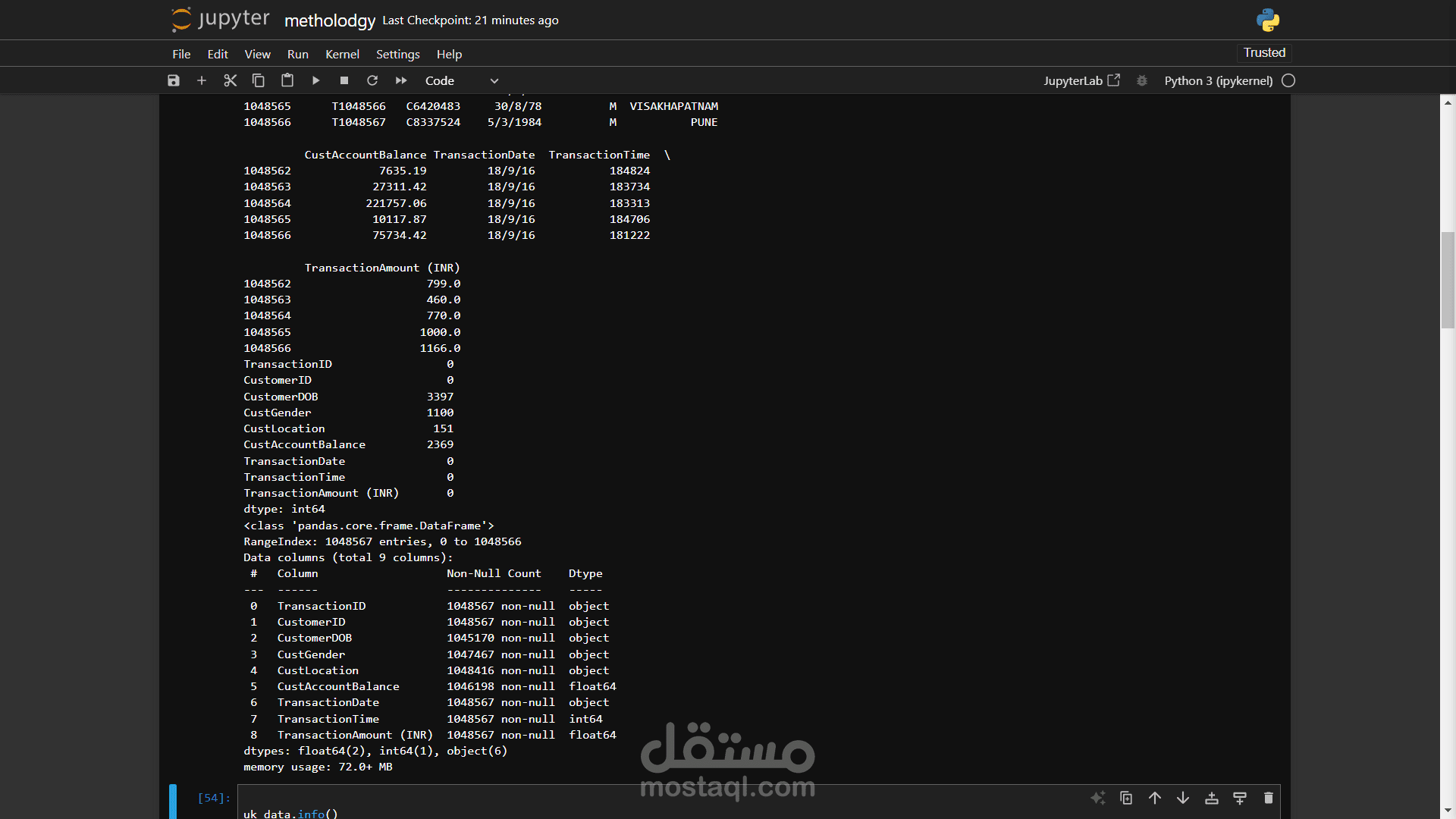
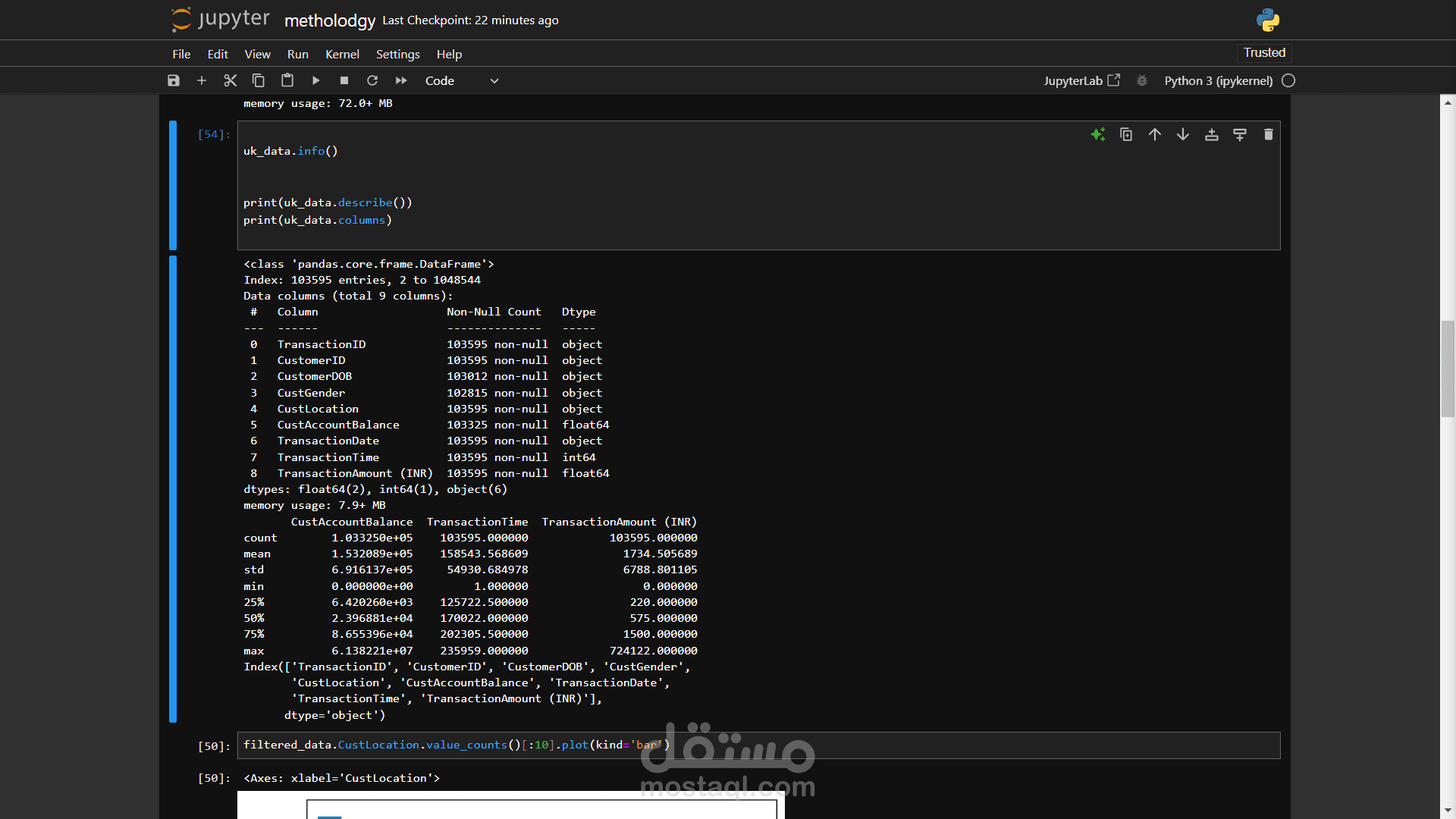
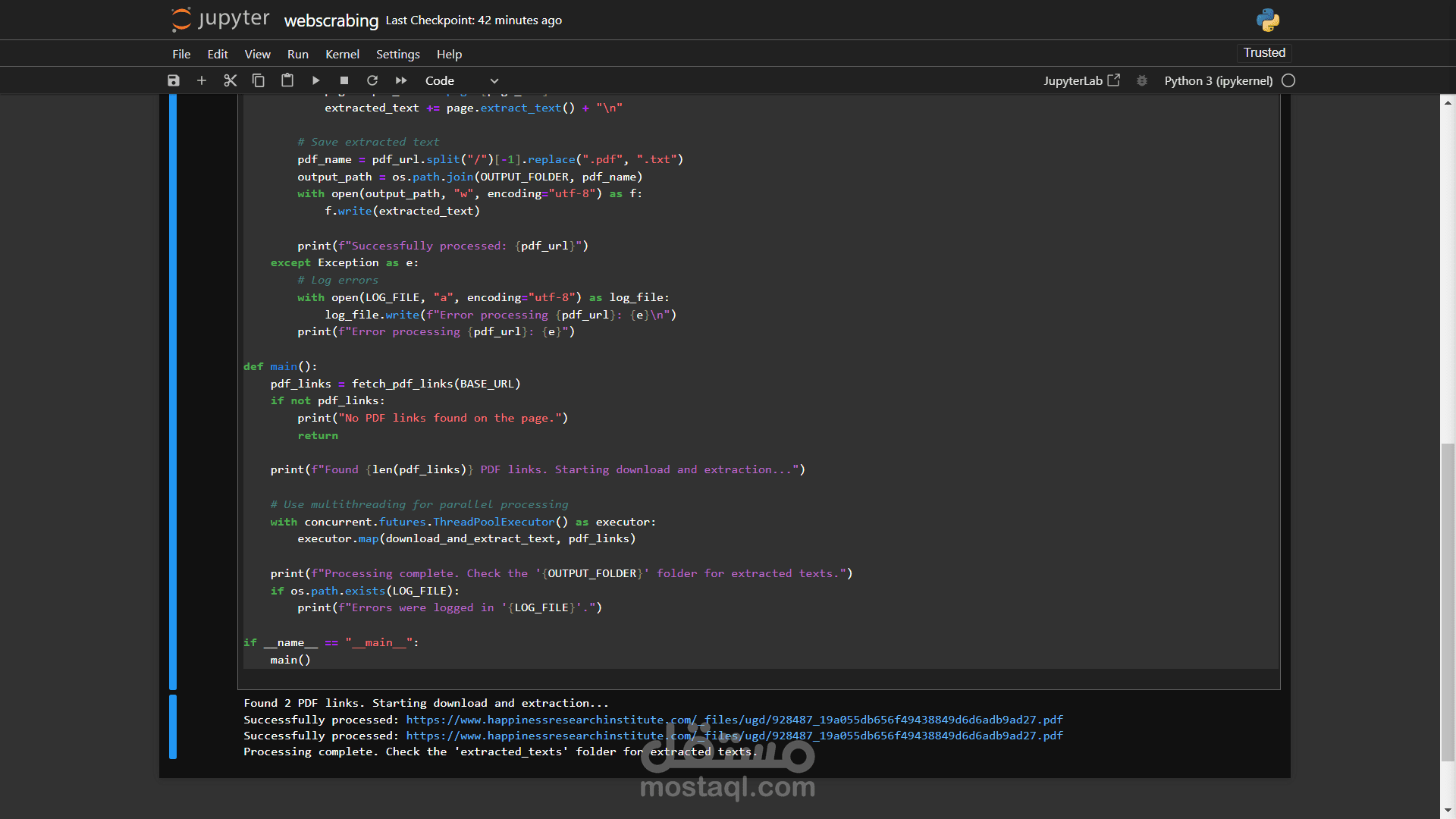
هذا المشروع يهدف إلى أتمتة عملية تحميل ملفات PDF من موقع ويب معين (مثل موقع معهد السعادة للأبحاث) واستخراج النصوص منها بكفاءة عالية. يعتمد المشروع على مكتبة Python متعددة المهام لتحسين الأداء وتقليل وقت التنفيذ، مع الاهتمام بالتعامل مع الأخطاء وتوثيقها.
تفاصيل المشروع:
جمع الروابط:
يتم استخراج جميع روابط ملفات PDF من الصفحة الرئيسية باستخدام مكتبة BeautifulSoup.
تحميل ملفات PDF:
يتم تحميل ملفات PDF من الروابط المستخرجة باستخدام مكتبة requests.
يتم التعامل مع الأخطاء مثل الروابط غير الصالحة أو فشل الاتصال.
استخراج النصوص:
يتم استخراج النصوص من صفحات ملفات PDF باستخدام مكتبة PyPDF2.
النصوص المستخرجة تحفظ كملفات نصية (.txt) منظمة في مجلد محدد.
المعالجة المتوازية:
لتحسين الأداء، يتم استخدام مكتبة concurrent.futures لتحميل واستخراج النصوص من ملفات متعددة في وقت واحد.
التعامل مع الأخطاء:
يتم تسجيل جميع الأخطاء أثناء المعالجة (مثل الملفات التالفة أو مشاكل التحميل) في ملف سجل (error_log.txt) لمراجعتها لاحقًا.
الإخراج النهائي:
النصوص المستخرجة تحفظ في مجلد يسمى extracted_texts.
تقرير الأخطاء متاح في ملف error_log.txt عند الحاجة.
فوائد المشروع:
أتمتة المهام المتكررة والمملة.
تحسين الكفاءة باستخدام المعالجة المتوازية.
إنشاء تقارير تفصيلية عن الأخطاء لمتابعة الجودة.
مرونة في التعامل مع أي موقع ويب يحتوي على ملفات PDF.