Text Classification using LSTM
تفاصيل العمل
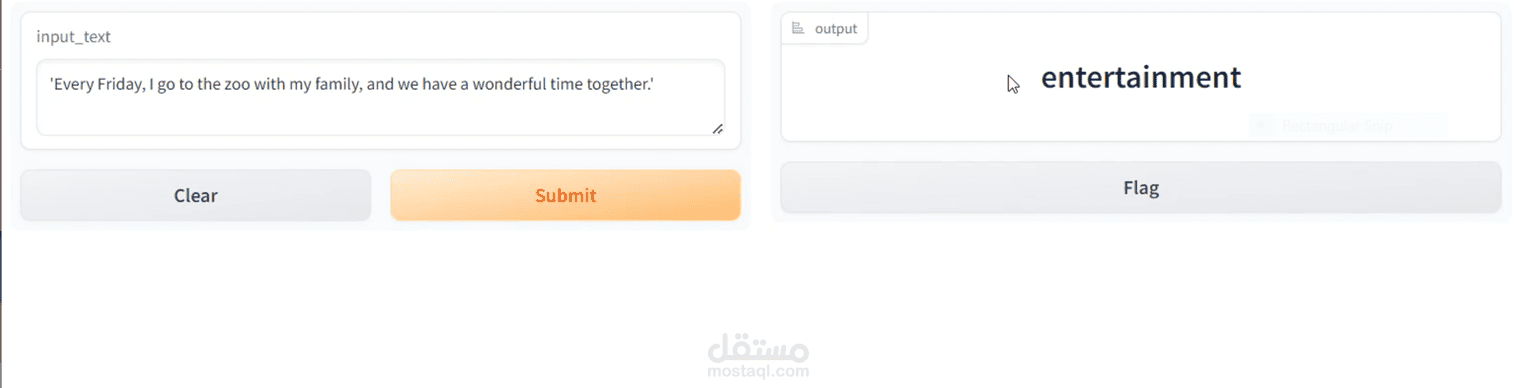
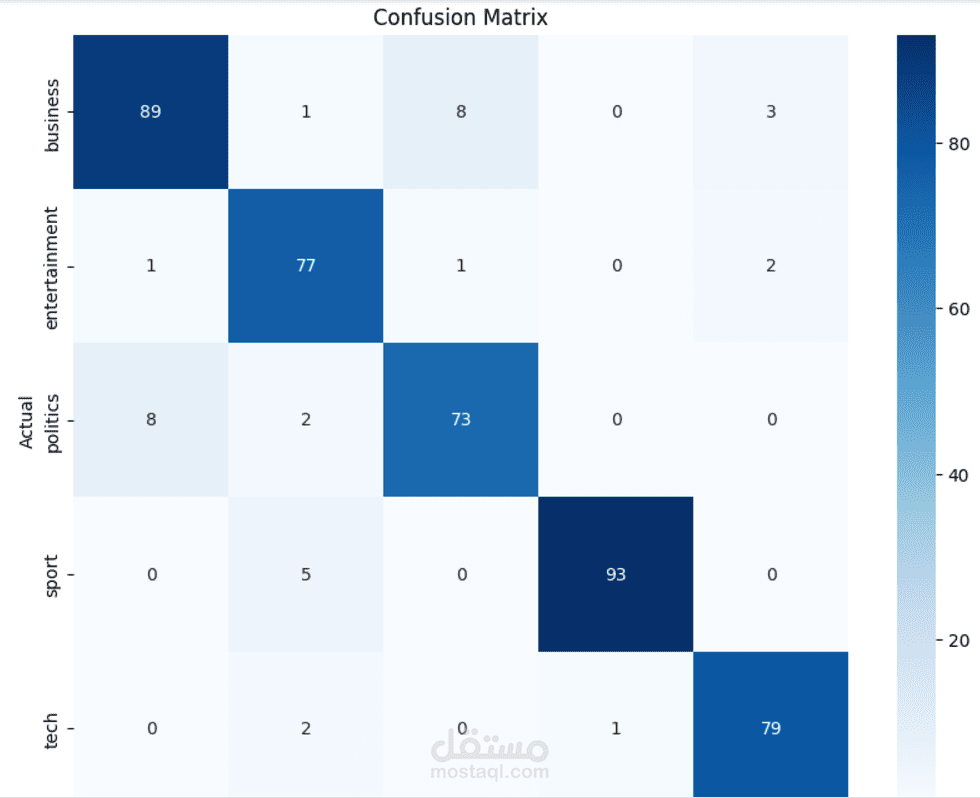
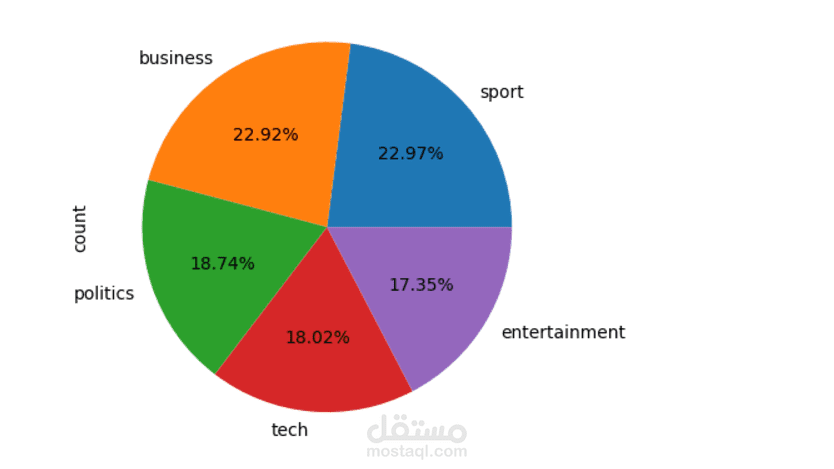
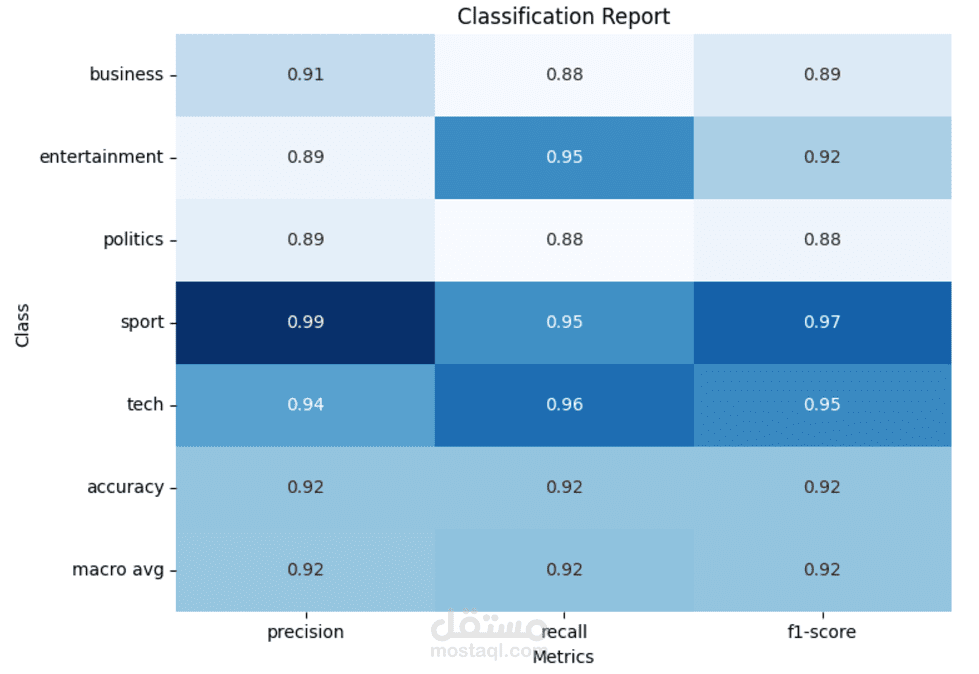
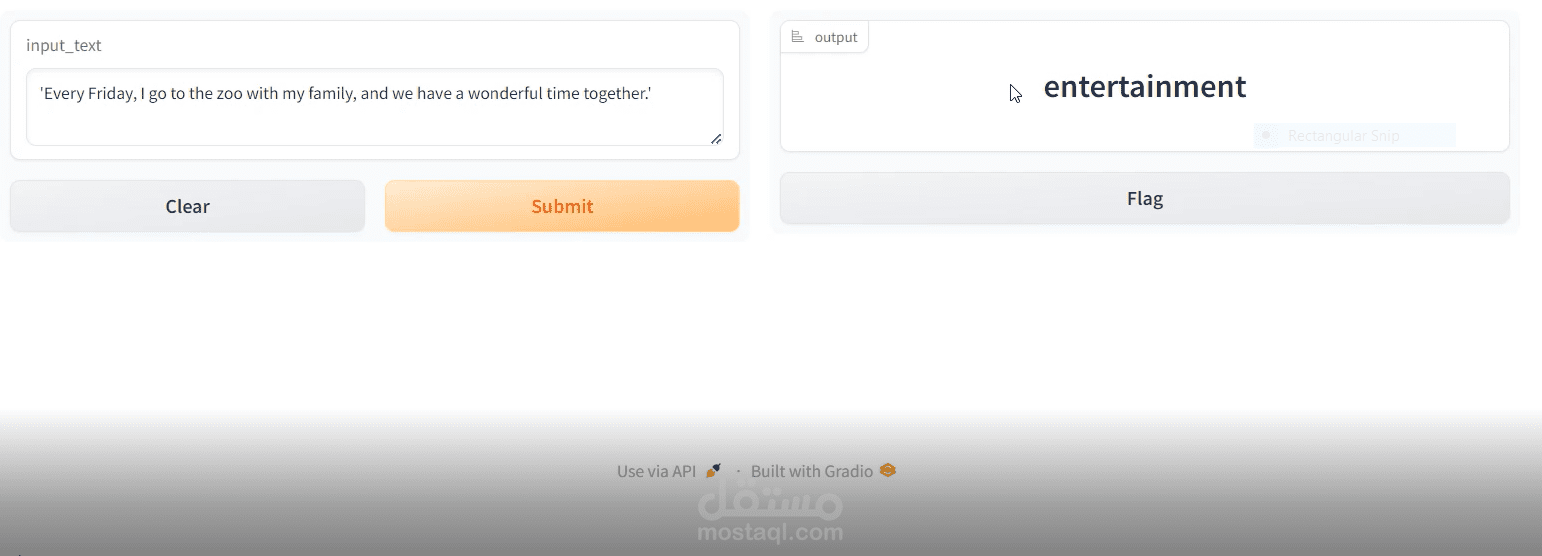
تم بناء نموذج ذكاء اصطناعي يعتمد على الشبكات العصبية المتكررة (LSTM) لتصنيف النصوص بدقة عالية. يهدف المشروع إلى تحليل وتصنيف النصوص بناءً على محتواها إلى فئات محددة (مثل: تحليل المشاعر، تصنيف الأخبار، أو أي نوع آخر من التصنيفات النصية).
تفاصيل العمل:
البيانات:
تم استخدام مجموعة بيانات [bbc] التي تحتوي على 2225 عينة موزعة على 5 classes.
معالجة البيانات النصية باستخدام تقنيات مثل إزالة التكرار، التصفية، وتحويل النصوص إلى أرقام باستخدام أدوات مثل Tokenizer و Word Embeddings (GloVe ).
التقنيات المستخدمة:
بناء الشبكة العصبية باستخدام مكتبة TensorFlow/Keras.
طبقات LSTM مخصصة لمعالجة البيانات النصية بتسلسل زمني وتحسين دقة التنبؤ.
تطبيق Dropout لتقليل مشكلة الإفراط في التعميم (Overfitting).
استخدام طبقة Dense مع وظيفة تفعيل Softmax .
نتائج المشروع:
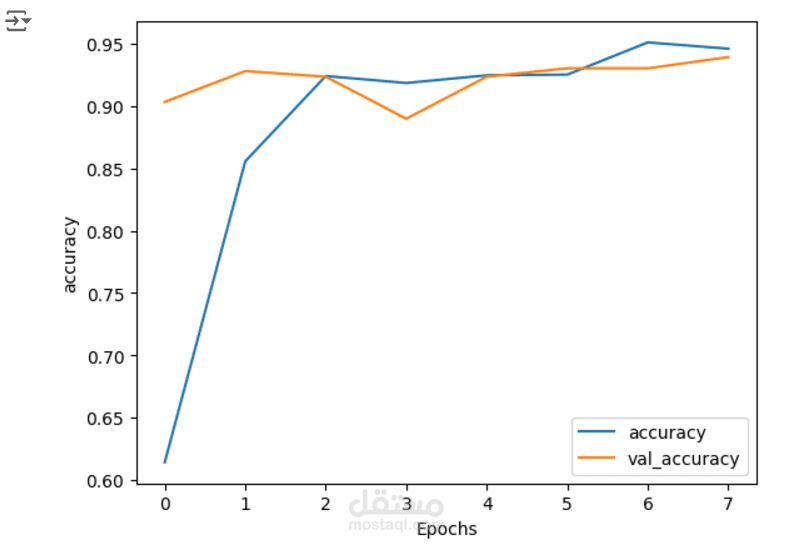
دقة النموذج: 95% على مجموعة الاختبار.
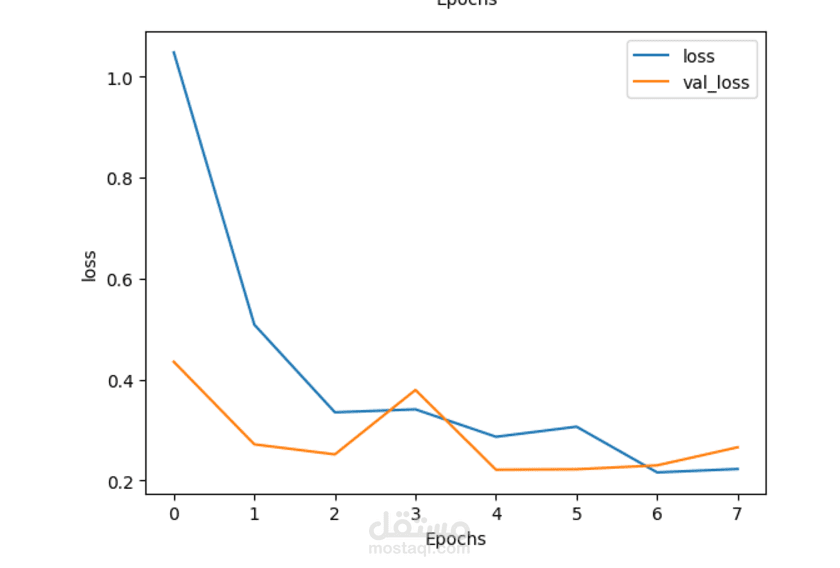
تحسين الأداء من خلال معايرة البيانات، واستخدام تقنيات مثل Early Stopping وتخفيض معدل التعلم (Learning Rate Scheduling).
الأدوات واللغات المستخدمة:
لغة البرمجة: Python
مكتبات: TensorFlow, Keras, NumPy, Pandas
بيئة العمل: Google Colab
أبرز التحديات:
معالجة النصوص بشكل فعال للتعامل مع التعقيد والتنوع في البيانات النصية.
التغلب على مشكلة توازن البيانات وتحسين أداء النموذج.
نتائج العمل النهائية:
تم تسليم نموذج جاهز للعمل يمكنه تصنيف النصوص بدقة مع توفير واجهة تفاعلية للاختبار، مما يساعد العملاء على تحليل النصوص بطريقة أسرع وأكثر كفاءة.