مُتنبئ المتبرعين الخيريين والرؤى (Charity Donor Predictor and Insights)
تفاصيل العمل

مشروع "مُتنبئ المتبرعين الخيريين"
وصف المشروع:
يهدف هذا المشروع إلى التنبؤ بما إذا كان الأفراد يكسبون أكثر من 50 ألف دولار سنويًا، مما يساعد الجمعيات الخيرية في تحديد المتبرعين المحتملين. يتم استخدام تقنيات التعلم الآلي لتحليل البيانات الديموغرافية للأفراد وتحديد أولئك الذين قد يكونون من المتبرعين المحتملين. هذا يمكن المنظمات من تحسين استراتيجيات جمع التبرعات وزيادة فاعليتها.
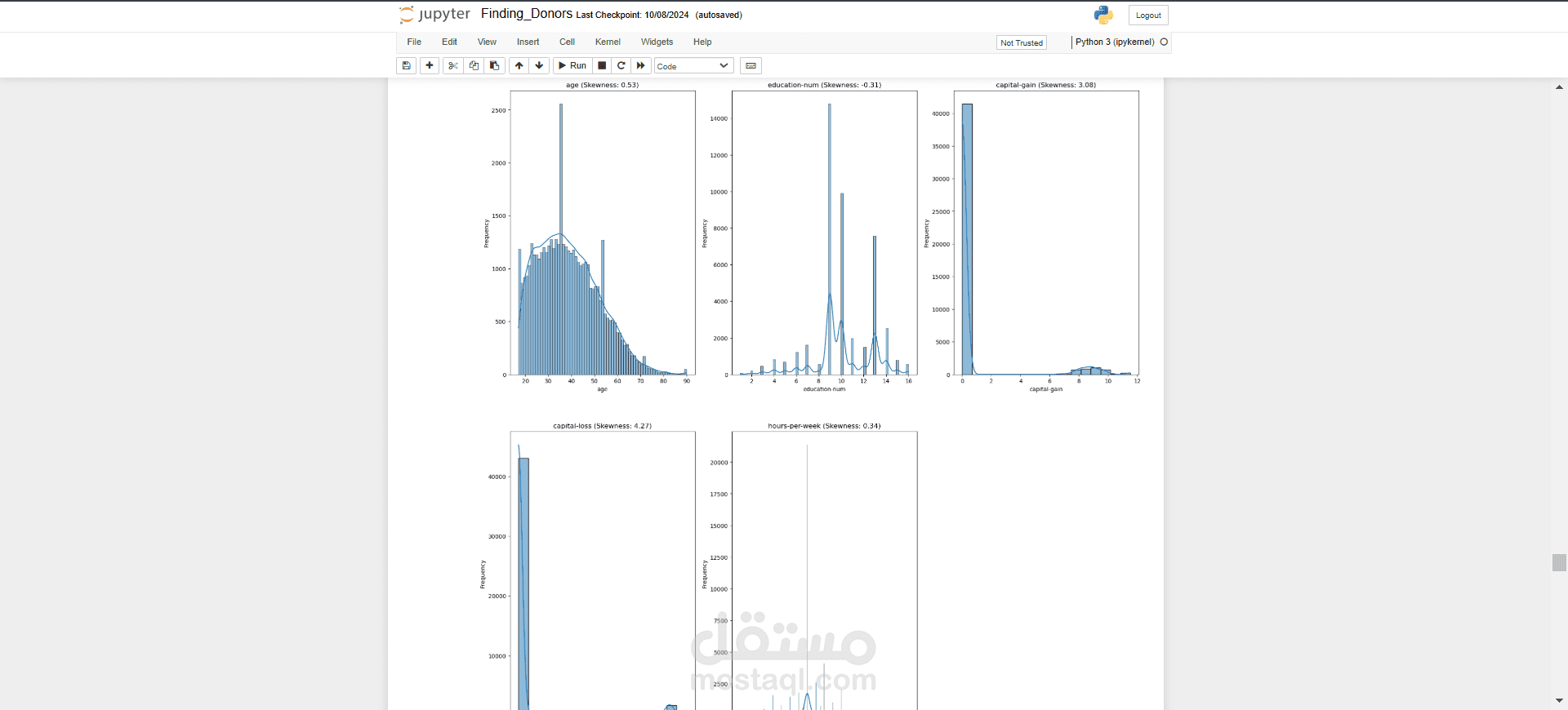
1. استكشاف البيانات (EDA - Exploratory Data Analysis):
بدأ المشروع بتحليل البيانات لفهم هيكلها. تم استخدام Python مع مكتبات Pandas و Seaborn و Matplotlib لعرض التوزيعات والأنماط في البيانات. الهدف كان معرفة الأنماط والاتجاهات الرئيسية للأفراد الذين يكسبون أكثر من 50 ألف دولار.
2. تنظيف البيانات والتحضير (Data Cleaning & Preprocessing):
تم تنظيف البيانات وتنسيقها لتكون جاهزة للتحليل. شملت هذه المرحلة:
- معالجة القيم المفقودة باستخدام تقنيات مثل الإزالة أو الاستبدال.
- تنسيق عمود الدخل لتحويل القيم من "<=50" و ">50" إلى 0 و 1 باستخدام Pandas.
- إزالة المسافات البيضاء من الأعمدة النصية باستخدام Python.
- الترميز الأحادي (One-hot Encoding) لتحويل المتغيرات الفئوية إلى قيم رقمية.
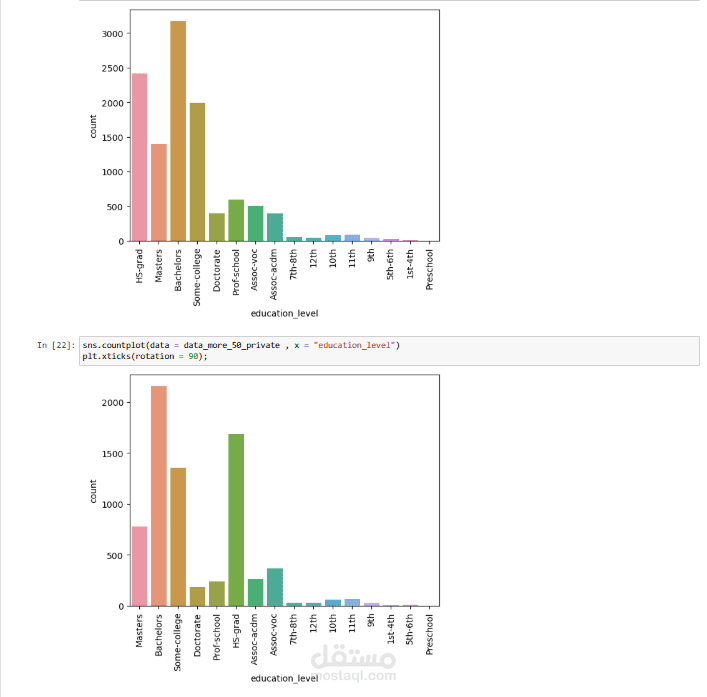
3. تحليل البيانات والرؤى (Data Analysis and Insights):
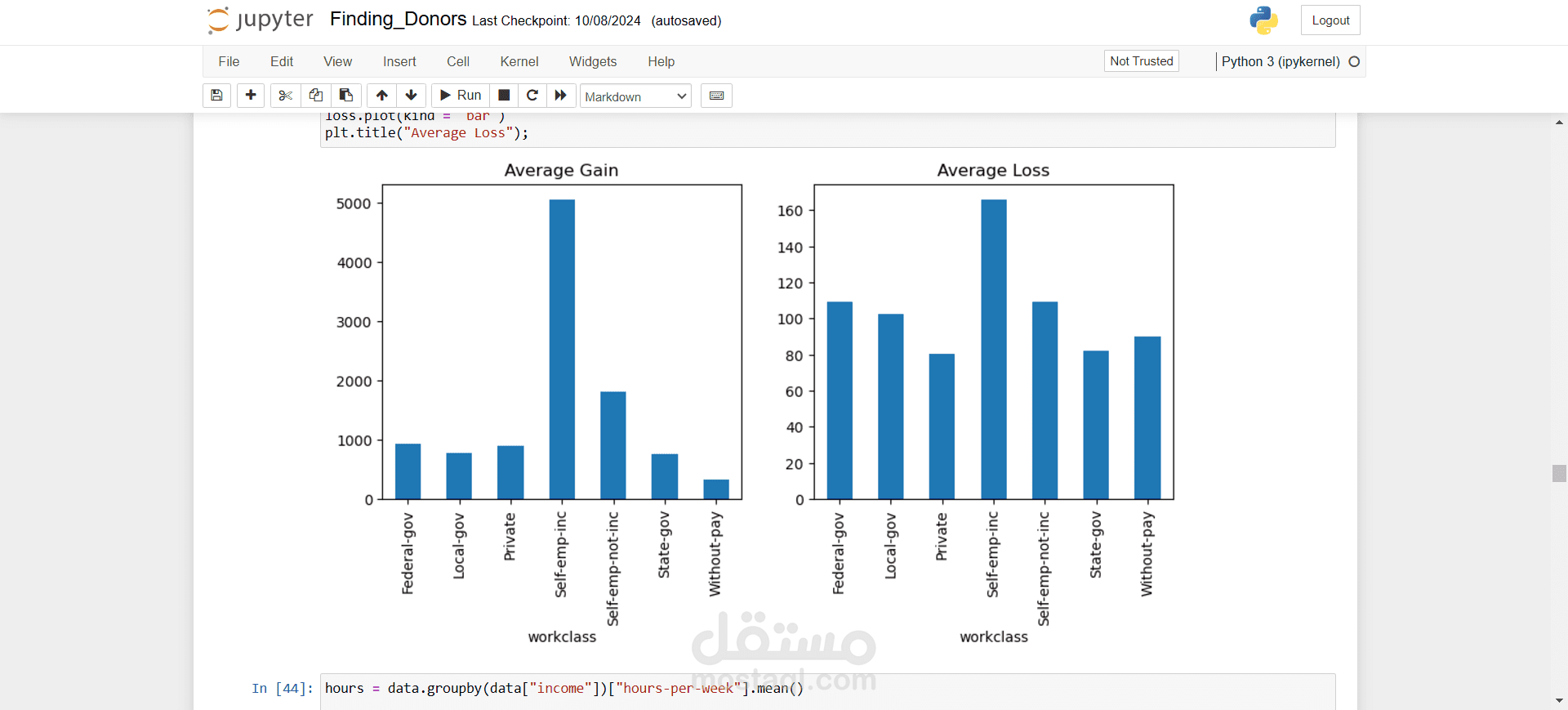
تم تحليل البيانات لاستخراج رؤى قيمة. على سبيل المثال:
- العمر المتوسط للأفراد الذين يكسبون أكثر من 50 ألف دولار كان 44 سنة.
- فئة العمل الأكثر شيوعًا كانت القطاع الخاص، بينما الأقل شيوعًا كانت "بدون أجر" (متقاعدون عادة).
4. التحضير للنمذجة (Data Preparation for Modeling):
في هذه المرحلة، تم إعداد البيانات لاستخدامها في النمذجة:
- تطبيق مقياس Min-Max لتطبيع البيانات.
- تقسيم البيانات إلى مجموعات تدريب واختبار باستخدام Scikit-learn.
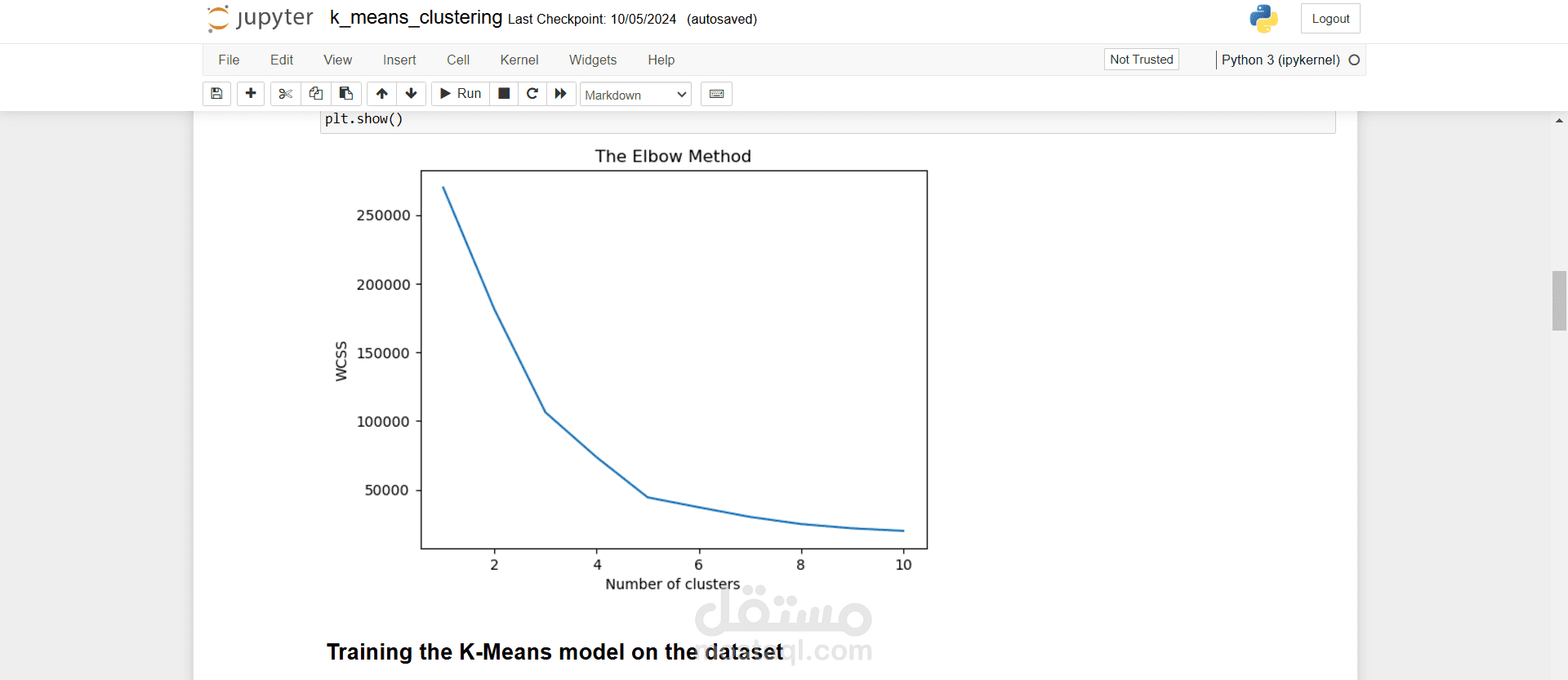
- استخدام KMeans للتكتل وتحسين دقة النموذج، مع تحديد العدد المثالي من العناقيد باستخدام طريقة Elbow.
5. اختيار النموذج وضبطه (Model Selection and Tuning):
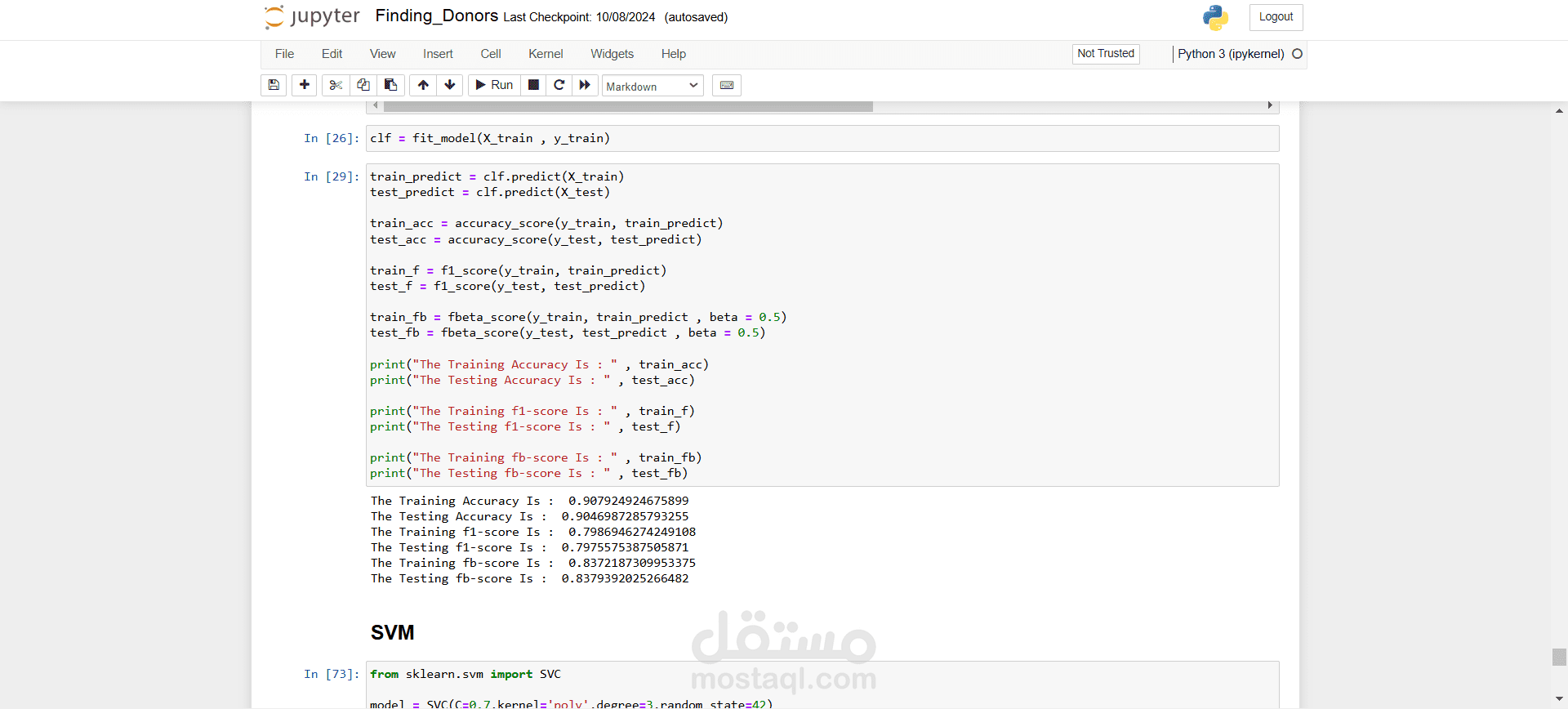
تم اختبار أربعة نماذج للتعلم الآلي:
- Decision Tree: تم استخدام Scikit-learn. دقة الاختبار كانت 89.08%.
- AdaBoost (أفضل نموذج): دقة الاختبار كانت 90.47% ودرجة F1 كانت 79.76%. تم استخدام Scikit-learn لضبط النموذج.
- SVM (Poly Kernel) و SVM (RBF Kernel) تم استخدامهما لاختبار أدائهما في تصنيف البيانات.
6. التقنيات المستخدمة:
- تحليل البيانات والتصور:
Pandas، Numpy، Matplotlib، Seaborn.
- التعلم الآلي:
Decision Tree، AdaBoost، SVM (Poly Kernel، RBF Kernel).
- التكتل (Clustering):
KMeans.
- تقييم النموذج:
Cross-validation، GridSearch لتحديد أفضل المعلمات للنماذج.
7. النموذج النهائي:
تم اختيار AdaBoost كأفضل نموذج نظراً لدقته العالية ودرجة F1 الممتازة في تحديد المتبرعين المحتملين. تم استخدام Scikit-learn لتنفيذ النموذج وضبط المعلمات.
ملفات مرفقة
بطاقة العمل
| اسم المستقل | مازن ا. |
| عدد الإعجابات | 0 |
| عدد المشاهدات | 7 |
| تاريخ الإضافة | |
| تاريخ الإنجاز |